前面已完成VMware虚拟机安装与配置(参考前一篇Hadoop完全分布式集群——VMware虚拟机安装与配置_夏雨和阳阳的博客-CSDN博客),下面将进行Hadoop 配置。
一、slave1、slave2节点配置修改
slave1、slave2节点都需要进行以下操作:
1.开启虚拟机,输入命令:
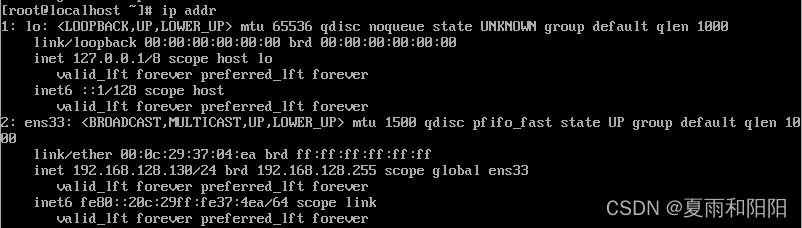
[root@slave1 ~]#ip addr
[root@slave2 ~]#ip addr
2.修改slave1、slave2虚拟机的IP
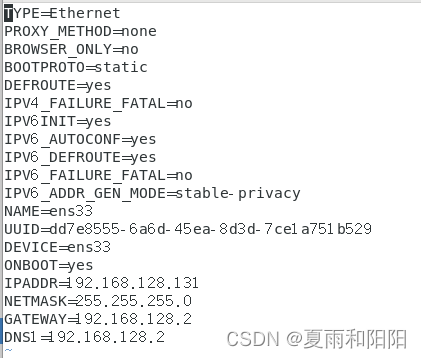
[root@slave1 ~]#vi /etc/sysconfig/network-scripts/ifcfg-ens33
[root@slave12 ~]#vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改slave1为IPADDR=192.168.128.131,修改slave2为IPADDR=192.168.128.132。
3.修改slave1、slave2虚拟机的主机名
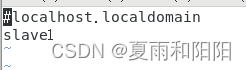
[root@slave1 ~]#vi /etc/hostname
[root@slave2 ~]#vi /etc/hostname
主节点为 master,子节点分别为 slave1、slave2。
4.slave1、slave2虚拟机重启网络服务
[root@slave1 ~]#service network restart
[root@slave2 ~]#service network restart
5.查看slave1、slave2虚拟机 IP、主机名是否修改
[root@slave1 ~]#ip addr
[root@slave2 ~]#ip addr
6.reboot 重启slave1、slave2虚拟机。
root@slave1 ~]#reboot
root@slave2 ~]#reboot
二、 配置master、slave1、slave2虚拟机无密码登录
1.配置 IP 映射(master、slave1、slave2每个节点都需修改)
[root@master ~]#vi /etc/hosts
[root@slave1 ~]#vi /etc/hosts
[root@slave2 ~]#vi /etc/hosts
依次添加如下内容:
192.168.128.130 master
192.168.128.131 slave1
192.168.128.132 slave2
2.配置 SSH 无密码登录
(1) 使用 ssh-keygen 产生公钥与私钥对。
在master虚拟机输入命令:
[root@master ~]# ssh-keygen -t rsa
执行过程中需要按三次 Enter 键。
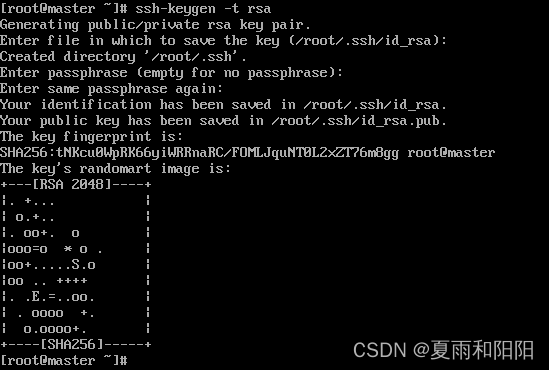
生成私有密钥 id_rsa 和公有密钥 id_rsa.pub 两个文件。ssh-keygen 用来生成 RSA类型的密钥以及管理该密钥,参数“-t”用于指定要创建的 SSH 密钥的类型为RSA。
(2)用 ssh-copy-id 将公钥复制到slave1、slave2虚拟机中
[root@master ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub slave1 //依次输入 yes,123456(root 用户的密码)
[root@master ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub slave2 //依次输入 yes,123456(root 用户的密码)
(3)验证是否设置无密码登录
依次输入:
[root@master ~]# ssh slave1 //下图表示无密码登陆slave1成功

[root@master ~]# exit //下图表示退出slave1

用同样的方法验证slave2是否设置无密码登录。
(4)配置宿主机SSH 无密码登录master、slave1、slave2虚拟机
为了便于连接和操作master、slave1、slave2虚拟机,也需要配置SSH 无密码登录。在宿主机上操作如下:
[root@localhost~]#vi /etc/hosts
依次添加如下内容:
192.168.128.130 master
192.168.128.131 slave1
192.168.128.132 slave2
[root@localhost~]# ssh-keygen -t rsa
执行过程中需要按三次 Enter 键。
[root@localhost~]# ssh-copy-id -i /root/.ssh/id_rsa.pub master //依次输入 yes,123456(root 用户的密码)
[root@localhost ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub slave1 //依次输入 yes,123456(root 用户的密码)
[root@localhost ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub slave2 //依次输入 yes,123456(root 用户的密码)
[root@localhost ~]# ssh master
