实时数据流采集工具Flume
- 实时数据流采集工具Flume
- 1.1 Flume的介绍
- 1.2 Flume的特点
- 1.3 Flume的功能架构
- 1.4 Flume的功能原理
- 1.5 Flume的安装部署
- 1.6 Flume两种常见基础架构
- 1.6.1 多路复用流Multiplexing The Flow
- 1.6.2 Consolidation
- 1.7 Flume中常用的三大基础组件
- 1.7.1 source
- 1.7.1.1 Exec Source
- 1.7.1.1.1 功能
- 1.7.1.1.2 应用场景
- 1.7.1.1.3 不适合的应用场景
- 1.7.1.2 Spooling Directory Source
- 1.7.1.2.1 功能
- 1.7.1.2.2 应用场景
- 1.7.1.2.3 注意事项
- 1.7.1.2.4 配置示例
- 1.7.1.3 Taildir Source
- 1.7.1.3.1 功能
- 1.7.1.3.2 应用场景
- 1.7.1.3.3 配置示例
- 1.7.2 channel
- 1.7.2.1 Memory Channel
- 1.7.2.1.1 功能
- 1.7.2.1.2 应用场景
- 1.7.2.1.3 案例
- 1.7.2.2 File Channel
- 1.7.2.2.1 功能
- 1.7.2.2.2 应用场景
- 1.7.2.2.3 案例:
- 1.7.3 sink
- 1.7.3.1 HDFS Sink
- 1.7.3.1.1 功能
- 1.7.3.1.2 应用场景
- 1.7.3.1.3 示例
- 1.8 Flume中三大高级组件
- 1.8.1 Flume Channel Selectors
- 1.8.2 Flume Sink Processors
- 1.8.2.1 实现故障转移
- 1.8.2.2 实现负载均衡
- 1.8.3 Flume Interceptors拦截器
- 1.8.3.1 拦截器的功能
- 1.8.3.2 常用拦截器
- 1.8.3.2.1 Timestamp Interceptor
- 1.8.3.2.2 Host Interceptor
- 1.8.3.2.3 Static Interceptor
- 1.8.3.2.4 Regex Filtering Interceptor
- 1.8.3.2.5 示例
实时数据流采集工具Flume
1.1 Flume的介绍
Flume是一个实时数据流采集框架,是一种分布式的、高可用的服务,可以有效的收集、聚合和移动大量的日志数据。将数据源的数据变成数据流,将数据采集到目标位置中。本质上就是一个数据迁移的过程。官网文档地址
1.2 Flume的特点
1. 功能非常强大,提供了大量的数据源和目标数据的接口,可以读取各种数据源的数据,将数据写入各种目标地。
2. 开发非常简单,由于Flume封装了大量的功能接口,使用时只要调用就可以。编写一个配置文件,定义从哪读数据,把数据写入到哪里去,然后运行这个文件就可以。
3. 支持用户自定义接口开发,一般情况下自带的数据读写接口已经完全满足需求。
4. 实时性,只要数据一生成,就立马会被采集。
5. 稳定性,Flume提供了负载均衡和故障转移的设计,保证数据在传输过程中的安全性。
1.3 Flume的功能架构
Flume的每个程序就是一个配置文件,也是一个Flume agent,它由三大基本组件组成。分别为source、channel、sink,source主要为收集数据,根据配置读取数据源中的数据,将数据源中读取到的数据变成数据流发送给channel。channel主要为聚合数据,接收source发送过来的数据,临时存储。sink主要为发送给数据,从channel中拉取数据过来,将数据发送到目标地。
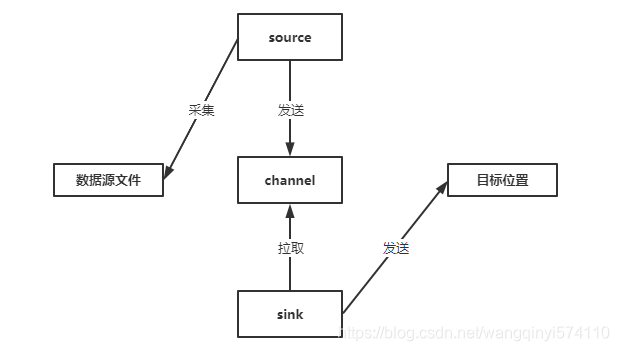
1.4 Flume的功能原理
1. event:是Flume数据传输过程中的最小单元。
(1) header:存储一些key-value对的属性,默认header为空,除非手动添加头部。
(2) body:放的就是真正这一行的数据。
2. source
(1) 监听数据源的变化,如果数据源一旦产生新的数据,就会将数据源中新的数据变成数据流。
(2) 数据流中的每一条数据是一个event单位,默认的source,会将数据源的每一行变成一个event。
(3) 将每个event发送给channel。
3. channel:临时存储采集到的数据的地方。
(1) channel将source采集到的event临时存储起来。
4. sink
(1) 负责从channel中取每个event。
(2) 将event中的数据写入目标地。
1.5 Flume的安装部署
-
在Flume官网地址下载版本然后上传到Linux上。
-
解压
tar -zxvf apache-flume-1.9.0-bin.tar.gz -
创建软连接
ln -s apache-flume-1.9.0-bin flume -
修改配置信息
