数仓实时数据同步 debezium
- 背景
- debezium 简介
- 架构
- 基本概念
- 例子
- Router
- 目前遇到的问题
背景
数据湖将源库的数据同步到hive数仓ods层,或直接在kafka中用于后面计算。源库包括mysql、postgresql、sqlserver、oracle,大部分是mysql数据库。当前采用的sqoop T+1全量或增量抽取的方式,时效性低,delete的数据可能无法被正确处理。
选择debezium的原因:数据源支持众多,使用的组件仅仅是kafka,需要进行的开发少;debezium使用kafka-connect,而且kafka 2.3版本以后 增加或修改一个任务、整个kafka-connect集群都会rebalance的情况得到优化;类似binlog的位点存储在kafka中,不再需要引入额外的存储也不需要关心位点;能保证at-least-once。
debezium 简介
架构

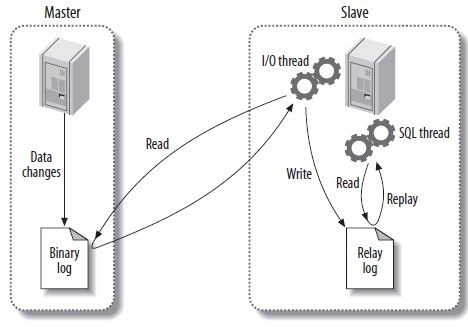
debezium 主要是一个kafka-connect的各种数据源同步的一种source实现。
数据存储在kafka中
基本概念
kafka-connect 独立于kafka的服务,本项目中采用集群的部署方式,依赖kafka实现协调。
connector 针对一个连接实例,模仿从库从主库获取实时binlog。 可支持mysql postgresql oracle sqlserver mongoDb 等多种数据源。connector运行在kafka-connect中
task 每个同步源数据的connector,只采用一个task(其他任务可以采用多可来保证高可用和提高并发),task是connector任务执行的最小单位。运行在kafka-connect中,作为一个线程。
例子
同步mysql binlog,检查源库的binlog设置,
--是否开启binlog
SELECT variable_value as "BINARY LOGGING STATUS (log-bin) ::"
FROM information_schema.global_variables WHERE variable_name='log_bin';
--是否开启行模式 row
SELECT variable_value as "binlog_format"
FROM information_schema.global_variables WHERE variable_name='binlog_format';
--是否补全所有字段 full
SELECT variable_value as "binlog_row_image"
FROM information_schema.global_variables WHERE variable_name='binlog_row_image';
#新建一个mysql的同步任务
#${connectIp}
#${name} connector名称
#${ip} mysql实例
#${port}
#${user}
#${password}
#${serverId} 模拟从库的servcer.id
#${serverName} 此名称会出现在topic中 ${serverName}.${schema}.${table}
#${tableList} db1.table1,db2.table1,db2.table2
#${kafka} ip:9092,ip:9092 如果服务器较多随机写三个足够
#${historyTopic} 存储ddl的topic名称,debezium内部使用curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" ${connectIp}:8083/connectors/ \
-d '{ "name": "${name}", "config":{"connector.class":"io.debezium.connector.mysql.MySqlConnector","tasks.max":"1","database.hostname":"${ip}","database.port":"${port}","database.user":"${user}","database.password":"${password}","database.server.id":"${serverId}","database.server.name":"${serverName}","table.whitelist":"${tableList}","database.history.kafka.bootstrap.servers":"${kafka}","snapshot.mode":"schema_only","tombstones.on.delete":"false","database.history.kafka.topic":"${historyTopic}","database.history.skip.unparseable.ddl":"true","key.converter":"org.apache.kafka.connect.json.JsonConverter","value.converter":"org.apache.kafka.connect.json.JsonConverter","key.converter.schemas.enable":"false","value.converter.schemas.enable":"false","transforms":"unwrap","transforms.unwrap.type":"io.debezium.transforms.ExtractNewRecordState","transforms.unwrap.drop.tombstones":"false","transforms.unwrap.delete.handling.mode":"rewrite","transforms.unwrap.add.fields":"source.ts_ms"} }'
主要参数,还有很多其他的参数未列出
"name": "${name}","config": {"connector.class": "io.debezium.connector.mysql.MySqlConnector","tasks.max": "1","database.hostname": "${ip}","database.port": "${port}","database.user": "${user}","database.password": "${password}","database.server.id": "${serverId}","database.server.name": "${serverName}","table.whitelist": "${tableList}","database.history.kafka.bootstrap.servers": "${kafka}","snapshot.mode": "schema_only", //选择schema_only,从当前最新的位点开始同步,不需要冷数据,冷数据用其他方式抽取"tombstones.on.delete": "false","database.history.kafka.topic": "${historyTopic}","database.history.skip.unparseable.ddl": "true","key.converter": "org.apache.kafka.connect.json.JsonConverter","value.converter": "org.apache.kafka.connect.json.JsonConverter","key.converter.schemas.enable": "false","value.converter.schemas.enable": "false","transforms": "unwrap","transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState", //简化数据结构"transforms.unwrap.drop.tombstones": "false","transforms.unwrap.delete.handling.mode": "rewrite","transforms.unwrap.add.fields": "source.ts_ms" //增加时间戳字段用于}
}
kafka中的数据
{"id":1004,"first_name":"10","last_name":"1","email":"1","__source_ts_ms":1596450910000,"__deleted":"false"} //key是 {"id":1004}
{"id":1004,"first_name":"11","last_name":"1","email":"1","__source_ts_ms":1596451124000,"__deleted":"false"} //key是 {"id":1004}
{"id":1004,"first_name":"101","last_name":"1","email":"1","__source_ts_ms":1596606837000,"__deleted":"false"} //key是 {"id":1004}
{"id":1004,"first_name":"102","last_name":"1","email":"1","__source_ts_ms":1596606992000,"__deleted":"false"} //key是 {"id":1004}
__source_ts_ms 和__deleted是配置产生的字段
Router
分表的合并,将分表数据写到一个topic
"transforms":"Reroute,unwrap",
"transforms.unwrap.type":"io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones":"false",
"transforms.unwrap.delete.handling.mode":"rewrite","transforms.unwrap.add.fields":"source.ts_ms",
"transforms.Reroute.type": "io.debezium.transforms.ByLogicalTableRouter", "transforms.Reroute.topic.regex": "dbserver1\\..*",
"transforms.Reroute.topic.replacement": "dbserver1.all"
结果
key的值{"id":1004,"__dbz__physicalTableIdentifier":"dbserver1.inventory.customers"}===============value的值{"id":1004,"first_name":"204","last_name":"1","email":"1","__source_ts_ms":1596773158000,"__deleted":"false"}
__dbz__physicalTableIdentifier是自动增加的一个key字段来区别表,字段名称可以改,也可以从topic名称中匹配获取
目前遇到的问题
- 需要同步的表比较多,kafka topic多,对性能影响比较大。
- kakfa 新版本kakfa-manager等基本都不能很好支持,需要自己开发来监控和管理kafka,connect集群也要自己开发监控。
- 数据同步后如何到hive数仓更好,hbase kudu hudi 或者直接hdfs。