前面说过如何用自己的UCF101数据集训练3D识别模型video-caffe,那么怎么制作自己的UCF101数据集呢?这个稍微有点复杂。
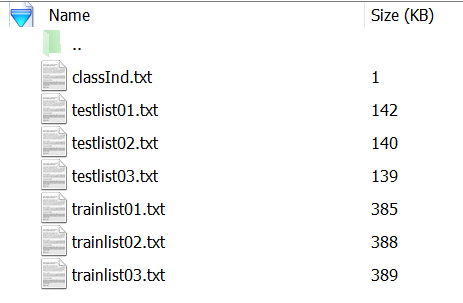
UCF101数据集其实是按101个动作类别分类了的短视频的集合,每类动作对应一个目录,每个目录下有很多avi格式的视频文件,我们需要制作自己的项目应用领域的UCF101格式的数据集时,可以像这样把项目应用的视频数据按动作分类这样分目录存放,一个目录对应一个动作,实际项目中一般不会有101种动作,比如有三种或者四种动作,那么对应就按三个或四个目录存放视频文件即可,然后写个shell脚本或者python脚本来生成模型所需的train和test视频数据文件的list文件,train和test的list文件的内容格式根据你所用的3D模型所需要的格式来写,如果模型直接支持UCF101的train/test list格式(从UCF101的trainlist.txt文件中摘取示例如下):
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01.aviApplyEyeMakeup/v_ApplyEyeMakeup_g01_c02.aviApplyEyeMakeup/v_ApplyEyeMakeup_g01_c03.avi...ApplyLipstick/v_ApplyLipstick_g01_c01.aviApplyLipstick/v_ApplyLipstick_g01_c02.aviApplyLipstick/v_ApplyLipstick_g01_c03.aviApplyLipstick/v_ApplyLipstick_g01_c04.avi...除了上面的数据文件(路径)的列表,还需要有个对应的定义class值的class_index.txt的文件:
1 ApplyEyeMakeup
2 ApplyLipstick
3 Archery
4 BabyCrawling
5 BalanceBeam
6 BandMarching
7 BaseballPitch
8 Basketball
9 BasketballDunk
10 BenchPress...很显然,解析这两个文件里的列表,就可以把avi数据文件和class值对应起来。
但是这样做稍显得有点麻烦,所以一般C3D模型在定义自己的train_list.txt和test_list.txt文件格式时进行了简化,直接把数据文件和class值的对应关系定义在一个文件里,也就是类似这样:
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01.avi 1
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c02.avi 1
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c03.avi 1...
ApplyLipstick/v_ApplyLipstick_g01_c01.avi 2
ApplyLipstick/v_ApplyLipstick_g01_c02.avi 2
ApplyLipstick/v_ApplyLipstick_g01_c03.avi 2
ApplyLipstick/v_ApplyLipstick_g01_c04.avi 2
...至于每个class值对应的具体的class类别名对模型来说根本不需要,这是调用模型进行识别的应用程序关心的内容,所以调用模型进行识别的应用程序才需要class_index.txt这样的文件。
如果是你所使用模型只支持读取序列图片(例如C3D TensorFlow版),并且每个动作的序列图片保存在一个独立的子目录下,那么train/test列表文件可以是类似这样:
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01/act1 1
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01/act2 1
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c02/act1 1
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c03/act1 1
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c03/act2 1
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c03/act3 1...
ApplyLipstick/v_ApplyLipstick_g01_c01/act1 2
ApplyLipstick/v_ApplyLipstick_g01_c02/act1 2
ApplyLipstick/v_ApplyLipstick_g01_c02/act2 2
ApplyLipstick/v_ApplyLipstick_g01_c03/act1 2
ApplyLipstick/v_ApplyLipstick_g01_c04/act1 2
ApplyLipstick/v_ApplyLipstick_g01_c04/act2 2
ApplyLipstick/v_ApplyLipstick_g01_c04/act3 2
ApplyLipstick/v_ApplyLipstick_g01_c04/act4 2
...当每个视频文件都并不是单纯包含一个动作的小视频,而是几个动作的连接的视频,或者有好几个同类别动作连续的视频,那么上面的train_list.txt/test_list.txt的内容还得进一步改造一下,中间还需要增加一列数据指定动作的起始帧(start_frame),结束帧(end_frame)则一般是你使用的3D模型的配置文件里设置的,比如3D模型的配置文件里设置的length为16,则表示为一次读取16帧来训练或推理识别一个动作,那么从train_list.txt/test_list.txt里读取start_frame的值作为开始帧号,连续读取16帧,结束帧号自然是start_frame+16。此时train_list.txt和test_list.txt文件的内容则类似如下所示:
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01.avi 1 1
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c02.avi 1 1
ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c03.avi 1 1...
