「搜索」并不局限于我们常说的搜索引擎、搜索框,实际上,问答机器人本质上也是一种「搜索」,输入相关查询,返回最接近或最相关的答案。
今天,我们将演示如何利用 Jina 全家桶,创建一个智能问答机器人,并将其部署到云端。
开发过程一览:4 步创建问答机器人
新冠爆发之初,人们对这种新型病毒充满疑问,本教程将以疫情相关的问答为应用场景,以普通 Chatbot 的交互形式为依托,最终实现用户在终端键入查询(问题)后,智能问答机器人可以输出相关的答案。

创建问答机器人的过程包括:
1、加载数据到搜索应用
2、创建并运行 Flow 索引数据(数据编码并将向量和元数据存储到磁盘上)
3、运行相同的 Flow,用户输入问题进行搜索
4、在浏览器中运行 GUI
从 0 到 1:开发过程详解
1、下载数据集
下载 COVID-QA 数据集,你可以:Clone GitHub Repo 或在 Kaggle 下载。

因为本示例中,我们只会用到问答相关的数据,因此仅使用 community.csv 文件即可。该文件中包括 400 多对源自 4 个大洲、15 个英文网站的相关 QA。
2、设置
创建一个名为 config.py 的文件,便于后期修改基本设置:
PORT = 23456 # which port will we run the REST interface on?
NUM_DOCS = 30000 # how many rows of the CSV do we want to index?
DATA_FILE = "./data/community.csv" # where can we find the CSV安装 DocArray 和 Jina:
pip install docarray jina3、将数据转换为 DocumentArray
Document 是 Jina 的原始数据类型,文本、图像、音频、视频等各种类型的数据,都会转换为 Document。一组 Document 组成一个 DocumentArray。
以上功能都可以通过 DocArray 实现。
本示例中,每一行 CSV 文件都会被视为一个 Document,所有 Document 组成一个 DocumentArray 后,才进行下一步处理。
利用 DocArray 的 from_CSV 功能,可以快速处理 CSV 文件。在 app.py 中使用 from_CSV:
from config import DATA_FILE, NUM_DOCSdocs = DocumentArray.from_csv(DATA_FILE, field_resolver={"question": "text"}, size=NUM_DOCS
)引用先前在 config.py 中设置的 DATA_FILE 和 NUM_DOCS 。将所有 Document 的 text 属性映射到相关的 question 字段中。其他字段将作为元数据,自动添加到 Document 的 tags 属性中。
4、创建索引 Flow
获取 DocumentArray,对于 Document:
* 将其内容编码为向量并存储在索引中,以便稍后搜索
这里需要用到 Flow:
flow = (Flow(protocol="http", port=PORT).add(name="encoder",uses="jinahub+docker://TransformerTorchEncoder",uses_with={"pretrained_model_name_or_path": "sentence-transformers/paraphrase-mpnet-base-v2"},).add(name="indexer", uses="jinahub://SimpleIndexer", install_requirements=True)
)如上图代码所示,这里使用 Flow().add(...).add(...) 调用 Jina Hub 的 Executor:
* Encoding:第一个 .add() 用于添加编码器 Executor--TransformerTorchEncoder,它运行在 Docker 容器中,无需担心依赖。这里还可以设定希望使用的模型。
* Indexing:最后一个 .add() 调用了索引器 Executor--SimpleIndexer。因为 SimpleIndexer 需要编写本地文件系统(该示例中可使用 uses_with 和 volume 选项),因此无需在 Docker 中运行。
此外,在这段代码中,我们还启用了 HTTP 网关,并在 Flow 参数中创建了端口。
5、运行索引 Flow
通过以下方式运行 Flow:
with flow:flow.index(docs, show_progress=True)要启动索引 Flow,需要在终端中运行 app.py。首次运行可能比较慢,因为需要从 Jina Hub 下载 Executor,并处理这些数据。
注:这里可能会出现一些警告,直接忽略即可。

