配置Hadoop_1
- 1. 配置jdk
- 2. 配置Hadoop
- 3.完全分布式运行环境(配置集群)
- 3.1 编写集群分发脚本xsync
- 3.2 rsync远程同步工具
- 3.3 xsync集群分发脚本
- 3.4 SSH无密登录配置
- 3.5集群配置
- 3.6 配置历史服务器
- 3.7 配置日志的聚集
- 3.8 两个常用脚本
- asd
1. 配置jdk
上传jar包

[gpb@hadoop102 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
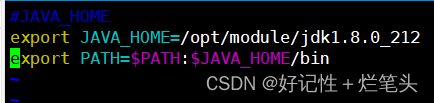
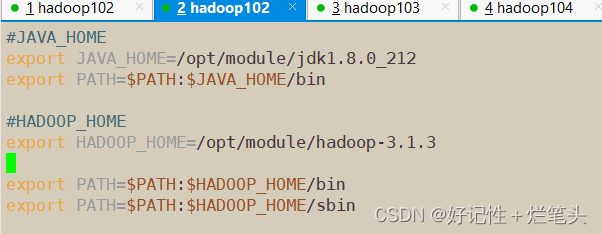
配置jdk环境变量
2. 配置Hadoop
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
hadoop文件
etc:大量的配置信息
sbin:启动集群的相关文件
lib:本地动态链接库
include :头文件.h
bin:hdfs,yarn,mapred
链接: hadoop下载
3.完全分布式运行环境(配置集群)
3.1 编写集群分发脚本xsync
1)scp(secure copy)安全拷贝
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
scp -r $pdir/$fname $user@$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
推过去
scp -r jdk1.8.0_212/ gpb@hadoop104:/home/gpb/module
拉过来
scp -r gpb@hadoop102:/home/gpb/module/hadoop-3.1.3 ./3.2 rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
(1)基本语法
rsync -av $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
选项 功能
-a 归档拷贝
-v 显示复制过程
(2)案例实操
(a)删除hadoop103中/opt/module/hadoop-3.1.3/wcinput
[atguigu@hadoop103 hadoop-3.1.3]$ rm -rf wcinput/
(b)同步hadoop102中的/opt/module/hadoop-3.1.3到hadoop103
[atguigu@hadoop102 module]$ rsync -av hadoop-3.1.3/ atguigu@hadoop103:/opt/module/hadoop-3.1.3/
rm -rf wcinput/ wcoutput/
rsync -av hadoop-3.1.3/ gpb@hadoop103:/home/gpb/module/hadoop-3.1.3/
3.3 xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:
rsync -av /opt/module atguigu@hadoop103:/opt/
(b)期望脚本:
xsync要同步的文件名称
(c)期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径)
[atguigu@hadoop102 ~]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/atguigu/.local/bin:/home/atguigu/bin:/opt/module/jdk1.8.0_212/bin
(3)脚本实现
(a)在/home/atguigu/bin目录下创建xsync文件
[atguigu@hadoop102 opt]$ cd /home/atguigu
[atguigu@hadoop102 ~]$ mkdir bin
[atguigu@hadoop102 ~]$ cd bin
[atguigu@hadoop102 bin]$ vim xsync
在该文件中编写如下代码
#!/bin/bash#1. 判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
done(b)修改脚本 xsync 具有执行权限
[atguigu@hadoop102 bin]$ chmod 777 xsync
(c)测试脚本
[atguigu@hadoop102 ~]$ xsync /home/atguigu/bin
(d)将脚本复制到/bin中,以便全局调用
[atguigu@hadoop102 bin]$ sudo cp xsync /bin/
(e)同步环境变量配置(root所有者)
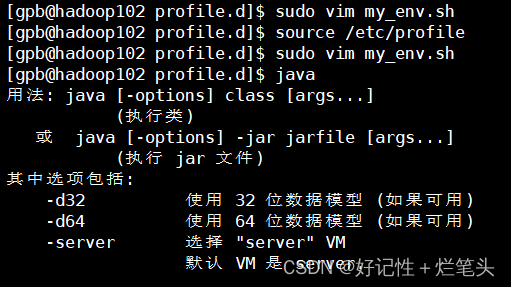
[atguigu@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh
注意:如果用了sudo,那么xsync一定要给它的路径补全。
让环境变量生效
[atguigu@hadoop103 bin]$ source /etc/profile
[atguigu@hadoop104 opt]$ source /etc/profile
3.4 SSH无密登录配置
1)配置ssh
(1)基本语法
ssh另一台电脑的IP地址
(2)ssh连接时出现Host key verification failed的解决方法
[atguigu@hadoop102 ~]$ ssh hadoop103
如果出现如下内容
Are you sure you want to continue connecting (yes/no)?
