文章目录
- chatgpt检索插件简介
- 加入等待名单
- 介绍
- 目录描述
- 关于
- 插件
- API
- 检索插件
- 内存功能
- 安全
- API终端接口
- 快速启动
- 扩展阅读
- TIPS1:bearer_token
chatgpt检索插件简介
引自官方:项目git地址
ChatGPT检索插件允许您通过用日常语言提问来轻松搜索和查找个人或工作文档。
加入等待名单
首先要加入官方的等待名单:https://openai.com/waitlist/plugins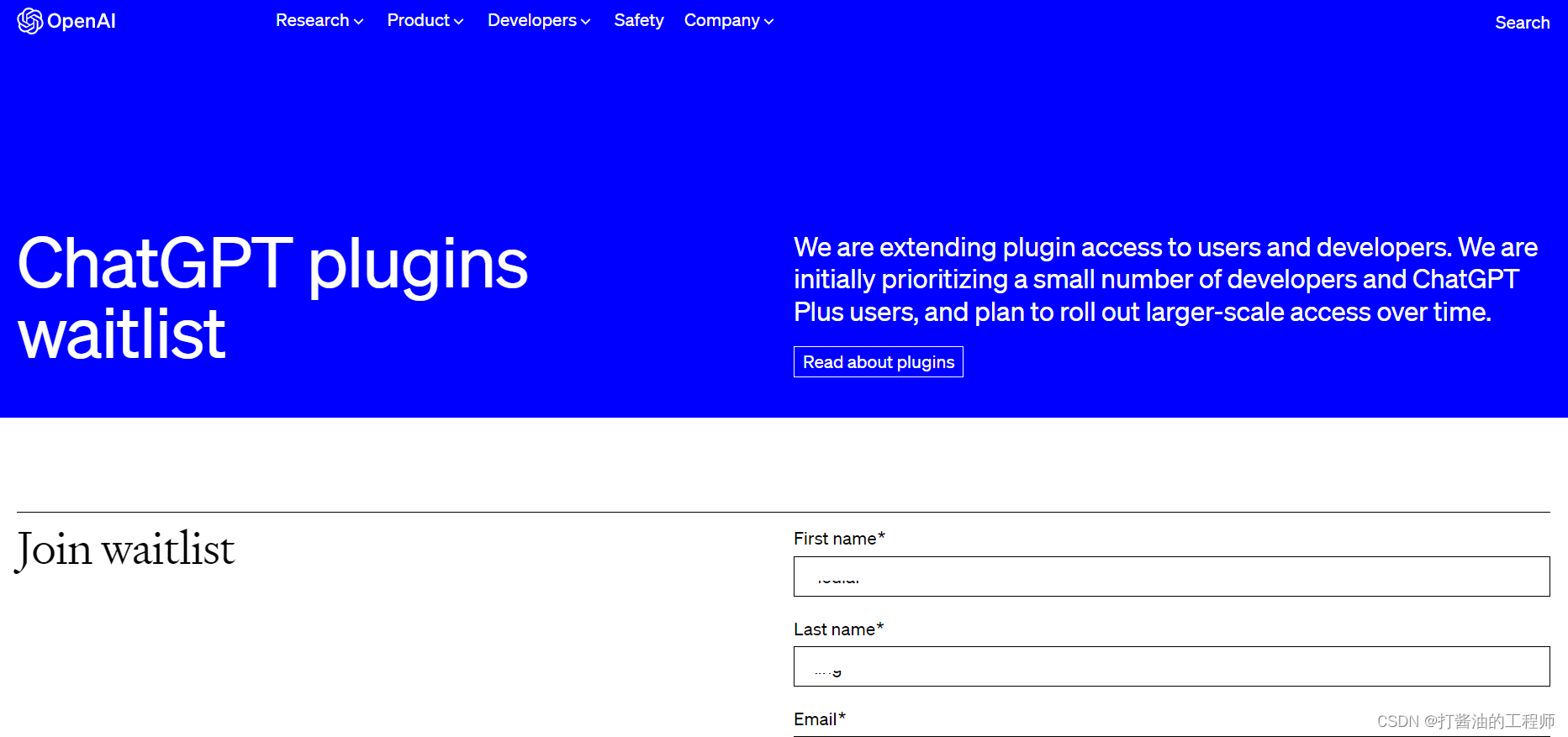
填写等待list的申请清单:

官方文档中给出了一个可以访问2018年至2022年联合国年度报告的检索插件的示例视频。
介绍
ChatGPT检索插件库为使用自然语言查询进行个人或组织文档的语义搜索和检索提供了灵活的解决方案。存储库分为几个目录:
目录描述
数据存储:包含使用各种矢量数据库提供程序存储和查询文档嵌入的核心逻辑。
示例:包括示例配置、身份验证方法和特定于提供程序的示例。
models:包含插件使用的数据模型,例如文档和元数据模型。
脚本:提供用于处理和上载来自不同数据源的文档的脚本。
server:包含主要的FastAPI服务器实现。
services:包含用于分块、元数据提取和PII检测等任务的实用程序服务。
tests:包括各种矢量数据库提供程序的集成测试。
well-known:存储插件清单文件和OpenAPI架构,它们定义了插件配置和API规范。
自述文件提供了有关如何设置、开发和部署ChatGPT检索插件的详细信息。
关于
插件
插件是专门为ChatGPT等语言模型设计的聊天扩展,使它们能够访问最新信息、运行计算或响应用户请求与第三方服务交互。它们释放了广泛的潜在用例,并增强了语言模型的功能。
开发人员可以通过网站公开API并提供描述API的标准化清单文件来创建插件。ChatGPT使用这些文件,并允许AI模型对开发人员定义的API进行调用。
插件包括:
API
API模式(OpenAPI JSON或YAML格式)
为插件定义相关元数据的清单(JSON文件)
检索插件已经包含所有这些组件。阅读这里的聊天插件博客文章,并在这里找到文档。
检索插件
这是ChatGPT的一个插件,可以对个人或组织文档进行语义搜索和检索。它允许用户通过用自然语言提问或表达需求,从文件、笔记或电子邮件等数据源中获取最相关的文档片段。企业可以使用此插件通过ChatGPT向员工提供内部文档。
该插件使用OpenAI的text-embedding-ad-002嵌入模型来生成文档块的嵌入,然后使用后端的矢量数据库来存储和查询它们。作为一个开源和自托管的解决方案,开发人员可以部署自己的检索插件并在ChatGPT中注册。检索插件支持多个矢量数据库提供程序,允许开发人员从列表中选择他们喜欢的一个。
