大家好,小编来为大家解答以下问题,python网络爬虫爬取数据,利用python爬取数据,现在让我们一起来看看吧!


网络爬虫,就是按照一定规则自动访问互联网上的信息并把内容下载下来的程序或脚本。
在整个的Python爬虫架构里,从基础到深入我分为了10个部分:HTTP、网页、基本原理、静态网页爬取、动态网页爬取、APP爬取、多协程、爬虫框架、分布式爬虫以及反爬虫机制与应对方法神码ai火车头伪原创网址。
1.HTTP
使用Python网络爬虫首先需要了解一下什么是HTTP,因为这个跟Python爬虫的基本原理息息相关。而正是围绕着这些底层逻辑,Python爬虫才能一步步地往下进行。
HTTP全称是Hyper Text Transfer Protocol,中文叫超文本传输协议,用于从网络传输超文本数据到本地浏览器的传送协议,也是因特网上应用最为广泛的一种网络传输协议。
请求与响应
当我们从浏览器输入URL回车之后,浏览器就会向网站所在的服务器发送一个请求,服务器收到请求后对其进行解析和处理,然后返回浏览器对应的响应,响应里包含了页面的源代码等内容,经过浏览器的解析之后便呈现出我们在浏览器上看到的内容。这整个过程就是HTTP的请求与响应。
请求方法常见的请求方法有两种:GET和POST。二者的主要区别在于GET请求的内容会体现在URL里,POST请求则体现在表单形式里,所以当涉及一些敏感或私密的信息时,如用户名和密码,我们用POST请求来进行信息的传递。
响应状态码请求完之后,客户端会收到服务器返回的响应状态,常见的响应状态码有200(服务器正常响应)、404(页面未找到)、500(服务器内部发生错误)等。
2.网页
在爬虫时,我们通过响应得到的网页源代码、JSON数据等来提取需要的信息数据,所以我们需要了解一下网页的基础结构。一个网页基本由以下三部分组成:
HTML,全称Hyper Text Marked Language,中文叫超文本标记语言,用来表述网页以呈现出内容,如文字,图片,视频等,相当于网页的骨架。
JavaScript,简称JS,是一种脚本语言,能够给页面增加实时、动态、交互的功能,相当于网页的肌肉。
CSS,全称Cascading Style Sheets,中文叫层叠样式表,对网页页面进行布局和装饰,使页面变得美观、优雅,相当于网页的皮肤。
3.基本原理
Python爬虫的基本原理其实是围绕着HTTP和网页结构展开的:首先是请求网页,接着是解析和提取信息,最后是存储信息。
1) 请求
Python经常用来请求的第三方库有requests、selenium,内置的库也可以用urllib。
requests是用Python编写的,基于urllib,采用Apache2 Licensed开源协议的HTTP库。相比urllib库,requests库更加方便,可以节约我们大量工作,所以我们倾向于使用requests来请求网页。
selenium是一个用于web应用程序的自动化测试工具,它可以驱动浏览器执行特定的动作,如输入、点击、下拉等,就像真正的用户在操作一样,在爬虫中常用来解决JavaScript渲染问题。selenium可以支持多种浏览器,如Chrome,Firefox,Edge等。在通过selenium使用这些浏览器之前,需要配置好相关的浏览器驱动:
ChromeDriver:Chrome浏览器驱动
GeckoDriver:Firefox浏览器驱动
PhantomJS:无界面、可脚本编程的WebKit浏览器引擎
2)解析和提取