输入yes,并回车
(3)退回到hadoop102
[atguigu@hadoop103 ~]$ exit
[gpb@hadoop102 ~]$ ssh hadoop103
gpb@hadoop103's password:
Last login: Sat Jul 15 14:51:25 2023
[gpb@hadoop103 ~]$ exit
登出
Connection to hadoop103 closed.[gpb@hadoop102 ~]$ pwd
/home/gpb
//查看隐藏文件
[gpb@hadoop102 ~]$ ls -al
总用量 40
drwx------. 17 gpb gpb 4096 7月 15 15:30 .
drwxr-xr-x. 3 root root 17 7月 14 23:25 ..
drwxr-xr-x. 4 gpb gpb 39 7月 14 22:25 .mozilla
drwx------. 2 gpb gpb 25 7月 15 15:13 .ssh
[gpb@hadoop102 ~]$ [gpb@hadoop102 .ssh]$ pwd
/home/gpb/.ssh
[gpb@hadoop102 .ssh]$ ssh-keygen -t rsa生成公钥和私钥
[atguigu@hadoop102 .ssh]$ pwd
/home/atguigu/.ssh
[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
ssh hadoop 到hadoop103
3.5集群配置

[atguigu@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop
[atguigu@hadoop102 hadoop]$ vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop102:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><!-- 配置HDFS网页登录使用的静态用户为atguigu --><property><name>hadoop.http.staticuser.user</name><value>atguigu</value></property>
</configuration>
[atguigu@hadoop102 hadoop]$ vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value></property>
</configuration>
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property>
</configuration>
[atguigu@hadoop102 hadoop]$ vim mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
如果有的集群组件为启动,就多试几次(有时候没启动起来)。
链接: 解决无法启动namenode
3.6 配置历史服务器
[gpb@hadoop102 hadoop-3.1.3]$ cd $HADOOP_HOME/etc/hadoop
[gpb@hadoop102 hadoop]$ vim mapred-site.xml
[gpb@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml[gpb@hadoop102 hadoop]$ mapred --daemon start historyserverhttp://hadoop102:19888/jobhistory
3.7 配置日志的聚集
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
<!-- 开启日志聚集功能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property> <name>yarn.log.server.url</name> <value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
[atguigu@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
[atguigu@hadoop103 hadoop-3.1.3]$ mapred --daemon stop historyserver
[atguigu@hadoop103 ~]$ start-yarn.sh
[atguigu@hadoop102 ~]$ mapred --daemon start historyserver
3.8 两个常用脚本
[atguigu@hadoop102 ~]$ cd /home/atguigu/bin
[atguigu@hadoop102 bin]$ vim myhadoop.sh
#!/bin/bashif [ $# -lt 1 ]
thenecho "No Args Input..."exit ;
ficase $1 in
"start")echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)echo "Input Args Error..."
;;
esac
[atguigu@hadoop102 ~]$ cd /home/atguigu/bin
[atguigu@hadoop102 bin]$ vim jpsall
#!/bin/bashfor host in hadoop102 hadoop103 hadoop104
doecho =============== $host ===============ssh $host jps
done
[atguigu@hadoop102 bin]$ chmod 777 myhadoop.sh
[atguigu@hadoop102 bin]$ chmod 777 jpsall
[atguigu@hadoop102 ~]$ xsync /home/gpb/bin/
asd
grep “password is” /var/log/mysqld.log
2023-06-08T08:14:35.698981Z 1 [Note] A temporary password is generated for root@localhost: q-HaZ,acq9/L
q-HaZ,acq9/L
ALTER USER ‘root’@‘localhost’ IDENTIFIED BY ‘000000’;
grant all privileges on . to root@‘%’ identified by ‘000000’;
systemctl restart mysqld