mv flume-env.sh.template flume-env.sh vim flume-env.sh #修改JAVA_HOME export JAVA_HOME=/xxx/xxx/jdk_xxx -
Flume如果需要把数据采集到HDFS上,需要把HDFS上面的core-site.xml和hdfs-site.xml文件放到Flume的配置目录中。
-
运行方式
bin/flume-ng agent -c conf/ -f userCase/hive-mem-log.properties -n a1 -Dflume.root.logger=INFO,console-c/--conf :用于指定flume的配置文件目录 --conf-file,-f:指定要运行的 配置文件的 --name/-n :指定你要运行的agent的名字 -Dflume.root.logger=INFO,console:将flume的日志打印在控制台
1.6 Flume两种常见基础架构
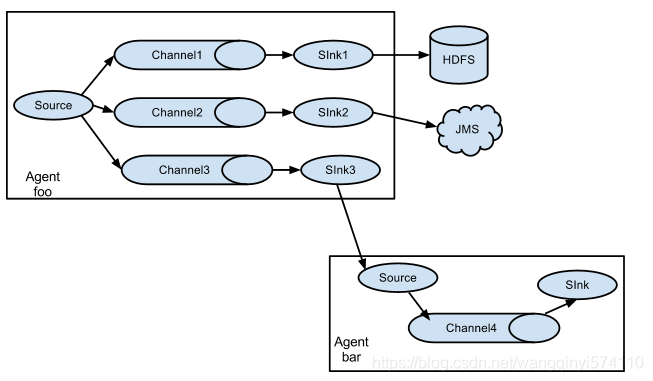
1.6.1 多路复用流Multiplexing The Flow
Flume支持将事件流多路复用到一个或多个目的地。这是通过定义一个多路复用器来实现的,该多路复用器可以复制或有选择的将event路由到一个或者多个channel中。说白了就是一个source可以定义多个channel和sink。有几个sink就要有几个channel。因为一个channel中只存一份数据,如果多个sink共享一个channel,每个sink取到的数据是不完整的。
官网上的架构图如下:
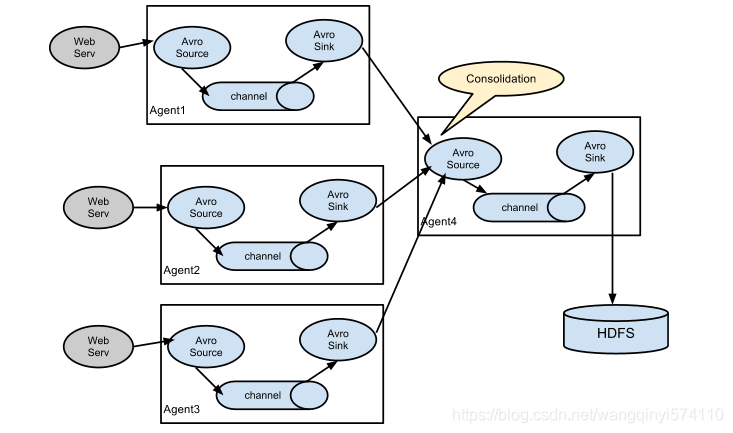
1.6.2 Consolidation
Flume的联级架构,可以用来实现Flume的高可用架构,在工作中经常会出现从n多个数据源采集数据到一个目标位置中,这种情况下n多个Flume会并发的写入大量的数据到一个目标位置,会严重影响目标软件的性能。这种情况下就需要采用当前这种架构,第一层Flume agent 负责采集每一台日志节点上的数据,将数据发送给Flume collect,第二层的Flume collect负责将收集到的数据发送给目标地址。
官网上的架构图如下:
1.7 Flume中常用的三大基础组件
1.7.1 source
负责采集数据源,将数据源的数据变成数据流,封装成event,存储到channel中。Flume采集的主要数据源是日志文件。
1.7.1.1 Exec Source
1.7.1.1.1 功能
可以使用一条Linux的命令来采集文件的数据,一般都是与tail命令一起使用。
1.7.1.1.2 应用场景
1. 用于监听单个日志文件的变化,只要日志文件产生变化,就会将新的数据立马采集。
2. 日志文件只有一个。
1.7.1.1.3 不适合的应用场景
1. 日志文件有多个,例如按天生成日志或者按小时生成日志。
2. 一天一个日志文件或者一个小时一个日志文件。
1.7.1.2 Spooling Directory Source
1.7.1.2.1 功能
监听一个目录,只要目录中产生新的文件,就会立马采集该文件的数据。
1.7.1.2.2 应用场景
1. 每天或者每小时就生成一个日志文件,都在一个日志目录下。
2. 将产生的新的日志可以直接立马采集。
1.7.1.2.3 注意事项
1. 可以采集一个目录中的多个文件,但是不能动态监控文件的变化。对于追加形式的文件不能使用。
1.7.1.2.4 配置示例
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#define the source s1
a1.sources.s1.type = spooldir
#监控目录
a1.sources.s1.spoolDir = /export/datas/flume/tomcat
#如果该文件已经被采集完成,后缀名是什么
a1.sources.s1.fileSuffix = .end
#设置过滤.tmp结尾的文件
a1.sources.s1.ignorePattern = ([^ ]*\\.tmp$)
#define the channels c1
a1.channels.c1.type = memory
#define the sinks k1
a1.sinks.k1.type = logger
#bind
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
1.7.1.3 Taildir Source
1.7.1.3.1 功能
相当于exec和spool dir的优点的合并,能实现同时监控多个文件或者目录,动态的监控每个文件的变化。
1.7.1.3.2 应用场景
满足所有采集日志的应用场景。
1.7.1.3.3 配置示例
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#define the source s1
a1.sources.s1.type = TAILDIR
#指定采集时监控的每个文件的已经被采集位置,用于避免数据被重复采集
a1.sources.s1.positionFile = /export/servers/flume-1.6.0-cdh5.14.0-bin/position/taildir_position.json