FastAPI服务器公开插件的端点,用于追加销售、查询和删除文档。用户可以通过使用元数据过滤器按来源、日期、作者或其他条件来细化搜索结果。该插件可以托管在任何支持Docker容器的云平台上,如Fly.io、Heroku或Azure Container Apps。为了使用最新的文档更新矢量数据库,插件可以连续处理和存储来自各种数据源的文档,使用传入的webhook来启动和删除端点。像Zapier或Make这样的工具可以帮助根据事件或时间表配置网络挂钩。
内存功能
检索插件的一个显著功能是它能够为ChatGPT提供内存。通过利用插件的upstart端点,ChatGPT可以将对话中的片段保存到向量数据库中,以供以后参考(只有在用户提示时)。该功能允许ChatGPT记住并检索以前对话中的信息,从而有助于获得更具上下文意识的聊天体验。在此处了解如何配置具有内存的检索插件。
安全
检索插件允许ChatGPT搜索内容的矢量数据库,然后将最佳结果添加到ChatGPT会话中。这意味着它没有任何外部影响,主要的风险考虑是数据授权和隐私。开发人员只应将他们有授权的内容添加到他们的检索插件中,并且他们可以在用户的ChatGPT会话中显示这些内容。您可以从多种不同的身份验证方法中进行选择,以确保插件的安全(更多信息请点击此处)。
API终端接口
检索插件是使用FastAPI构建的,FastAPI是一个使用Python构建API的web框架。FastAPI允许轻松开发、验证和记录API端点。请在此处查找FastAPI文档。
使用FastAPI的好处之一是使用Swagger UI自动生成交互式API文档。当API在本地运行时,Swagger UI位于<local_host_url,即。http://0.0.0.0:8000>/文档可以用来与API端点交互,测试它们的功能,并查看预期的请求和响应模型。
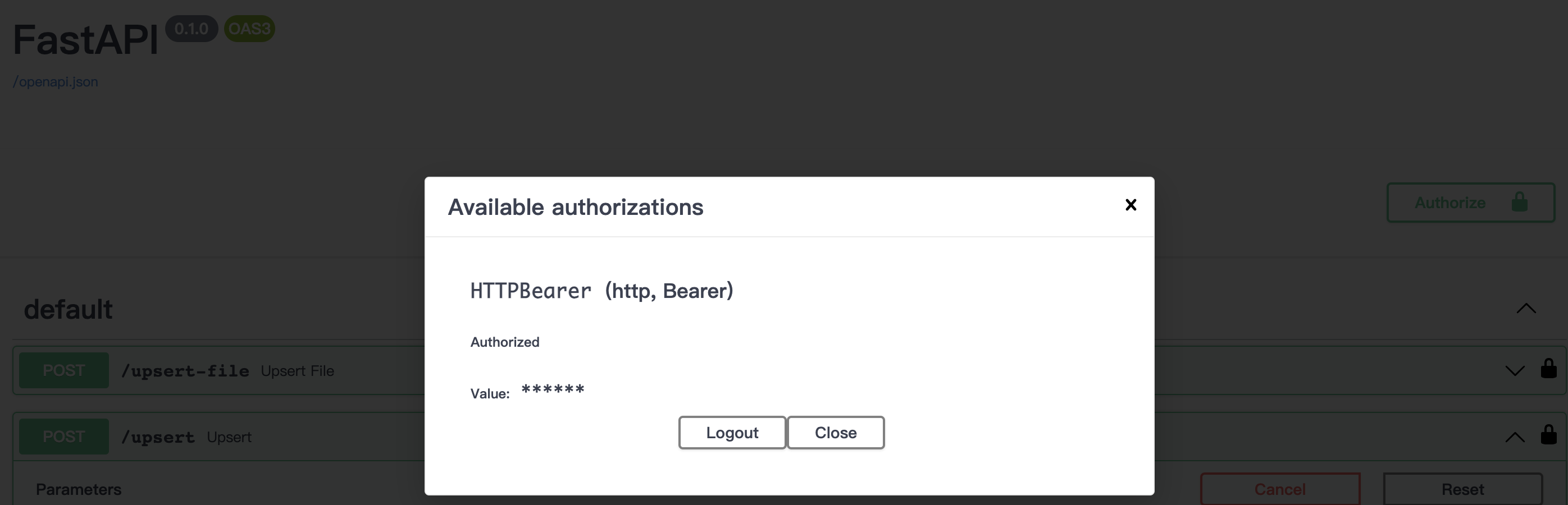
该插件公开了以下端点,用于从矢量数据库中追加、查询和删除文档。所有请求和响应都是JSON格式的,并且需要一个有效的承载令牌作为授权头。
/upstart:这个端点允许上传一个或多个文档,并将它们的文本和元数据存储在矢量数据库中。这些文档被分成大约200个令牌的块,每个令牌都有一个唯一的ID。端点希望在请求主体中有一个文档列表,每个文档都有文本字段以及可选的ID和元数据字段。元数据字段可以包含以下可选子字段:source、source_id、url、created_at和author。端点返回插入文档的ID列表(如果最初没有提供ID,则会生成ID)。/upstart文件:该端点允许上传单个文件(PDF、TXT、DOCX、PPTX或MD),并将其文本和元数据存储在矢量数据库中。该文件被转换为纯文本,并被拆分为大约200个令牌的块,每个令牌都有一个唯一的ID。端点返回一个列表,其中包含插入文件的生成ID。