文章目录
- 一、数据集简介:
- 二、数据集获取及解压缩:
- 1. 数据下载
- 2. 数据集解压缩:
- 三、数据集划分
- 四、数据集预处理
- 1. 生成pkl文件
- 2. 直接对视频文件处理
一、数据集简介:
UCF101是一个现实动作视频的动作识别数据集,收集自YouTube,提供了来自101个动作类别的13320个视频。官方网站:https://www.crcv.ucf.edu/research/data-sets/ucf101/
- 数据集名称:UCF-101(2012)
- 总视频数:13,320个视频
- 总时长:27个小时
- 视频来源:YouTube采集
- 视频类别:101 种
- 主要包括5大类动作 :人与物体交互,单纯的肢体动作,人与人交互,演奏乐器,体育运动
- 每个类别(文件夹)分为25组,每组4~7个短视频,每个视频时长不等
- 具体类别:涂抹眼妆,涂抹口红,射箭,婴儿爬行,平衡木,乐队游行,棒球场,篮球投篮,篮球扣篮,卧推,骑自行车,台球射击,吹干头发,吹蜡烛,体重蹲,保龄球,拳击沙袋,拳击速度袋,蛙泳,刷牙,清洁和挺举,悬崖跳水,板球保龄球,板球射击,在厨房切割,潜水,打鼓,击剑,曲棍球罚款,地板体操,飞盘接球,前爬网,高尔夫挥杆,理发,链球掷,锤击,倒立俯卧撑,倒立行走,头部按摩,跳高,跑马,骑马,呼啦圈,冰舞,标枪掷,杂耍球,跳绳,跳跃杰克,皮划艇,针织,跳远,刺,阅兵,混合击球手,拖地板,修女夹头,双杠,披萨折腾,弹吉他,弹钢琴,弹塔布拉琴,弹小提琴,弹大提琴,弹Daf,弹Dhol,弹长笛,弹奏锡塔琴,撑竿跳高,鞍马,引体向上,拳打,俯卧撑,漂流,室内攀岩,爬绳,划船,莎莎旋转,剃胡子,铅球,滑板溜冰,滑雪,Skijet,跳伞,足球杂耍,足球罚球,静环,相扑摔跤,冲浪,秋千,乒乓球拍,太极拳,网球秋千,投掷铁饼,蹦床跳跃,打字,高低杠,排球突刺,与狗同行,墙上俯卧撑,在船上写字,溜溜球。剃胡须,铅球,滑冰登机,滑雪,Skijet,跳伞,足球杂耍,足球罚款,静物环,相扑,冲浪,秋千,乒乓球射击,太极拳,网球秋千,掷铁饼,蹦床跳跃,打字,不均匀酒吧,排球突刺,与狗同行,壁式俯卧撑,船上写字,溜溜球。剃胡须,铅球,滑冰登机,滑雪,Skijet,跳伞,足球杂耍,足球罚款,静物环,相扑,冲浪,秋千,乒乓球射击,太极拳,网球秋千,掷铁饼,蹦床跳跃,打字,不均匀酒吧,排球突刺,与狗同行,壁式俯卧撑,船上写字,溜溜球
二、数据集获取及解压缩:
1. 数据下载
UCF101数据下载地址:https://www.crcv.ucf.edu/datasets/human-actions/ucf101/UCF101.rar
官方数据划分下载地址:https://www.crcv.ucf.edu/wp-content/uploads/2019/03/UCF101TrainTestSplits-RecognitionTask.zip
注:数据集大小为6.46G,数据划分分为三种方式,可自行选择使用
2. 数据集解压缩:
数据集是rar的压缩文件,使用rar进行解压,cd 到对应文件夹
rar x UCF101.rar
解压后就是分类数据集的标准目录格式,二级目录名为人类活动类别,二级目录下就是对应的视频数据。
每个短视频时长不等(零到十几秒都有),大小320*240, 帧率不固定,一般为25帧或29帧,一个视频中只包含一类人类行为。
注:本地没有rar,则需安装,在Linux中安装参考Linux下rar工具安装及常用命令,其中要是自己没有权限可联系管理员让其安装,如果是服务器有使用docker,可用chmod命令更改容器权限进行安装
三、数据集划分
将下载的UCF101TrainTestSplits-RecognitionTask进行解压,解压后如下图所示,共三种划分方式
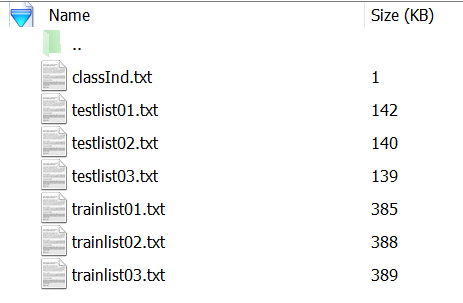
自行选择划分方式,本文使用第一种划分方法,将验证集移动到val文件夹下,划分代码:
import shutil,ostxtlist = ['testlist01.txt']
dataset_dir = './UCF-101/' #数据存放路径
copy_path = './val/' #验证集存放路径for txtfile in txtlist:for line in open(txtfile, 'r'):o_filename = dataset_dir + line.strip()n_filename = copy_path + line.strip()if not os.path.exists('/'.join(n_filename.split('/')[:-1])):os.makedirs('/'.join(n_filename.split('/')[:-1]))shutil.move(o_filename, n_filename)
四、数据集预处理
数据处理加载分两种方式:先将视频文件生成pkl文件在进行处理,或者直接对视频进行处理
1. 生成pkl文件
将视频文件转换生成pkl文件,加快数据读取速度,代码:
import os
from pathlib import Path
import random
import cv2
import numpy as np
import pickle as pk
from tqdm import tqdm
from PIL import Imageimport multiprocessing
import timeimport torchvision.transforms as transforms
from torch.utils.data import DataLoader, Datasetclass VideoDataset(Dataset):def __init__(self, directory, local_rank, num_local_rank, resize_shape=[168, 168] , mode='val', clip_len=8, frame_sample_rate=2):folder = Path(directory) # get the directory of the specified splitprint("Load dataset from folder : ", folder)self.clip_len = clip_lenself.resize_shape = resize_shapeself.frame_sample_rate = frame_sample_rateself.mode = modeself.fnames, labels = [], []for label in