#指定要采集几个数据源:f1负责采集文件,f2负责采集目录
a1.sources.s1.filegroups = f1 f2
#指定f1具体采集哪个文件
a1.sources.s1.filegroups.f1 = /export/datas/flume/tomcat/taildir/taildir.txt
#指定f1采集到的数据的头部添加一个keyvalue:headerKey1=file
a1.sources.s1.headers.f1.headerKey1 = file
#指定f2具体采集哪个文件
a1.sources.s1.filegroups.f2 = /export/datas/flume/tomcat/taildir/dir/.*.log
#指定f2采集的数据中添加一个头部:headerKey1=dir
a1.sources.s1.headers.f2.headerKey1 = dir
#开启文件头部
a1.sources.s1.fileHeader = true
#define the channels c1
a1.channels.c1.type = memory
#define the sinks k1
a1.sinks.k1.type = logger
#bind
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
1.7.2 channel
将Source采集到的数据【每个event】进行临时的存储,提供给Sink过来取数据。类似于一个数据的管道,source不断将数据放入管道的尾部,sink不断的从管道的头部取数据。
1.7.2.1 Memory Channel
1.7.2.1.1 功能
将source发送过来的数据缓存在内存中。
1.7.2.1.2 应用场景
1. 适合于数据量小,要求性能比较高,比较快的场景。
2. 内存的特点:小、易丢失、快。
1.7.2.1.3 案例
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#define the source s1
a1.sources.s1.type = exec
a1.sources.s1.command = tail -f /export/servers/hive-1.1.0-cdh5.14.0/logs/hive.log
#define the channels c1
a1.channels.c1.type = memory
#表示整个channel中允许存放多少个event,这个值一般建议计算以后得到
#先计算一条event的大小,然后根据允许内存的使用大小来得到:100字节,2GB内存
a1.channels.c1.capacity = 50000
#表示每次source往channel中放和每次sink从channel中最多允许取多少个event,一般建议给容量的十分之一
a1.channels.c1.transactionCapacity = 5000
#define the sinks k1
a1.sinks.k1.type = logger
#bind
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
1.7.2.2 File Channel
1.7.2.2.1 功能
将source发送过来的数据存储在文件中。
1.7.2.2.2 应用场景
1. 适合于数据量大,性能要求不高,要求数据安全。
2. 文件的特点:容量大、不易丢失、性能相对内存差一点。
1.7.2.2.3 案例:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#define the source s1
a1.sources.s1.type = exec
a1.sources.s1.command = tail -f /export/servers/hive-1.1.0-cdh5.14.0/logs/hive.log
#define the channels c1
a1.channels.c1.type = file
#source发送的数据缓存在哪个目录中
a1.channels.c1.dataDirs = /export/datas/flume/tomcat/filechannel/data
#对缓存的数据做数据校验,保证数据的安全
a1.channels.c1.checkpointDir = /export/datas/flume/tomcat/filechannel/check
a1.channels.c1.capacity = 50000
a1.channels.c1.transactionCapacity = 5000
#define the sinks k1
a1.sinks.k1.type = logger
#bind
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
1.7.3 sink
1.7.3.1 HDFS Sink
1.7.3.1.1 功能