[root@localhost ~]# ssh slave1
[root@localhost ~]# ssh slave1
三、安装 jdk(每个节点都需安装)
用的是JDK1.8.0_131版本(jdk-8u131-linux-x64.tar.gz),有需要从百度网盘中下载。
下载链接:https://pan.baidu.com/s/1P2fkRonIVO-DZMNKNgCCKA
提取码:ml01
1. 解压并安装/opt 目录
[root@master opt]#tar -zxvf jdk-8u131-linux-x64.tar.gz

2.修改环境变量
[root@master ~]#vi /etc/profile
添加如下内容:
export JAVA_HOME=/opt/jdk1.8.0_131
export PATH=$PATH:$JAVA_HOME/bin
[root@master ~]#source /etc/profile //使配置生效
3.验证 JDK 是否配置成功
[root@master ]#java -version

4.将master上的配置好的JDK分发到slave1、slave2上
[root@master ]#scp -r /opt/jdk1.8.0_131 root@slave1:/opt
[root@master ]#scp -r /opt/jdk1.8.0_131 root@slave2:/opt
5.环境变量配置生效
[root@slave1 ~]#source /etc/profile
[root@slave2 ~]#source /etc/profile
6.验证 slave1、slave2中的JDK 是否配置成功
[root@slave1 ~]#java -version
[root@slave2 ~]#java -version
四、 Hadoop2.7.7 安装与配置
用的是Hadoop2.7.7版本(hadoop-2.7.7.tar.gz),有需要从百度网盘中下载。
下载链接:https://pan.baidu.com/s/13Mc6YsbHiZPkbozJUMuahg
提取码:mt1s
1.解压并安装/usr/local目录(主节点进行)
[root@master ]#tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local
解压后即可看到/usr/local/hadoop-2.7.7文件夹。
2.配置 Hadoop
(1)进入目录
[root@master ]#cd /usr/local/hadoop-2.7.7/etc/hadoop
依次修改以下配置文件(使用 vi 命令对文件进行修改 如 vi core-site.xml),修改完按ESC键,输入:wq!保存退出。
注:文件中存在<configuration></configuration>,配置放入其中,且只保留一组的<configuration></configuration>。
(2)修改core-site.xml
[root@master hadoop]#vi xore-site.xml
添加如下内容:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.7/hdfs/tmp</value>
</property>
</configuration>
(3)修改hadoop-env.sh
[root@master hadoop]#vi hadoop-env.sh
修改如下内容:
# The java implementation to use.
export JAVA_HOME=/opt/jdk1.8.0_131
(4)修改hdfs-site.xml
[root@master hadoop]#vi hdfs-site.xml
添加如下内容:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop-2.7.7/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop-2.7.7/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
(5)修改mapred-site.xml
此目录下并没有mapred-site.xml,须复制mapred-site.xml.template生成。命令如下:
[root@master hadoop]#cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]#vi mapred-site.xml
添加如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- jobhistory properties -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
(6)修改yarn-site.xml
[root@master hadoop]#vi yarn-site.xml
添加如下内容:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/usr/local/hadoop-2.7.7/yarn/local</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/usr/local/hadoop-2.7.7/yarn/logs</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs/</value>
