文章目录
- 第1章 实时需求概览
- 1.1 实时需求与离线需求的比较
- 1.2 数仓架构设计
- 1.2.1 离线
- image-20210120115453007
- 1.2.2 实时
- 1.3 本项目主要需求
- 1.3.1 当日用户首次登录(日活)分时趋势图,昨日对比
- 1.3.2 当日新增付费用户(首单)分析(ods+dwd)
- 1.3.3 订单明细实付金额分摊以及交易额统计(dws)
- 1.3.4 ADS聚合及可视化(ads)
- 第2章 项目数据准备
- 2.1 模拟日志生成器的使用
- 2.2 开发SpringBoot程序gmall0421-logger,采集模拟生成的日志数据
- 2.2.1 创建空的父工程gmall0421-parent,用于管理后续所有的模块module
- 2.2.2 搭建一个SprintBoot项目,作为采集日志服务器
- 2.2.3 在Spring程序中,借助Logbak将采集的日志落盘
- 2.2.4 在Spring程序中,将采集到的日志数据发送到kafka
- 将gmall0421-logger打包到单台Linux上运行
- 2.3 搭建日志采集集群,并通过Nginx进行反向代理
- 第3章 附录1:SpringBoot知识点
- 3.1 Springboot简介
- 3.2 有了springboot 我们就可以…
- 3.3 springboot和ssm的关系
- 3.4 没有xml,我们要去哪配置
- 第4章 附录2:Nginx
- 4.1 Nginx简介
- 4.2 正向代理和反向代理概念
- 4.3 Nginx安装以及相关命令
- 4.4 Nginx核心配置文件说明
- 4.4.1 基本配置
- 4.4.2 events配置
- 4.4.3 http配置
- 4.5 Nginx主要应用
- 4.5.1 静态网站部署
- 4.5.2 负载均衡
- 4.5.3 静态代理
- 4.5.4 动静分离
- 4.5.5 虚拟主机
第1章 实时需求概览
1.1 实时需求与离线需求的比较
- 离线需求
就是在计算开始前已知所有输入数据,输入数据不会产生变化,一般计算量级较大,计算时间也较长。例如今天早上一点,把昨天累积的日志,计算出所需结果。最经典的就是Hadoop的MapReduce方式;
一般是根据前一日的数据生成报表,虽然统计指标、报表繁多,但是对时效性不敏感。
- 实时需求
输入数据是可以以序列化的方式一个个输入并进行处理的,也就是说在开始的时候并不需要知道所有的输入数据。与离线计算相比,运行时间短,计算量级相对较小。强调计算过程的时间要短,即所查当下给出结果。
主要侧重于对当日数据的实时监控,通常业务逻辑相对离线需求简单一下,统计指标也少一些,但是更注重数据的时效性,以及用户的交互性。
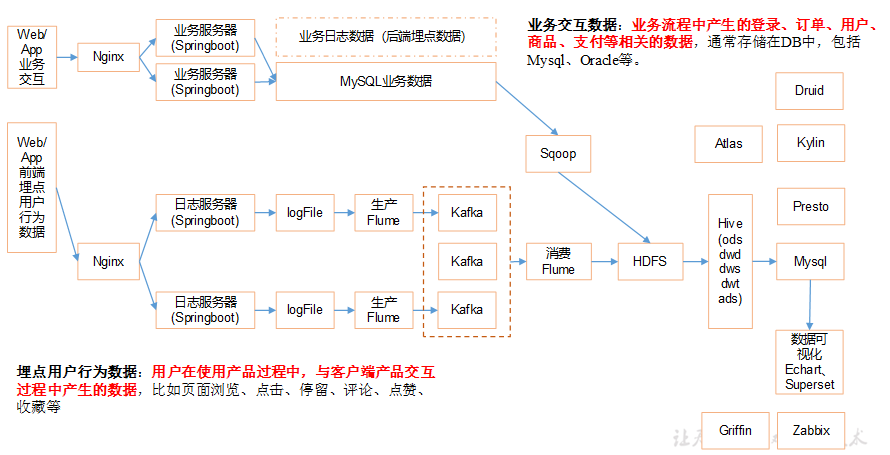
1.2 数仓架构设计
1.2.1 离线
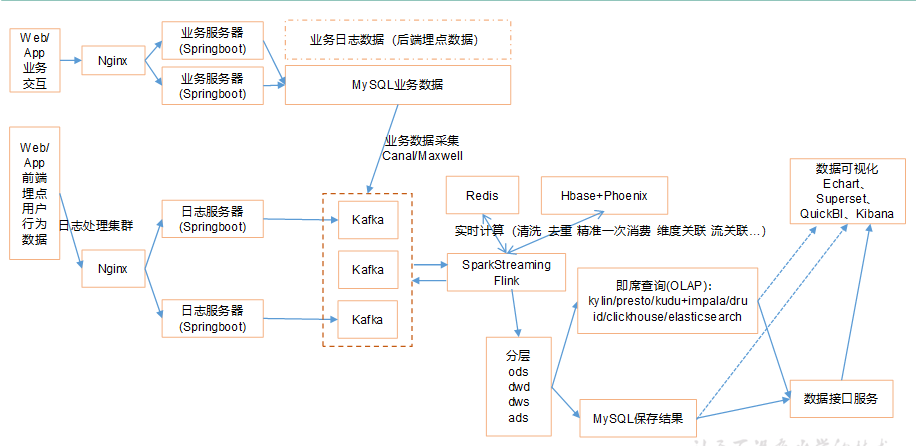
1.2.2 实时
1.3 本项目主要需求
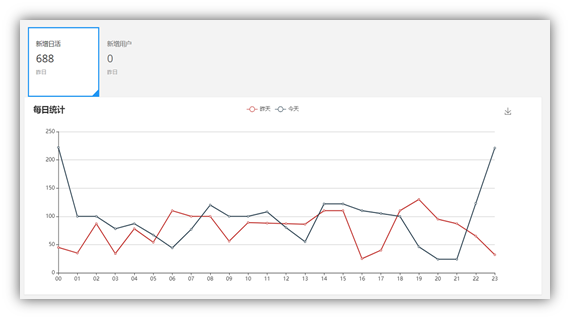
1.3.1 当日用户首次登录(日活)分时趋势图,昨日对比
从项目的日志中获取用户的启动日志,如果是当日第一次启动,纳入统计。将统计结果保存到ES中,利用Kibana进行分析展示
1.3.2 当日新增付费用户(首单)分析(ods+dwd)
按省份|用户性别|用户年龄段,统计当日新增付费用户首单平均消费及人数占比;无论是省份名称、用户性别、用户年龄,订单表中都没有这些字段,需要订单(事实表)和维度表(省份、用户)进行关联,形成宽表后将数据写入到ES,通过Kibana进行分析以及图形展示。
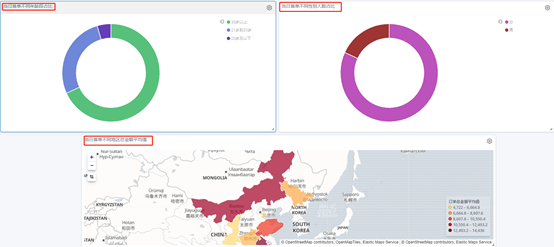
1.3.3 订单明细实付金额分摊以及交易额统计(dws)
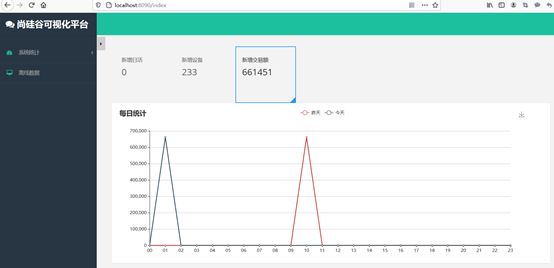
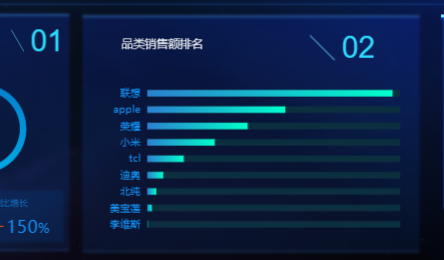
1.3.4 ADS聚合及可视化(ads)
我们以热门品牌统计为案例
第2章 项目数据准备
2.1 模拟日志生成器的使用
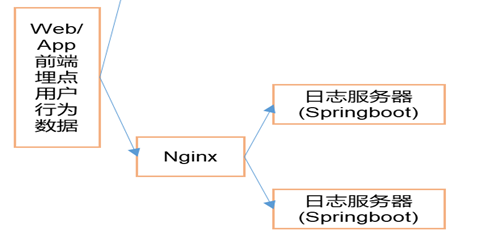