将采集到的数据写入HDFS。
1.7.3.1.2 应用场景
需要将Flume采集到的数据放入HDFS或者Hive中。
1.7.3.1.3 示例
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#define the source s1
a1.sources.s1.type = exec
a1.sources.s1.command = tail -f /export/servers/hive-1.1.0-cdh5.14.0/logs/hive.log
#define the channels c1
a1.channels.c1.type = memory
#表示整个channel中允许存放多少个event,这个值一般建议计算以后得到
#先计算一条event的大小,然后根据允许内存的使用大小来得到:100字节,2GB内存
a1.channels.c1.capacity = 50000
#表示每次source往channel中放和每次sink从channel中最多允许取多少个event,一般建议给容量的十分之一
a1.channels.c1.transactionCapacity = 5000
#define the sinks k1
a1.sinks.k1.type = hdfs
#设置写入的hdfs的地址,建议写绝对地址:hdfs://node-01:8020/flume,如果不写文件系统直接写目录也可以,但要保证flume知道hdfs的地址
a1.sinks.k1.hdfs.path = /flume/hdfs/size
#指定写入hdfs的文件的文件名前缀和文件名的后缀
a1.sinks.k1.hdfs.filePrefix = hiveLog
a1.sinks.k1.hdfs.fileSuffix = .log
#指定写入的文件为普通的text文件,默认为SequenceFile
a1.sinks.k1.hdfs.fileType = DataStream
#指定hdfs上文件生成的大小:优先128M一个文件,由于存在event偏差,建议设置125M左右的字节数
a1.sinks.k1.hdfs.rollSize = 10240
#指定按照时间生成hdfs的文件,0表示关闭
a1.sinks.k1.hdfs.rollInterval = 0
#指定按照event的个数生成hdfs的文件,0表示关闭
a1.sinks.k1.hdfs.rollCount = 0
#bind
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
1.8 Flume中三大高级组件
1.8.1 Flume Channel Selectors
决定了source如何将数据给channel,默认的情况下source会将数据给每个channel一份,默认的配置如下:
a1.sources = s1
a1.channels = c1 c2 c3
#指定选择器为replicating
a1.sources.s1.selector.type = replicating
#实现的 效果是s1 会将所有数据给c1/c2/c3每个channel一份
a1.sources.s1.channels = c1 c2 c3
a1.sources.s1.selector.optional = c3
可使用给定的条件来实现将不同的数据给不同的channel。如下配置:
官方的示例:
a1.sources = s1
a1.channels = c1 c2 c3 c4
#指定选择器类型multiplexing
a1.sources.s1.selector.type = multiplexing
#条件需要根据event头部的某个key的值来判断,官方的示例中默认每个event的头部有个state=value
a1.sources.s1.selector.header = state
#如果该event的state=CZ,就将该event给c1
a1.sources.s1.selector.mapping.CZ = c1
#如果该event的state=US,就将该event给c2和c3一人一份
a1.sources.s1.selector.mapping.US = c2 c3
#如果都不符合,就给c4
a1.sources.s1.selector.default = c4#例如我们自己的程序
#前提首先要在每个event的头部添加一个keyvalue对
#key:log
#value:INFO/WRAN/ERRORa1.sources = s1
a1.channels = c1 c2 c3
a1.sources.s1.selector.type = multiplexing
a1.sources.s1.selector.header = log
a1.sources.s1.selector.mapping.INFO = c1
a1.sources.s1.selector.mapping.WARN = c2
a1.sources.s1.selector.default = c3