<description>URL for job history server</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.application.classpath </name>
<value>
/usr/local/hadoop-2.7.7/etc/hadoop:/usr/local/hadoop-2.7.7/share/hadoop/common/lib/*:/usr/local/hadoop-2.7.7/share/hadoop/common/*:/usr/local/hadoop-2.7.7/share/hadoop/hdfs:/usr/local/hadoop-2.7.7/share/hadoop/hdfs/lib/*:/usr/local/hadoop2.7.7/share/hadoop/hdfs/*:/usr/local/hadoop-2.7.7/share/hadoop/mapreduce/lib/*:/usr/local/hadoop-2.7.7/share/hadoop/mapreduce/*:/usr/local/hadoop-2.7.7/share/hadoop/yarn:/usr/local/hadoop-2.7.7/share/hadoop/yarn/lib/*:/usr/local/hadoop-2.7.7/share/hadoop/yarn/*
</value>
</property>
</configuration>
(7)修改yarn-env.sh
[root@master hadoop]#vi yarn-env.sh
修改如下内容:
# some Java parameters
export JAVA_HOME=/opt/jdk1.8.0_131
(8)修改workers
[root@master hadoop]#vi workers
删除原有 localhost,添加:
master
slave1
slave2
(9)修改slaves
[root@master hadoop]#vi slaves
删除原有 localhost,添加:
slave1
slave2
3.拷贝 hadoop 安装文件到集群 slave1、slave2 节点
[root@master hadoop]#scp -r /usr/local/hadoop-2.7.7 root@slave1:/usr/local
[root@master hadoop]#scp -r /usr/local/hadoop-2.7.7 root@slave2:/usr/local
4.在master、slave1、slave2分别修改配置文件并生效
[root@master ~]#vi /etc/profile //添加 Hadoop 路径
添加以下内容:
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin
[root@master ~]#source /etc/profile //配置生效
slave1、slave2 节点操作同上。
5.master节点上格式化 NameNode
[root@master ~]#cd /usr/local/hadoop-2.7.7/bin
[root@master ~]#./hdfs namenode -format
注:hadoop 集群只需要格式化一次即可,后续启动无需格式化。
6.master主节点启动Hadoop
[root@master ~]#cd /usr/local/hadoop-2.7.7sbin
[root@master ~]#./start-dfs.sh
[root@master ~]#./start-yarn.sh
[root@master ~]#./mr-jobhistory-daemon.sh start historyserver
7.使用 jps,查看进程
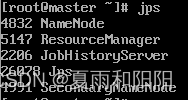
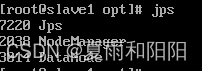
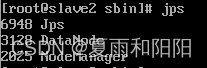
8.slave1、slave2子节点没有datanode进程
此时须重启子节点,进入子节点对应的sbin目录,执行:
[root@slave1 ~]#cd /usr/local/hadoop-2.7.7/sbin
[root@slave1 sbin]#hadoop-daemon.sh start datanode
[root@slave1 sbin]#hadoop-daemon.sh start tasktracker(该命令可能会失效,所以失效的话就跳过该条命令)
使用jps查看进程已正常显示datanode进程。
9.在宿主机上添加映射
[root@localhost ~]#vi \etc\hosts //添加 IP 映射
添加如下内容:
192.168.128.130 master
192.168.128.131 slave1
192.168.128.132 slave2
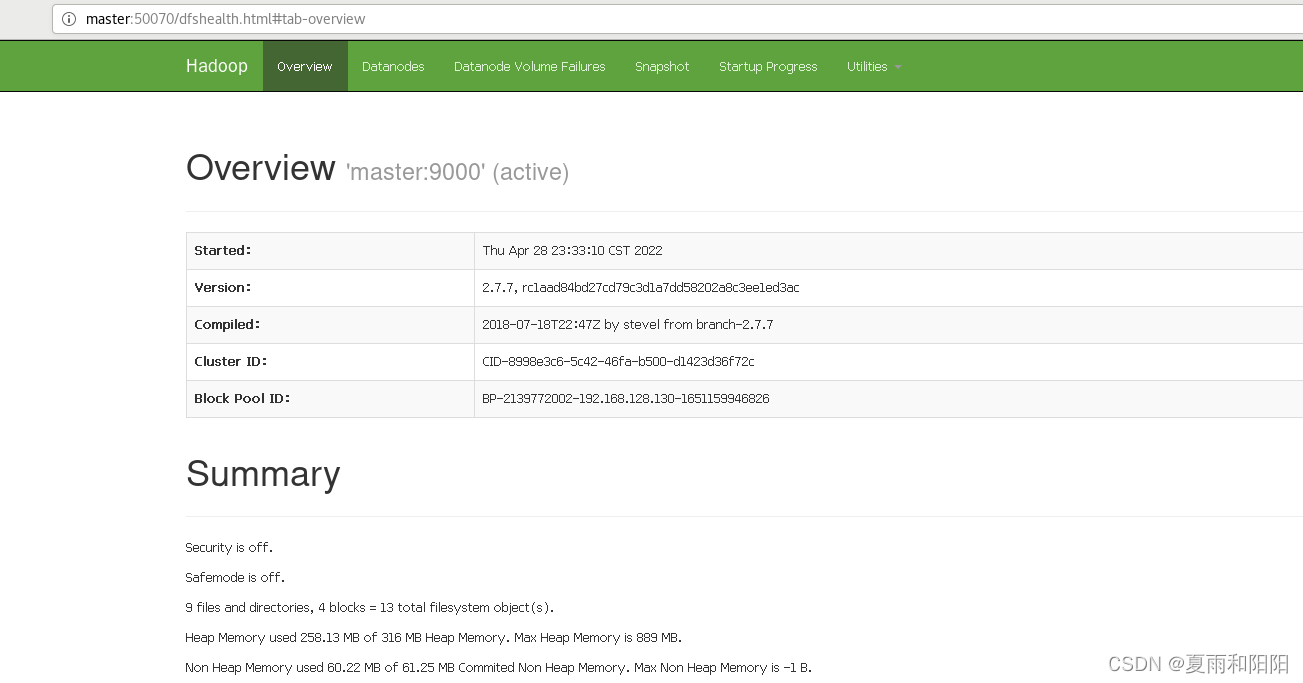
10.在宿主机上用浏览器查看
查看HDFS的NameNode:http://master:50070
查看YARN的ResourceManager:http://master:8088