ApplyLipstick/v_ApplyLipstick_g01_c01.avi 1 2
ApplyLipstick/v_ApplyLipstick_g01_c02.avi 1 2
ApplyLipstick/v_ApplyLipstick_g01_c03.avi 1 2
ApplyLipstick/v_ApplyLipstick_g01_c04.avi 1 2
...假若你使用的3D模型只支持一序列图片来识别一个动作,或者是你的项目的视频数据都很大,按动作切分视频或者标注视频不方便,或者觉得相对使用目前某些视频标注工具来标注视频说,把视频抽取成图片后再来分类比较可靠不容易出错 (反正我实验用过MS的VoTT和国内某视频数据标注工具,可靠性离实用还差很远,经常一个地方出错就把全部帧位标注都搞乱了,有时可能标注了大半天就一个错误就全废了,真有气得要吐血的感觉。另外,工具支持的保存格式有限,得自己写脚本转换成类似UCF101这样风格的标注方式),那么写脚本调用ffmpeg之类的工具把对应目录下的每个视频按一定的FPS抽取成jpg图片,如果你使用的模型不支持start_frame标注,那么每个目录下只能存放模型的length参数指定帧数的图片,每一个动作序列的图片(比如16帧图片)对应存放到相应动作类别对应的目录下的对应视频文件对应的目录下的子目录中,全路径可以表示为.../<action_name>/<video_name>/<action_set>/*.jpg,如果你使用的模型支持start_frame标注,那么一个子目录下可以存放多种动作的序列图片,当然,每个序列的图片数不能少于模型的length参数指定的帧数,但是呢,为了清晰和便于核对,我一般还是一个子目录下只存放一种动作的指定帧数的图片(例如16帧)。然后写脚本生成把上面的train_list.txt/test_list.txt的内容中的avi的路径换成对应的图片所在的目录的路径即可(不要包含图片文件名本身),例如,我实际项目中使用序列图片而不是视频来训练模型时,train_list.txt/test_list.txt文件内容类似如下:

至于抽取图片的脚本以及生成train_list.txt/test_list.txt的脚本可以使用shell脚本写也可以使用python写,我沿用的C3D Tensorflow版的写法使用的shell写的,其实使用python可能更容易实现也更灵活,因为python功能很强大。
贴出相关命令和示例代码:
从http://ffmpeg.org/download.html 下载linux版本的ffmpeg可执行程序,然后设置环境:
![]()
![]()
写个shell脚本convert_video2jpg.sh从各个视频中抽取图片并分目录对应存放:
for folder in $1/*
dofor file in "$folder"/*.mp4doif [[ ! -d "$2/${file[@]%.mp4}" ]]; thenmkdir -p "$2/${file[@]%.mp4}"fiffmpeg -i "$file" -vf fps=$3 "$2/${file[@]%.mp4}"/%05d.jpgdone
done
假设视频文件都在video目录里,抽取的图片以为文件名为目录存放到父目录video_images下去, 抽取帧率 FPS = 10,那么执行命令:
./convert_video2jpg.sh video video_images 10对抽取出来的图片进行人工挑选,挑选出属于同一个动作的序列图片到同一个子目录,然后按照<action_name>/<video_name>/<action_set>/*.jpg这样的路径方式存放。当然如果全靠人工这么干太费时间了,所以我弄了个投机取巧的办法,让数据标注人员找到每个动作的起始关键帧(从图片看能明显判断出是该动作的开始)使用labelimg之类的标注工具标注一下动作名以生成这张图片对应的标注文件,标注文件和图片保存在一起,然后我写脚本去读取video_images下的所有标注文件,从标注文件对应的图片开始,按照图片的名字里的序号(图片文件的名字其实也可以不是连续的数字,关键是你写代码读取时要注意保证按照动作的先后顺序依次读取那些图片,不要顺序颠倒了就引起了混乱,如果你使用的3D模型只能读取图片文件的名字是连续数字的,但你又不想被这点束缚,那么可以修改模型文件里读取数据的代码,例如video-caffe里的读取动作对应的视频或者连续图片的数据代码就在src/caffe/util/io.cpp里,我就把相关代码注释掉了改成了可以按文件名字符串排序(这样就不受连续数据的束缚了)顺序读取每个动作集子目录下的全部图片)往后依次读取16帧,自动保存到一个动作集目录<action_name>/<video_name>/<action_set>/下去,这样只要人工标注完了每个动作的关键帧,就能很快按照<action_name>/<video_name>/<action_set>/*.jpg路径格式生成UCF101风格的数据集,然后使用下面的脚本convert_images_to_C3D_list.sh生成train_list.txt和test_list.txt(C3D里使用ucf101数据集训练是对应的文件名叫c3d_ucf101_train_split1.txt和c3d_ucf101_test_split1.txt,这里我保持一致):
> c3d_ucf101_train_split1.txt
> c3d_ucf101_test_split1.txt
COUNT=-1
for folder in $1/*
doprintf "${folder}\n"COUNT=$[$COUNT + 1]for imagesFolder in "$folder"/*/*doprintf "${imagesFolder}\n"if (( $(jot -r 1 1 $2) > 1 )); thenecho "${imagesFolder}" 1 $COUNT >> c3d_ucf101_train_split1.txtelseecho "${imagesFolder}" 1 $COUNT >> c3d_ucf101_test_split1.txtfidone
done
里面用到个产生随机数的工具athena-jot,首先安装它:
apt-get install athena-jot然后执行下面的命令产生train/test列表文件:
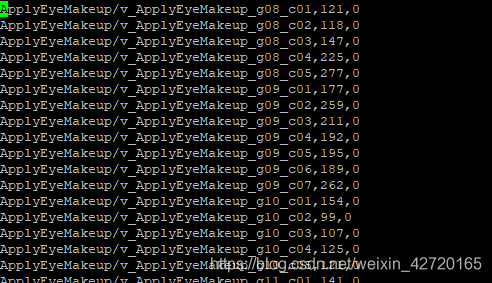
./convert_images_to_C3D_list.sh data/video-labeled-3dds 4生成的train/test列表文件内容示例如下:
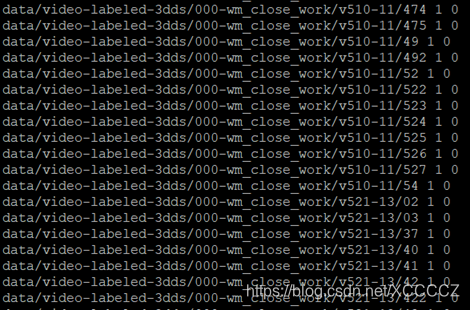
另外呢,统计计算图片数据的均值时也需要这样的列表文件,例如我写了个生成这样的列表文件的脚本convert_images_to_caffe_lmdb_list.sh如下:
> caffe_lmdb.list
COUNT=-1
for folder in $1/*
doprintf "${folder}\n"COUNT=$[$COUNT + 1]for imagesFolder in "$folder"/*/*doprintf "${imagesFolder}\n"for f in "${imagesFolder}"/*.jpgdoecho "$f" $COUNT >> caffe_lmdb.listdonedone
done
然后执行脚本生成列表文件
./convert_images_to_caffe_lmdb_list.sh data/video-labeled-3dds 4然后使用这个列表文件去统计生成lmdb database文件
cd /workspace/video-caffe/build/tools
./convert_imageset /workspace/video-caffe/ /workspace/video-caffe/caffe_lmdb.list laundry.lmdb --resize_width=171 --resize_height=128然后使用lmdb文件算出均值:
./compute_image_mean laundry.lmdbI0610 21:26:28.706018 2337 db_lmdb.cpp:35] Opened lmdb laundry.lmdb
I0610 21:26:28.707100 2337 compute_image_mean.cpp:70] Starting iteration
I0610 21:26:29.398113 2337 compute_image_mean.cpp:95] Processed 10000 files.
I0610 21:26:29.505965 2337 compute_image_mean.cpp:101] Processed 11584 files.