重点在于每个event在产生时,header的部分必须包含一个能用于判断的key-value,根据某个key的value来决定这条event数据给哪个channel,需要通过拦截器添加key-value。
1.8.2 Flume Sink Processors
在上面1.6介绍的联级架构中,如果Flume collect宕机了,如果来保证数据的正常传输呢?
这种情况就要使用Flume Sink Processors,构建两个Flume collect,同时工作,如果一个宕机,另外一个依然能将数据采集到目标位置上。Flume Sink Processors本质的功能是用sinkgroup来代替sink,一个sinkgroup可以有多个sink,但是一个sinkgroup是一个整体,一个sinkgroup会从一个channel中取数据,交给组内的sink来实现发送。
1.8.2.1 实现故障转移
一个sinkgroup中两个sink,sinkgroup从Channel中获取数据以后,到底由哪个sink来发送到目标位置,这个由权重决定,权重高的先执行,只有当先执行的sink故障了,另外一个sink才工作,类似于HA。
配置:
a1.sinks.k1.type = avro
a1.sinks.k1.host = collect1
a1.sinks.k1.port = 45454
a1.sinks.k2.type = avro
a1.sinks.k2.host = collect2
a1.sinks.k2.port = 45454
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
#sink组实现的功能是故障转移
a1.sinkgroups.g1.processor.type = failover
#k1的权重是50
a1.sinkgroups.g1.processor.priority.k1 = 50
#k2的权重是10
a1.sinkgroups.g1.processor.priority.k2 = 10
1.8.2.2 实现负载均衡
一般来说负载均衡也能实现故障转移的效果, 在实际工作中一般都配置负载均衡。一个sinkgroup中有两个sink,这两个sink是同时工作的,当sinkgroup从Channel中获取一条数据以后,这条数据由哪个sink发送呢?分配的规则:轮询、随机。以轮询为例,collect1机器故障,sink1故障,sinkgroup将数据依旧使用轮询规则来发送,但是这时候只有sink2,所以负载均衡包含了故障转移的功能
配置如下:
a1.sinks.k1.type = avro
a1.sinks.k1.host = collect1
a1.sinks.k1.port = 45454
a1.sinks.k2.type = avro
a1.sinks.k2.host = collect2
a1.sinks.k2.port = 45454
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
#sink组实现的 功能是负载均衡
a1.sinkgroups.g1.processor.type = load_balance
#两个sink一起工作数据分配的规则
a1.sinkgroups.g1.processor.selector = round_robin
规则有两种:
round_robin:轮询
random:随机
工作中的配置情况
Flume agent程序
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#define the source s1
a1.sources.s1.type = exec
a1.sources.s1.command = tail -f /export/datas/nginx.log
#define the channels c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 50000
a1.channels.c1.transactionCapacity = 5000
#define the sinks k1
a1.sinks.k1.type = avro
a1.sinks.k1.host = node04
a1.sinks.k1.port = 45454
#define the sinks k2
a1.sinks.k2.type = avro
a1.sinks.k2.host = node05
a1.sinks.k2.port = 45454
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
#sink组实现的 功能是负载均衡
a1.sinkgroups.g1.processor.type = load_balance
#两个sink一起工作数据分配的规则
a1.sinkgroups.g1.processor.selector = round_robin
#bind
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
Flume collect程序
a2.sources = s1