这里模拟日志的思路和采集一样,但是并没有直接将日志生成到文件,而是将日志发送给某一个指定的端口,需要大数据程序员了解流程
(1) 拷贝/资料/01-模拟器(用户行为)内容到hadoop105的/opt/module/rt_applog目录
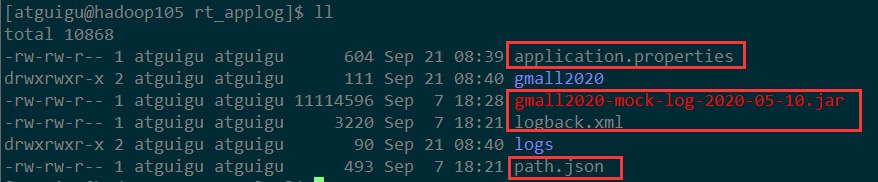
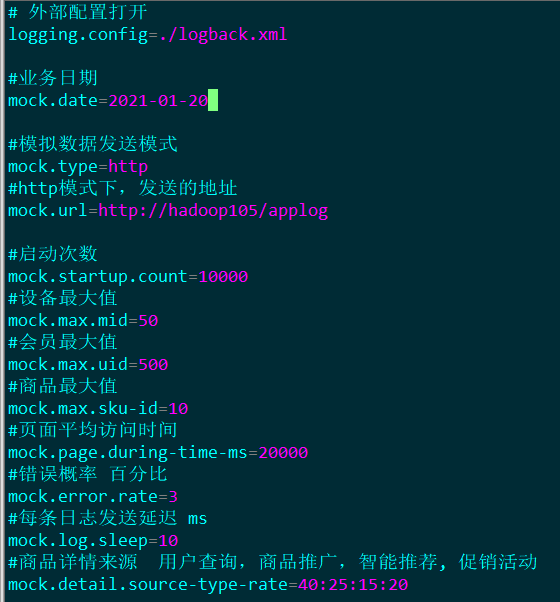
(2) 根据实际需要修改application.properties
(3) 使用模拟日志生成器的jar 运行
[atguigu@hadoop105 rt_applog]$ java -jar gmall2020-mock-log-2020-05-10.jar
(4) 目前我们还没有地址接收日志,所以程序运行后的结果有如下错误
 注意:ZooKeeper从3.5开始,AdminServer的端口也是8080,如果在本机启动了zk,那么可能看到405错误,意思是找到请求地址了,但是接收的方式不对。
注意:ZooKeeper从3.5开始,AdminServer的端口也是8080,如果在本机启动了zk,那么可能看到405错误,意思是找到请求地址了,但是接收的方式不对。
2.2 开发SpringBoot程序gmall0421-logger,采集模拟生成的日志数据
2.2.1 创建空的父工程gmall0421-parent,用于管理后续所有的模块module
我们这里就是为了将各个模块放在一起,但是模块彼此间还是独立的,所以创建一个Empty Project即可;如果要是由父module管理子module,需要将父module的pom.xml文件的设置为pom
2.2.2 搭建一个SprintBoot项目,作为采集日志服务器
(1) 父project下创建创建SprintBoot项目
注意:如果连接不到Springboot服务器,可以手动创建
(2) 配置项目名称gmall0421-logger
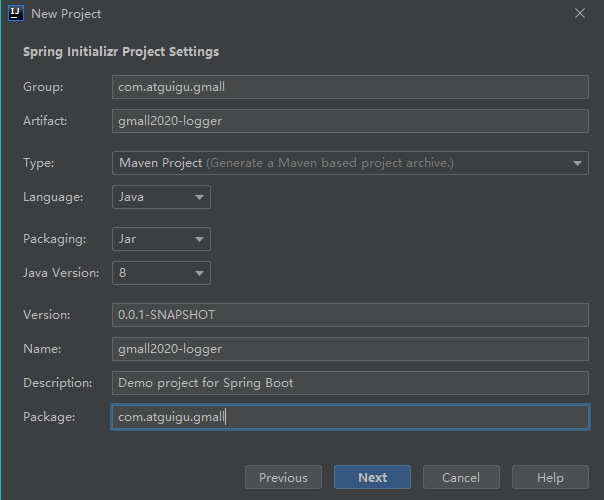
(3) 选择版本以及通过勾选自动添加依赖
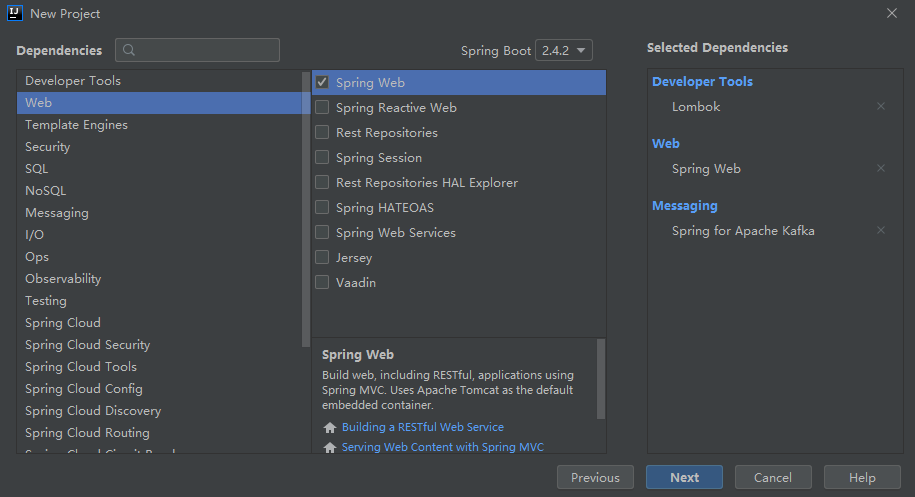
(4) 完成之后开始下载依赖,完整的pom.xml文件如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.3.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.atguigu.gmall</groupId><artifactId>gmall0421-logger</artifactId><version>0.0.1-SNAPSHOT</version><name>gmall0421-logger</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>(5) 在Idea中安装Lombok插件
(6) 创建LoggerController接收来自/applog的日志
package com.atguigu.gmall.controller;import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;/*** @Package: com.atguigu.gmall.controller* @ClassName: LoggerController* @Author: fengbing* @CreateTime: 2020/9/13 3:07* @Description: 该Controller用于接收模拟生成的日志*///标识为controller组件,交给Sprint容器管理,并接收处理请求 如果返回String,会当作网页进行跳转
//@Controller
// @RestController = @Controller + @ResponseBody 会将返回结果转换为json进行响应@RestController
@Slf4j