/query:这个端点允许使用一个或多个自然语言查询和可选的元数据过滤器来查询向量数据库。端点期望在请求主体中有一个查询列表,每个查询都包含一个查询、可选的筛选器和top_k字段。filter字段应该包含以下子字段的子集:source、source_id、document_id、url、created_at和author。top_k字段指定给定查询返回的结果数,默认值为3。端点返回一个对象列表,每个对象都包含给定查询的最相关文档块的列表,以及它们的文本、元数据和相似性得分。/delete:此端点允许使用一个或多个文档的ID、元数据过滤器或delete_all标志从矢量数据库中删除它们。端点要求在请求正文中至少包含以下参数之一:id、filter或delete_all。ids参数应该是要删除的文档ID的列表;具有这些IDS的文档的所有文档块都将被删除。filter参数应该包含以下子字段的子集:source、source_id、document_id、url、created_at和author。delete_all参数应该是一个布尔值,指示是否从矢量数据库中删除所有文档。端点返回一个布尔值,指示删除是否成功。
通过在本地运行应用程序并导航到,可以找到请求和响应模型的详细规范和示例http://0.0.0.0:8000/openapi.json,或在此处的OpenAPI架构中。请注意,OpenAPI架构只包含/query端点,因为这是ChatGPT需要访问的唯一函数。这样,ChatGPT只能使用该插件基于自然语言查询或需求检索相关文档。然而,如果开发人员还想让ChatGPT能够记住以后的事情,他们可以使用/upsert端点将对话中的片段保存到向量数据库中。可以在这里找到一个清单和OpenAPI模式的示例,该模式允许ChatGPT访问/upsert端点。
要包含自定义元数据字段,请在此处编辑DocumentMetadata和DocumentMetadataFilter数据模型,并在此处更新OpenAPI架构。您可以通过在本地运行应用程序,复制在http://0.0.0.0:8000/sub/openapi.json,并使用Swagger Editor将其转换为YAML格式。或者,您可以将openapi.yaml文件替换为openapi.json文件。
快速启动
按照以下步骤快速设置并运行ChatGPT检索插件:
这里默认的是Python3.8版本,推荐3.10以上版本。
克隆存储库:git clone https://github.com/openai/chatgpt-retrieval-plugin.git
导航到克隆的存储库目录:cd /path/to/chatgpt-retrieval-plugin
安装poem:pip install poetry
你必须先创建一个pyproject.toml。进入你的项目文件夹,运行poetry初始化并按照说明进行操作。