接下来我们将看到一个包含索引数据的 workspace 目录:
 在这个 workspace 文件夹中,可以看到 index.db ,这是一个 SQLite 数据库,用于存储数据:
在这个 workspace 文件夹中,可以看到 index.db ,这是一个 SQLite 数据库,用于存储数据:
 对整个数据集进行索引后,workspace 目录约占用 5.4 Mb 存储空间。
对整个数据集进行索引后,workspace 目录约占用 5.4 Mb 存储空间。
6、向机器人提问
使用相同的 Flow 搜索问题的答案。如前文所述,Jina 全家桶中原始的数据类型是 Document,所以:
* 将问题包装成一个 Document
* 将该 Document 传递给 Flow
* 获取从 Flow 中返回的最类似的问题
* 从最类似的问题中,打印答案字段
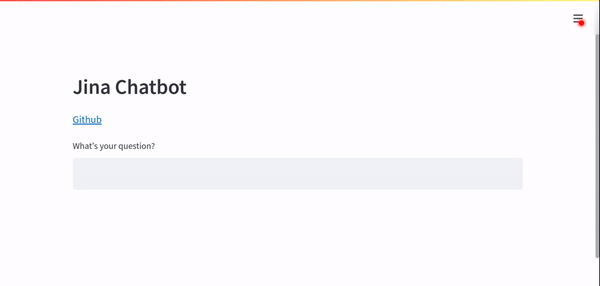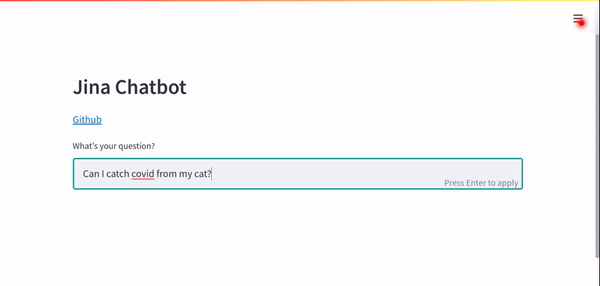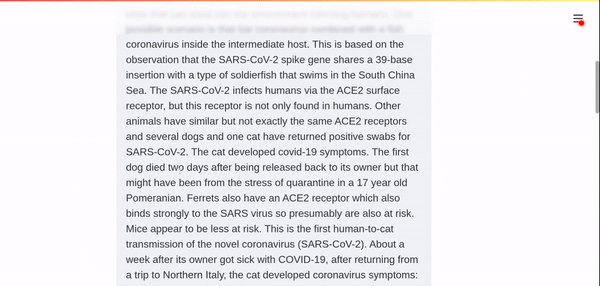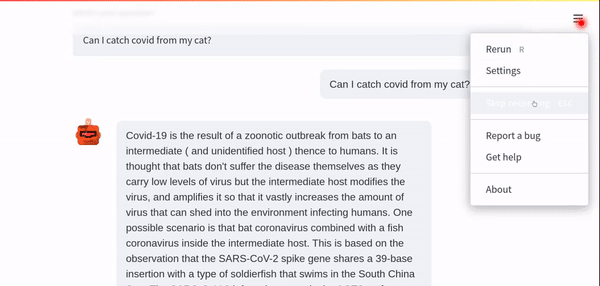
question = Document(text="Can I catch COVID from my cat?")
with flow:results = flow.search(question)print(results[0].matches[0].tags["answer"])这段代码中,我们使用了跟索引的时候相同的两个 Executor,但是功能并不相同:
* Encoding: 将问题文本字符编码成向量
* Indexing: 在索引中搜索与问题 (question) 向量最接近的向量,并返回匹配的数据
现在再次运行 app.py 可以得到如下答案:
Covid-19 is the result of a zoonotic outbreak from bats to an intermediate (and unidentified host) thence to humans….The SARS-CoV-2 infects humans via the ACE2 surface receptor, but this receptor is not only found in humans. Other animals have similar but not exactly the same ACE2 receptors and several dogs and one cat have returned positive swabs for SARS-CoV-2. The cat developed covid-19 symptoms.
进阶示例中,长答案会被分解成句子块,只把最相关的返回给用户。
6、使用 Streamlit 创建 UI
用 Streamlit 创建前端,借助 Streamlit-Chat 模块创建一个类似聊天机器人的界面:
pip install streamlit-chat streamlit再次设置一个基本的前端 config.py :
PORT = 23456
SERVER = "0.0.0.0"
TOP_K = 1frontend.py 非常重要,它决定了我们与后端交互并获取最佳答案的方式。这里需要用到 Jina Client:
from jina import Clientdef search_by_text(input, server=SERVER, port=PORT, limit=TOP_K):client = Client(host=server, protocol="http", port=port)response = client.search(Document(text=input),parameters={"limit": limit},return_results=True,show_progress=True,)match = response[0].matches[0].tags["answer"]return match更多可参考:Jina 轻松学 —— 用 Jina + Streamlit 极速搭建搜索应用
7、连接 UI 和 Flow
使用 flow.block() 保持端口打开:
# question = Document(text="Can I catch COVID from my cat?")
# with flow:
# results = flow.search(question)# print(results[0].matches[0].tags["answer"])with flow:flow.block()再次运行后端代码:
python app.py在新终端中,运行前端代码:
streamlit frontend.py这样一来,一个由神经搜索 (Neural Search) 技术驱动的智能问答机器人,就搞定了!
进阶操作:拆分数据集 & 微调模型
截止目前,问答机器人输出的答案都是大段文本,包含了众多的上下文内容。在实际使用中,用户更希望只输出有用且相关的「句子」。
借助 Jina Hub 上的 Executor--Sentencizer,我们可以把数据集中的「段落」拆分成「句子」。
此外,这个教程中使用的预训练模型,并不是专门为医学问题创建的。为了提高性能,我们可以借助 Finetuner进行微调。
以上就是我们本期教程的全部内容,完整 demo 请访问 Here。
快动动小手,开发一个你自己的智能问答机器人吧!
开发者们问 Jina
Q1:开发过程出现报错或 Bug,如何解决?
A:访问 GitHub Repo 在对应的产品下提交 Issue 或 PR
Q2:如何加入社区、参与讨论?
A:我们目前支持 Slack 社区以及微信公众号社群:
Slack:英文社区,与来自全球的 Jina 用户探讨最新的应用场景及技术发展趋势。
微信群:中文社区,结识更多国内同行,探索 Jina 本土化应用场景。私信小助手获取群入口。
Q3:如何获取社区支持,宣发个人项目?
A:私信小助手,我们将依据项目情况及开发者需求,帮助开发者在社区提高个人影响力。
Q4:新手如何入门 Jina 全家桶?
A:从这些资料开始,了解 Jina 生态、开启你的神经搜索之旅:
Learning Portal(英文):从入门到精进,3 个等级的学习资料及课后测验,助力你成为神经搜索高手。