public class LoggerController {//通过requestMapping匹配请求并交给方法处理@RequestMapping("/applog")//在模拟数据生成的代码中,我们将数据封装为json,通过post传递给该Controller处理,所以我们通过@RequestBody接收public String applog(@RequestBody String jsonLog) {System.out.println(jsonLog);return jsonLog;}
}(7) 运行Gmall0421LoggerApplication,启动内嵌Tomcat
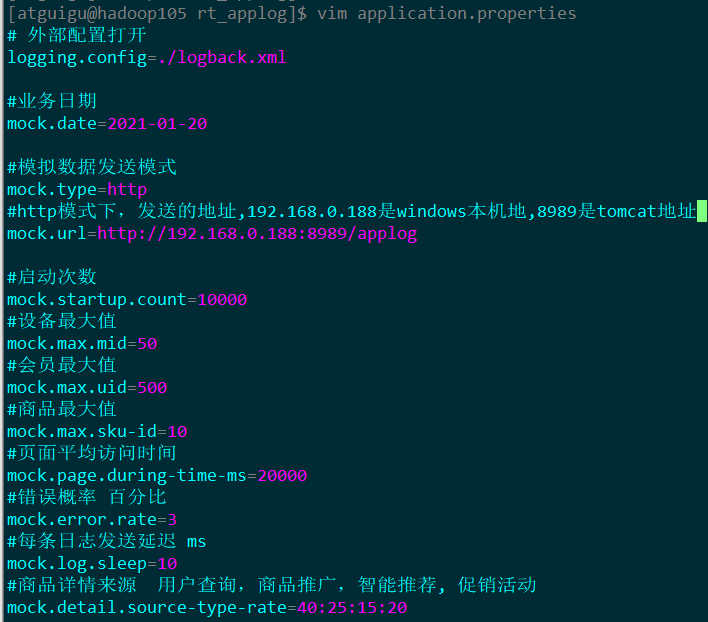
(8) 修改hadoop105上的rt_applog目录下的application.properties,向/applog发送日志
(9) 执行命令,查看hadoop105输出、Idea输出效果
[atguigu@hadoop105 rt_applog]$ java -jar gmall2020-mock-log-2020-05-10.jar
2.2.3 在Spring程序中,借助Logbak将采集的日志落盘
(1) 在LoggerController上加@Slf4j注解,并通过log.info记录日志
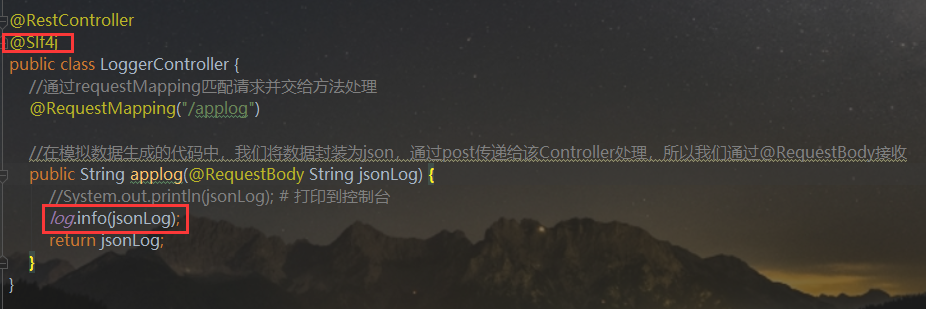
(2) 在gmall0421-logger的resources中添加logback.xml配置文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration><property name="LOG_HOME" value="/opt/module/rt_gmall/gmall0421" /><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>%msg%n</pattern></encoder></appender><appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${LOG_HOME}/app.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern></rollingPolicy><encoder><pattern>%msg%n</pattern></encoder></appender><!-- 将某一个包下日志单独打印日志 --><logger name="com.atguigu.gmall.controller.LoggerController"level="INFO" additivity="false"><appender-ref ref="rollingFile" /><appender-ref ref="console" /></logger><root level="error" additivity="false"><appender-ref ref="console" /></root>
</configuration>(3) logback配置文件说明
- appender
追加器,描述如何写入到文件中(写在哪,格式,文件的切分)
ConsoleAppender–追加到控制台
RollingFileAppender–滚动追加到文件
- logger
控制器,描述如何选择追加器
注意:要是单独为某个类指定的时候,别忘了修改类的全限定名
- 日志级别
TRACE [DEBUG INFO WARN ERROR] FATAL
(4) 启动Gmall0421LoggerApplication 以及运行jar命令查看控制台以及文件输出
(5) 思考:log哪里定义的?
其实在lombok注解@Slf4j底层执行了类似
Logger log = org.slf4j.LoggerFactory.getLogger(LoggerController.class);
(6) 测试:再次启动SpringBoot程序,运行模拟生成日志的jar,查看在控制台和磁盘上都可以看到日志。
2.2.4 在Spring程序中,将采集到的日志数据发送到kafka
整体思路:在gmall0421-logger的controller中接收到数据之后,对日志数据进行分流,根据日志类型(事件|启动),将日志发送到不同的kafka主题中去
(1) 导入spring-kafka依赖