Python用来解析和提取信息的第三方库有BeautifulSoup、lxml、pyquery等。
每个库可以用不同的方法来提取数据:
BeautifulSoup:方法选择器find()和find_all()或CSS选择器
lxml:XPath
pyquery:CSS选择器
此外,还可以用正则表达式来提取自己想要的信息,有了它,字符串检索、替换和匹配都不在话下。
3)存储
将数据提取出之后就是对数据进行存储了。最简单的可以将数据保存为文本文件,如TXT文本、CSV文件、Excel文件、JSON文件等,也可以保存为二进制数据,如图片、音频、视频等,还可以保存到数据库中,如关系型数据库MySQL,非关系型数据库MongoDB、Redis等。
若是将数据存储为CSV文件、Excel文件和JSON文件则需要用到csv库、openpyxl库和json库。
4.静态网页爬取
了解完爬虫基本原理之后就可以爬取网页了,其中静态网页是最容易操作的。
对静态网页进行爬取,我们可以选择requests进行请求,得到网页源代码,接着使用BeautifulSoup进行解析和提取,最后选择合适的存储方法。
5.动态网页爬取
有时候在使用requests爬取网页的时候,会发现抓取的内容和浏览器显示的不一样,在浏览器里能看到要爬取的内容,但是爬取完之后的结果却没有,这就与网页是静态的还是动态的有关了。
静态网页是相对于动态网页而言,是指没有后台数据库、不含程序和不可交互的网页。而动态网页则是基本的html语法规范与Java、VB、VC等高级程序设计语言、数据库编程等多种技术的融合,以期实现对网站内容和风格的高效、动态和交互式的管理的网页。
二者的区别在于:
静态网页随着html代码的生成,页面的内容和显示效果基本上不会发生变化了——除非修改页面代码。
动态网页的页面代码虽然没有变,但是显示的内容却可以随着时间、环境或者数据库操作的结果而发生改变。
1)Ajax
Ajax不是一门编程语言,而是利用JavaScript在不重新加载整个页面的情况下可以与服务器交换数据并更新部分网页内容的技术。
因为使用Ajax技术的网页里的信息是通过JavaScript脚本语言动态生成的,所以使用requests-BeautifulSoup的静态页面的爬取方法是抓不到数据的,我们可以通过以下两种方法爬取Ajax数据:
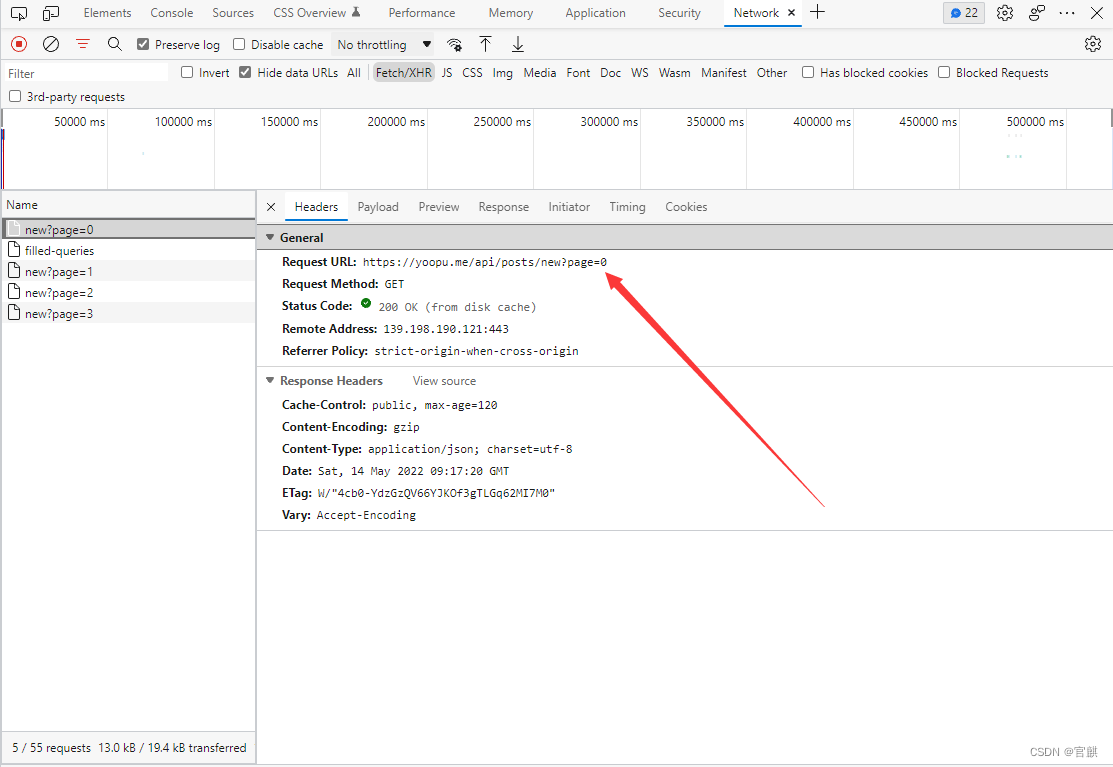
通过查找浏览器开发者工具里的Network-XHR/JS栏找到储存着数据的动态页面,使用requests请求网页,再将得到的数据使用json()方法进行转化就可以提取了。
使用selenium指挥浏览器,直接对数据进行抓取(或者通过selenium获取到渲染完整的网页源代码,再使用BeautifulSoup进行解析和提取数据)。
2)Cookie和Session
Cookie是网站为了辨别用户身份进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存。
Session称为“会话”,存储着特定用户会话所需的属性及配置信息。
很多情况下,页面的更多信息需要登陆才能查看,所以在面对这类网页时,需要先模拟登陆后才可以对网页作进一步爬取。当我们模拟登陆时,客户端会生成Cookie并发送给服务器。因为Cookie保存着SessionID信息,所以服务器就可以根据Cookie判断出对应的SessionID,进而找到会话。如果当前的会话是有效的,那么服务器就会判断用户已经登陆并返回请求的页面信息,这样就可以对网页作进一步爬取了。