作为另一种选择,你可以运行poetry new myproject来创建一个基本的文件夹结构和pyproject.toml。还可以查看文档。
进入我的项目目录:cd myproject
使用Python 3.10创建一个新的虚拟环境:poetry env use python
Creating virtualenv myproject-0Nxyu3rv-py3.8 in C:\Users\86131\AppData\Local\pypoetry\Cache\virtualenvsUsing virtualenv: C:\Users\86131\AppData\Local\pypoetry\Cache\virtualenvs\myproject-0Nxyu3rv-py3.8
激活虚拟环境:poetry shell
安装应用程序依赖项:poetry install
设置所需的环境变量:
your_datastore是你的主机上安装的数据库。如redis等。
export DATASTORE=<your_datastore>
export BEARER_TOKEN=<your_bearer_token>
export OPENAI_API_KEY=<your_openai_api_key>
<Add the environment variables for your chosen vector DB here>
本地运行API:poetry run start
访问API文档:http://0.0.0.0:8000/docs并测试API端点(确保添加您的承载令牌)。
有关设置、开发和部署ChatGPT检索插件的更多详细信息,请参阅完整开发部分。
扩展阅读
【尝鲜版】ChatGPT插件开发指南
TIPS1:bearer_token
Bearer认证的核心是Token,Bearer验证中的凭证称为BEARER_TOKEN,或者是access_token,它的颁发和验证完全由我们自己的应用程序来控制,而不依赖于系统和Web服务器,可以使用https://jwt.io/生成。

例子:
HEADER:ALGORITHM & TOKEN TYPE ❗ 🔄{"alg": "HS256","typ": "JWT"}PAYLOAD:DATA ❗ 🔄{"sub": "1234567890","name": "John Doe","iat": 1516239022}VERIFY SIGNATURE ❗ 🔄HMACSHA256(base64UrlEncode(header) + "." +base64UrlEncode(payload),your-256-bit-secret) secret base64 encoded
生成的bearer_token:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c