在创建SpringBoot模块的时候,勾选的;如果没有勾选,在pom.xml文件中加如下配置
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>(2) 在pom.xml文件中添加fastjson依赖
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency>
(3) 在gmall0421-logger的application.properties中配置kafka相关信息
#============== kafka ===================
server.port=8989
# 指定kafka 代理地址,可以多个
spring.kafka.bootstrap-servers=hadoop105:9092,hadoop106:9092,hadoop107:9092
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer(4) 将KafkaTemplate注入到Controller中
@RestController
@Slf4j
public class LoggerController {//注入Spring提供的Kafka编程模板@AutowiredKafkaTemplate kafkaTemplate;//通过requestMapping匹配请求并交给方法处理@RequestMapping("/applog")//在模拟数据生成的代码中,我们将数据封装为json,通过post传递给该Controller处理,所以我们通过@RequestBody接收public String applog(@RequestBody String jsonLog) {//System.out.println(jsonLog); # 打印到控制台log.info(jsonLog);return jsonLog;}
}
(5) 对接收到的数据进行分流
//通过requestMapping匹配请求并交给方法处理@RequestMapping("/applog")//在模拟数据生成的代码中,我们将数据封装为json,通过post传递给该Controller处理,所以我们通过@RequestBody接收public String applog(@RequestBody String jsonLog){//将日志落盘*log*.info(jsonLog);//将不同类型日志发送到kafka主题中JSONObject jsonObject = JSON.*parseObject*(jsonLog);if(jsonObject.getJsonObject("start")!=null){//启动日志kafkaTemplate.send("gmall_start_bak",jsonLog);}else{//事件日志kafkaTemplate.send("gmall_event_bak",jsonLog);}return "success";}
(6) 启动zk和Kafka,在Kafka中创建对应的主题
注意:默认情况下,Kafka创建主题默认分区是1个,我这里修改为4个
[atguigu@hadoop105 rt_applog]$ kafka-topics.sh --bootstrap-server hadoop105:9092 --create --topic gmall_start_bak --partitions 4 --replication-factor 3
[atguigu@hadoop105 rt_applog]$ kafka-topics.sh --bootstrap-server hadoop105:9092 --create --topic gmall_event_bak --partitions 4 --replication-factor 3
(7) 测试是否能够走通
-
1.运行kafka消费者,准备消费数据(因为日活需要启动日志,所以我们这里只测试启动日志)
-
bin/kafka-console-consumer.sh --bootstrap-server hadoop105:9092 --topic gmall_start_bak2.运行Idea中的Gmall0421LoggerApplication程序,准备接受模拟生成的数据