a2.channels = c1
a2.sinks = k1
#define the source s1
a2.sources.s1.type = avro
a2.sources.s1.bind = node04
a2.sources.s1.port = 45454
#define the channels c1
a2.channels.c1.type = memory
a2.channels.c1.capacity = 50000
a2.channels.c1.transactionCapacity = 5000
#define the sinks k1
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = /flume/hdfs/collect
a2.sinks.k1.hdfs.filePrefix = hiveLog
a2.sinks.k1.hdfs.fileSuffix = .log
a2.sinks.k1.hdfs.fileType = DataStream
#bind
a2.sources.s1.channels = c1
a2.sinks.k1.channel = c1
a2.sources = s1
a2.channels = c1
a2.sinks = k1
#define the source s1
a2.sources.s1.type = avro
a2.sources.s1.bind = node05
a2.sources.s1.port = 45454
#define the channels c1
a2.channels.c1.type = memory
a2.channels.c1.capacity = 50000
a2.channels.c1.transactionCapacity = 5000
#define the sinks k1
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = /flume/hdfs/collect
a2.sinks.k1.hdfs.filePrefix = hiveLog
a2.sinks.k1.hdfs.fileSuffix = .log
a2.sinks.k1.hdfs.fileType = DataStream
#bind
a2.sources.s1.channels = c1
a2.sinks.k1.channel = c1
注意:node04或者node05任何一台机器故障,都可以保证整个数据传输正常运行。
美团Flume示例
1.8.3 Flume Interceptors拦截器
拦截器用于source在采集数据时,发生在将每一条数据变成event阶段,可以应用拦截器。
1.8.3.1 拦截器的功能
1. 将event添加key-value。
2. 过滤数据,选择性的采集哪些数据。
1.8.3.2 常用拦截器
1.8.3.2.1 Timestamp Interceptor
在每个event的头部添加一个key-value。key:timestamp;value:就是该event的生成的时间。
1.8.3.2.2 Host Interceptor
在每个event的头部添加一个key-value。key:hostname;value:这条数据所在的机器名称。
1.8.3.2.3 Static Interceptor
在每个event的头部添加一个key-value。key:自定义;value:自定义。
1.8.3.2.4 Regex Filtering Interceptor
可以通过正则表达式来实现数据的过滤。符合正则将会被采集,不符合正则的数据不会被采集。
1.8.3.2.5 示例
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#define the source s1
a1.sources.s1.type = exec
a1.sources.s1.command = tail -f /export/datas/flume/interceptors.txt
#定义2个拦截器
a1.sources.s1.interceptors = i1 i2
#添加第一个时间戳拦截器
a1.sources.s1.interceptors.i1.type = timestamp
#添加第二个正则拦截器
a1.sources.s1.interceptors.i2.type = regex_filter
a1.sources.s1.interceptors.i2.regex = (\\d):(\\d):(\\d)
#define the channels c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 50000
a1.channels.c1.transactionCapacity = 5000
#define the sinks k1
a1.sinks.k1.type = logger
#bind
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1