I0610 21:26:29.506062 2337 compute_image_mean.cpp:108] Write to laundry_mean.binaryproto
I0610 21:26:29.506680 2337 compute_image_mean.cpp:114] Number of channels: 3
I0610 21:26:29.506724 2337 compute_image_mean.cpp:119] mean_value channel [0]: 121.643
I0610 21:26:29.506786 2337 compute_image_mean.cpp:119] mean_value channel [1]: 124.514
I0610 21:26:29.506829 2337 compute_image_mean.cpp:119] mean_value channel [2]: 126.064
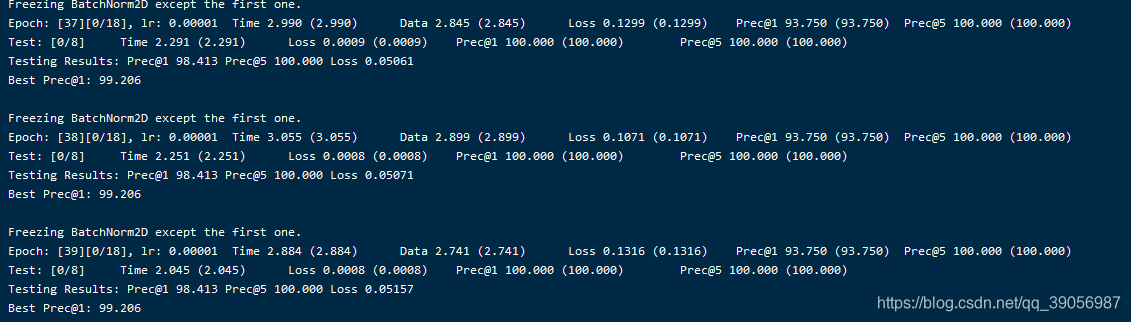
然后使用这些均值去设置ucf101训练video-caffe的配置文件c3d_ucf101_ train_test.prototxt,一并设置好train/test列表文件c3d_ucf101_train_split1.txt和c3d_ucf101_test_split1.txt的路径作为训练和测试的数据source:
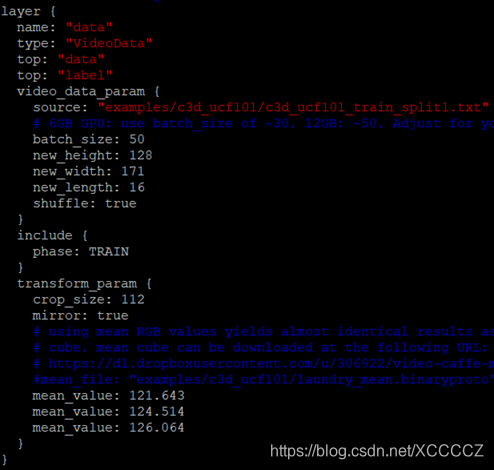
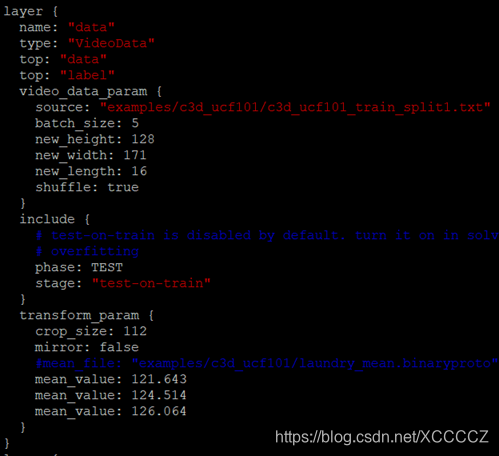
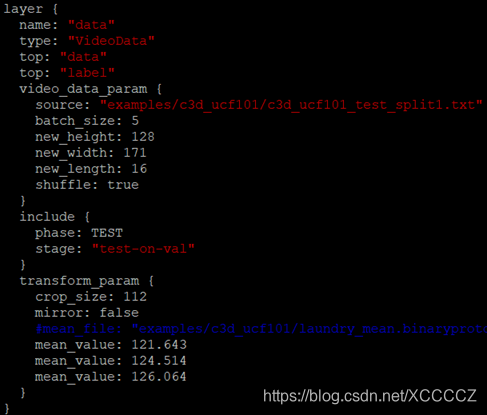
然后根据需要修改c3d_ucf101_solver.prototxt里的超参数后就可以执行下面的命令开始训练了:
cd /workspace/video-caffe
./examples/c3d_ucf101/train_ucf101.sh