-
3.运行模拟生成数据的jar
java -jar gmall0421-mock-log-2020-05-10.jar
将gmall0421-logger打包到单台Linux上运行
(1) 在hadoop105的/opt/module目录下创建rt_gmall目录
[atguigu@hadoop105 module]$ pwd
/opt/module
[atguigu@hadoop105 module]$ mkdir rt_gmall
(2) Idea中修改gmall0421-logger中的logback.xml配置文件,指定日志输出目录
<property name="LOG_HOME" value="/opt/module/rt_gmall/gmall0421" />
注意:路径和上面创建的路径保持一致,根据自己的实际情况进行修改
(3) Idea中修改application.properties端口号
server.port=8989
因为在ZooKeeper从3.5开始,AdminServer的端口也是8080
(4) 打包
问题解决:打包时候如果出现以下问题
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.22.2:test (default-test)
在pom.xml文件中,添加跳过测试
<properties><java.version>1.8</java.version>**<skipTests>true</skipTests>**</properties>
(5) 将打好的jar包上传到hadoop105的/opt/module/rt_gmall目录下
[atguigu@hadoop105 rt_gmall]$ ll总用量 29984-rw-rw-r--. 1 atguigu atguigu 30700347 8月 10 11:35 gmall0421-logger-0.0.1-SNAPSHOT.jar
(6) 修改/opt/module/rt_applog/application.properties
#http模式下,发送的地址
mock.url=http://hadoop105:8989/applog
(7) 测试是否能通
-
运行kafka消费者,准备消费数据(因为日活需要启动日志,所以我们这里只测试启动日志)
[atguigu@hadoop105 rt_gmall]$ kafka-console-consumer.sh --bootstrap-server hadoop105:9092 --topic gmall_start_bak -
运行采集数据的jar
[atguigu@hadoop105 rt_gmall]$ java -jar gmall0421-logger-0.0.1-SNAPSHOT.jar -
运行模拟生成数据的jar
[atguigu@hadoop105 rt_applog]$ java -jar gmall0421-mock-log-2020-05-10.jar
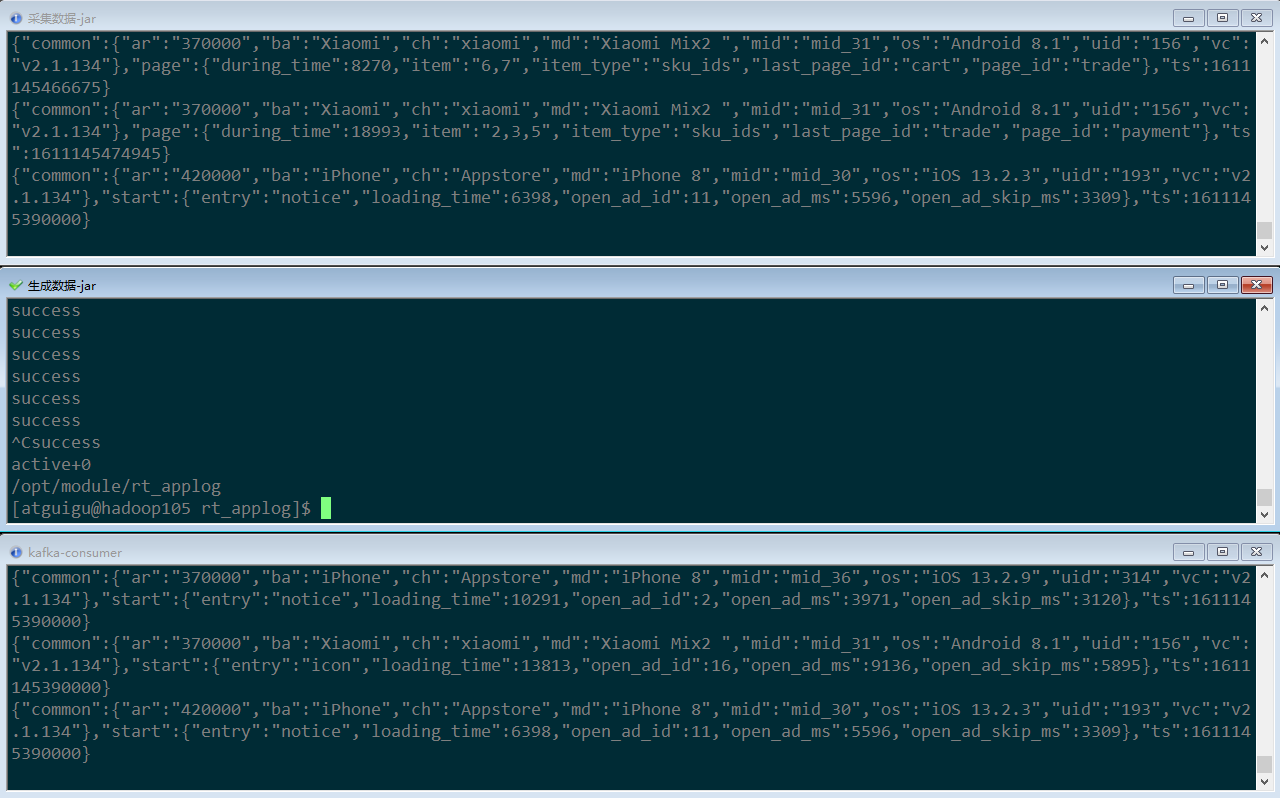
2.3 搭建日志采集集群,并通过Nginx进行反向代理
(1) Nginx环境搭建好
(2) 修改nginx.conf配置文件 注意:每行配置完毕后有分号
在server内部配置
location /applog {proxy_pass http://www.logserver.com;}
在server外部配置反向代理
upstream www.logserver.com {server hadoop105:8989 weight=1;server hadoop106:8989 weight=2;server hadoop107:8989 weight=3;}
(3) 将日志采集的模块jar包同步到hadoop106和hadoop107
[atguigu@hadoop105 module]$ xsync rt_gmall/
(4) 修改模拟日志生成的配置,发送到的服务器路径修改为nginx的
[atguigu@hadoop105 rt_applog]$ vim application.properties