6.APP爬取
除了web端,Python还可以爬取APP数据,不过这需要用到抓包工具,比如Fiddler。
相比web端而言,APP的数据爬取其实更容易,反爬虫也没那么强,返回的数据类型大多数为json。
7.多协程
当我们在做爬虫项目的时候,如果需要爬取的数据非常多,因为程序是一行行依次执行的,所以爬取的速度就会非常慢。而多协程就能解决这一个问题。
使用多协程,我们就可以同时执行多个任务。实际上,使用多协程时,如果一个任务在执行的过程中遇到等待,那它就会先去执行其它的任务,当等待结束,再回来继续执行之前的那个任务。因为这个过程切换得非常迅速,所以看上去像多个任务被同时执行一样,用计算机里的概念来解释的话,这其实就是异步。
我们可以使用gevent库来实现多协程,使用Queue()创建队列,spawn()创建任务,最后joinall()执行任务。
8.爬虫框架
在遇到比较大型的需求时,为了方便管理及拓展,我们可以使用爬虫框架实现数据爬取。
有了爬虫框架之后,我们就不必一个个地去组建爬虫的整个流程,只需要关心爬虫的核心逻辑部分即可,这样就大大提高了开发效率,节省了很多时间。爬虫框架有很多个,如Scrapy、PySpider等。
9.分布式爬虫
使用爬虫框架已经大大提高了开发效率,不过这些框架都是在同一台主机上运行的,如果能多台主机协同爬取,那么爬取效率就会更近一步提高。将多台主机组合起来,共同完成一个爬取任务,这就是分布式爬虫。
10.反爬虫机制与应对方法
为了防止爬虫开发者过度爬取造成网站的负担或者进行恶意的数据抓取,很多网站会设置反爬虫机制。所以当我们在对网站进行数据抓取的时候,可以查看一下网站的robots.txt了解一下网站允许爬取什么,不允许爬取什么。
常见的爬虫机制有以下4种:
①请求头验证:请求头验证是最常见的反爬虫机制,很多网站会对Headers里的user-agent进行检测,一部分网站还会检测origin和referer。应对这类反爬虫机制可以在爬虫中添加请求头headers,将浏览器里对应的值以字典的形式添加进去即可。
②Cookie限制:有些网站会用Cookie跟踪你的访问过程,如果发现爬虫的异常行为就会中断该爬虫的访问。应对Cookie限制类的反爬虫,一般可以通过先取得该网站的Cookie,再把Cookie发送给服务器即可,可以手动添加或者使用Session机制。不过,针对部分网站需要用户浏览页面时才能产生Cookie的情况,比如点击按钮,可以使用selenium-PhantomJS来请求网页并获取Cookie。
③IP访问频率限制:一些网站会通过检测用户行为来判断同一IP是否在短时间内多次请求页面,如果这个频率超过了某个阈值,网站通常会对爬虫进行提示并要求输入验证码,或者直接封掉IP拒绝服务。针对这种情况,可以使用IP代理的方法来绕过反爬虫,如代理池维护、付费代理、ADSL拨号代理等。
④验证码限制:很多网站在登陆的时候需要输入验证码,常见的有:图形验证码、极验滑动验证码、点触验证码和宫格验证码。
图形验证码:需要用到OCR技术,使用Python的第三方库tesserocr可以做到这一点。
极验滑动验证码:需要使用selenium来完成模拟人的行为的方式来验证。
点触验证码:需要在使用selenium的基础上借助第三方验证码服务平台来解决。
宫格验证码:需要使用selenium和模板匹配的方法。

公众号:「Python编程小记」,持续推送学习分享。