# 外部配置打开
#logging.config=./logback.xml
#业务日期
mock.date=2021-01-20# idea模式 192.168.0.188是windows本机地址
# mock.url=http://192.168.0.188:8989/applog# 打包单台linux运行
# mock.url=http://hadoop105:8989/applog#模拟数据发送模式
mock.type=http
# http模式下,发送的地址
mock.url=http://hadoop105/applog
(5) 测试
-
运行kafka消费者,准备消费数据(因为日活需要启动日志,所以我们这里只测试启动日志)
[atguigu@hadoop105 rt_gmall]$ kafka-console-consumer.sh --bootstrap-server hadoop105:9092 --topic gmall_start_bak -
启动nginx服务
[atguigu@hadoop105 ~]$ /opt/module/nginx/sbin/nginx
-
运行采集数据的jar
[atguigu@hadoop105 **rt_gmall**]$ java -jar gmall0421-logger-0.0.1-SNAPSHOT.jar [atguigu@hadoop106 **rt_gmall**]$ java -jar gmall0421-logger-0.0.1-SNAPSHOT.jar [atguigu@hadoop107 **rt_gmall**]$ java -jar gmall0421-logger-0.0.1-SNAPSHOT.jar -
运行模拟生成数据的jar
[atguigu@hadoop105 rt_applog]$ java -jar gmall0421-mock-log-2020-05-10.jar
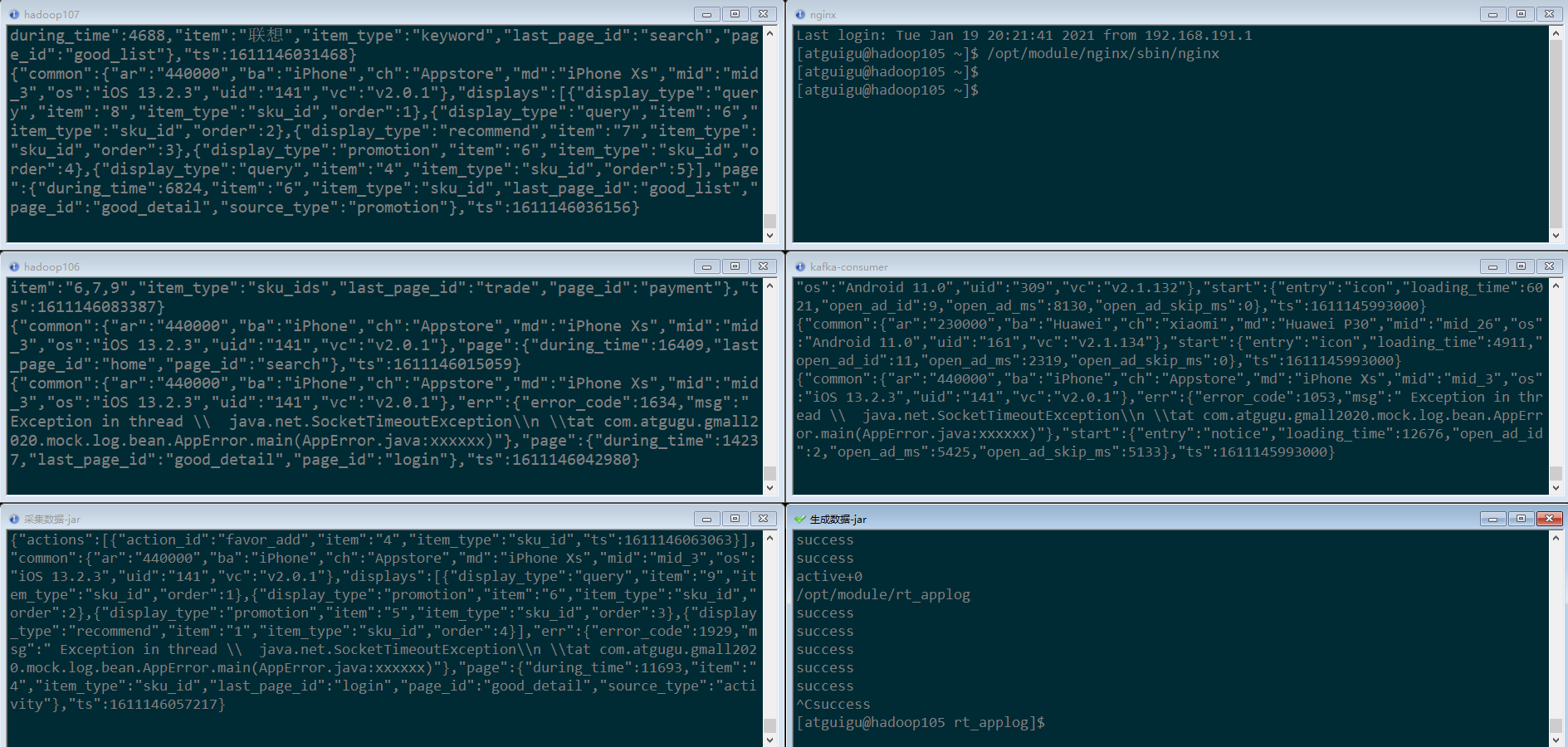
(6) 集群群起脚本 将采集日志服务(nginx和采集日志数据的jar启动服务)放到脚本
在/home/atguigu/bin目录下创建logger.sh,并授予执行权限
#!/bin/bash
JAVA_BIN=/opt/module/java/bin/java
APPNAME=gmall0421-logger-0.0.1-SNAPSHOT.jarcase $1 in"start"){for i in hadoop105 hadoop106 hadoop107doecho "========: $i==============="ssh $i "$JAVA_BIN -Xms32m -Xmx64m -jar /opt/module/rt_gmall/$APPNAME >/dev/null 2>&1 &"doneecho "========NGINX==============="/opt/module/nginx/sbin/nginx};;"stop"){echo "======== NGINX==============="/opt/module/nginx/sbin/nginx -s stopfor i in hadoop105 hadoop106 hadoop107doecho "========: $i==============="ssh $i "ps -ef|grep $APPNAME |grep -v grep|awk '{print \$2}'|xargs kill" >/dev/null 2>&1done};;esac(7) 再次测试
-
运行kafka消费者,准备消费数据(因为日活需要启动日志,所以我们这里只测试启动日志)
[atguigu@hadoop105 rt_gmall]$ kafka-console-consumer.sh --bootstrap-server hadoop105:9092 --topic gmall_start_bak -
启动nginx服务采集服务集群
logger.sh start -
运行模拟生成数据的jar
[atguigu@hadoop105 rt_applog]$ java -jar gmall0421-mock-log-2020-05-10.jar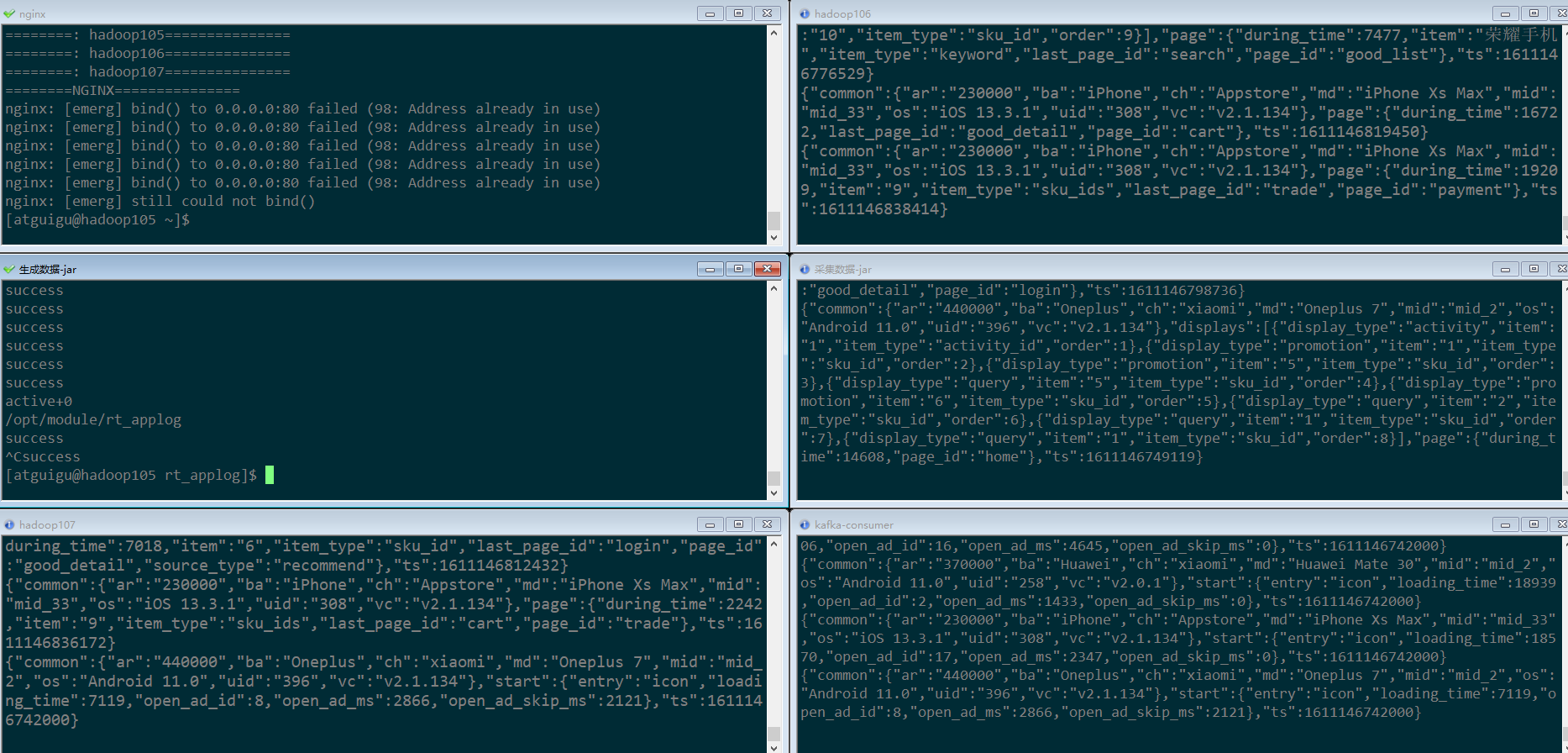
第3章 附录1:SpringBoot知识点
3.1 Springboot简介
Spring Boot 是由 Pivotal 团队提供的全新框架,其设计目的是用来简化新 Spring 应用的初始搭建以及开发过程。 该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。
3.2 有了springboot 我们就可以…
不再需要那些千篇一律,繁琐的xml文件。
-
内嵌Tomcat,不再需要外部的Tomcat
-
更方便的和各个第三方工具(mysql,redis,elasticsearch,dubbo,kafka等等整合),而只要维护一个配置文件即可。
3.3 springboot和ssm的关系
springboot整合了springmvc ,spring等核心功能。也就是说本质上实现功能的还是原有的spring ,springmvc的包,但是springboot单独包装了一层,这样用户就不必直接对springmvc, spring等,在xml中配置。
3.4 没有xml,我们要去哪配置
-
springboot实际上就是把以前需要用户手工配置的部分,全部作为默认项。除非用户需要额外更改不然不用配置。这就是所谓的:“约定大于配置”
如果需要特别配置的时候,去修改application.properties (application.yml)
第4章 附录2:Nginx
4.1 Nginx简介
Nginx (“engine x”) 是一个高性能的HTTP和反向代理服务器,特点是占有内存少,并发能力强,事实上nginx的并发能力确实在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。
Nginx 是由俄罗斯人 Igor Sysoev 采用C语言开发编写的,第一个公开版本0.1.0发布于2004年10月4日。
Igor Sysoev,Nginx的创始人
Igor Sysoev出生于1970年的阿拉木图(哈萨克斯坦共和国城市),也就是前苏联。1991年苏联解体,哈萨克斯坦宣布独立,Nginx作者1994年毕业于莫斯科国立鲍曼技术大学;毕业后继续在莫斯科工作和生活,就职于NGINX,Inc,任CTO。https://www.nginx.com/
4.2 正向代理和反向代理概念
正向代理类似一个跳板机,代理访问外部资源。比如:我是一个用户,我访问不了某网站,但是我能访问一个代理服务器,这个代理服务器,它能访问那个我不能访问的网站,于是我先连上代理服务器,告诉它我需要那个无法访问网站的内容,代理服务器去取回来,然后返回给我。

反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器;
4.3 Nginx安装以及相关命令
- 在hadoop105上运行yum,安装相关依赖包
sudo yum -y install openssl openssl-devel pcre pcre-devel zlib zlib-devel gcc gcc-c++
-
将/2.资料/工具下的nginx-1.12.2.tar.gz上传到/opt /software下
-
在/opt/module/software下解压缩nginx-1.12.2.tar.gz包
-
进入解压缩目录,执行
./configure --prefix=/opt/module/nginx
make && make install
--prefix=要安装到的目录
-
安装成功后,/opt/module/nginx目录下结构
-
启动Nginx
在/opt/module/nginx/sbin目录下执行 ./nginx
- 如果在atguigu用户下面启动会报错
原因:nginx占用80端口,默认情况下非root用户不允许使用1024以下端口
解决:让当前用户的某个应用也可以使用1024以下的端口
sudo setcap cap_net_bind_service=+eip /opt/module/nginx/sbin/nginx
注意:要根据自己的实际路径进行配置
- 查看启动情况
ps -ef |grep nginx
因为nginx不是用java写的,所以不能通过jps查看
-
在浏览器中输入http://hadoop105/访问
-
重启Nginx
./nginx -s reload
- 关闭Nginx
./nginx -s stop
- 通过配置文件启动
./nginx -c /usr/local/nginx/conf/nginx.conf/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
其中-c是指定配置文件,而且配置文件路径必须指定绝对路径
- 配置检查
当修改Nginx配置文件后,可以使用Nginx命令进行配置文件语法检查,用于检查Nginx配置文件是否正确
/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf –t
- 部分机器启动时报错:
/usr/local/nginx/sbin/nginx: error while loading shared libraries: libpcre.so.1: cannot open shared object file: No such file or directory
解决:ln -s /usr/local/lib/libpcre.so.1 /lib64
4.4 Nginx核心配置文件说明
学习Nginx首先需要对它的核心配置文件有一定的认识,这个文件位于Nginx的安装目录/opt/module/nginx/conf目录下,名字为nginx.conf
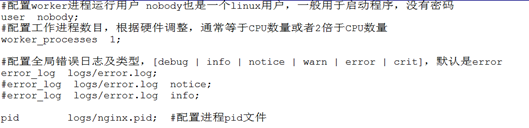
4.4.1 基本配置
4.4.2 events配置

4.4.3 http配置
(1) 基本配置

(2) server配置,可以有多个

4.5 Nginx主要应用
4.5.1 静态网站部署
Nginx是一个HTTP的web服务器,可以将服务器上的静态文件(如HTML、图片等)通过HTTP协议返回给浏览器客户端
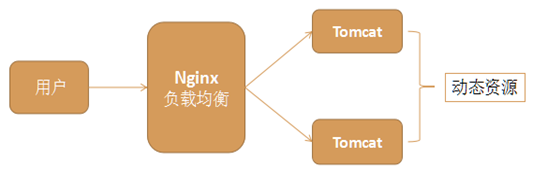
4.5.2 负载均衡
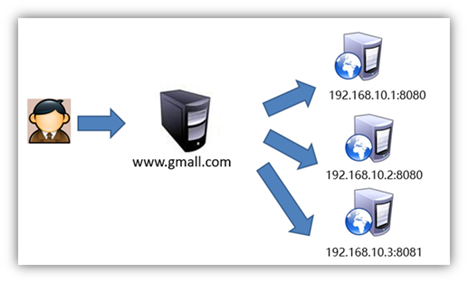
在网站创立初期,我们一般都使用单台机器对外提供集中式服务。随着业务量的增大,我们一台服务器不够用,此时就会把多台机器组成一个集群对外提供服务,但是,我们网站对外提供的访问入口通常只有一个,比如 www.web.com。那么当用户在浏览器输入www.web.com进行访问的时候,如何将用户的请求分发到集群中不同的机器上呢,这就是负载均衡要做的事情。
负载均衡通常是指将请求"均匀"分摊到集群中多个服务器节点上执行,这里的均匀是指在一个比较大的统计范围内是基本均匀的,并不是完全均匀
常用的负载均衡策略:轮询、权重、备机…
4.5.3 静态代理
把所有静态资源的访问改为访问nginx,而不是访问tomcat,这种方式叫静态代理。因为nginx更擅长于静态资源的处理,性能更好,效率更高。
所以在实际应用中,我们将静态资源比如图片、css、html、js等交给nginx处理,而不是由tomcat处理。
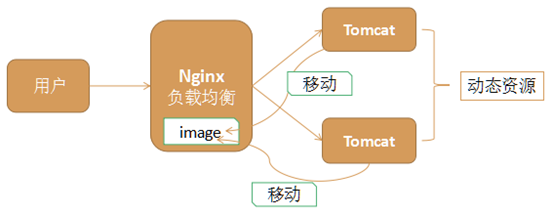
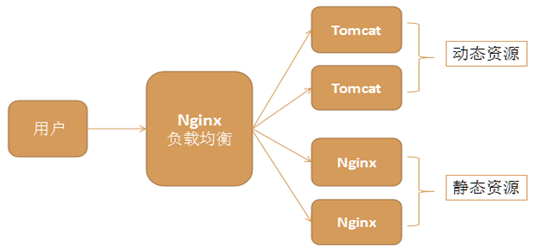
4.5.4 动静分离
Nginx的负载均衡和静态代理结合在一起,我们可以实现动静分离,这是实际应用中常见的一种场景。
动态资源,如jsp由tomcat或其他web服务器完成
静态资源,如图片、css、js等由nginx服务器完成
它们各司其职,专注于做自己擅长的事情
动静分离充分利用了它们各自的优势,从而达到更高效合理的架构
4.5.5 虚拟主机
虚拟主机,就是把一台物理服务器划分成多个“虚拟”的服务器,这样我们的一台物理服务器就可以当做多个服务器来使用,从而可以配置多个网站。
Nginx提供虚拟主机的功能,就是为了让我们不需要安装多个Nginx,就可以运行多个域名不同的网站。
Nginx下,一个server标签就是一个虚拟主机。nginx的虚拟主机就是通过nginx.conf中server节点指定的,想要设置多个虚拟主机,配置多个server节点即可。
比如一个公司有多个二级域名,没有必要为每个二级域名都提供一台Nginx服务器,就可以使用虚拟主机技术,在一台nginx服务器上,模拟多个虚拟服务器。