sorted(os.listdir(folder))[:200]:for fname in os.listdir(os.path.join(folder, label)):self.fnames.append(os.path.join(folder, label, fname))labels.append(label)'''random_list = list(zip(self.fnames, labels))random.shuffle(random_list)self.fnames[:], labels[:] = zip(*random_list)'''# prepare a mapping between the label names (strings) and indices (ints)self.label2index = {label: index for index, label in enumerate(sorted(set(labels)))}# convert the list of label names into an array of label indicesself.label_array = np.array([self.label2index[label] for label in labels], dtype=int)label_file = str(len(os.listdir(folder))) + 'class_labels.txt'with open(label_file, 'w') as f:for id, label in enumerate(sorted(self.label2index)):f.writelines(str(id + 1) + ' ' + label + '\n')if mode == 'train' or 'val' and num_local_rank > 1:single_num_ = len(self.fnames)//24self.fnames = self.fnames[local_rank*single_num_:((local_rank+1)*single_num_)]labels = labels[local_rank*single_num_:((local_rank+1)*single_num_)]for file in tqdm(self.fnames, ncols=80):fname = file.split("/")self.directory = '/root/dataset/{}/{}'.format(fname[-3],fname[-2])if os.path.exists('{}/{}.pkl'.format(self.directory, fname[-1])):continueelse:capture = cv2.VideoCapture(file)frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))if frame_count > self.clip_len:buffer = self.loadvideo(capture, frame_count, file)else:while frame_count < self.clip_len:index = np.random.randint(self.__len__())capture = cv2.VideoCapture(self.fnames[index])frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))buffer = self.loadvideo(capture, frame_count, file)def __getitem__(self, index):# loading and preprocessing. TODO move them to transform classesreturn indexdef __len__(self):return len(self.fnames)def loadvideo(self, capture, frame_count, fname):# initialize a VideoCapture object to read video data into a numpy arrayself.transform_nor = transforms.Compose([transforms.Resize([224, 224]),])# create a buffer. Must have dtype float, so it gets converted to a FloatTensor by Pytorch laterstart_idx = 0end_idx = frame_count-1frame_count_sample = frame_count // self.frame_sample_rate - 1if frame_count>300:end_idx = np.random.randint(300, frame_count)start_idx = end_idx - 300frame_count_sample = 301 // self.frame_sample_rate - 1buffer_normal = np.empty((frame_count_sample, 224, 224, 3), np.dtype('uint8'))count = 0retaining = Truesample_count = 0# read in each frame, one at a time into the numpy buffer arraywhile (count <= end_idx and retaining):retaining, frame = capture.read()if count < start_idx:count += 1continueif retaining is False or count > end_idx:breakif count%self.frame_sample_rate == (self.frame_sample_rate-1) and sample_count < frame_count_sample:frame = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))buffer_normal[sample_count] = self.transform_nor(frame)sample_count += 1count += 1fname = fname.split("/")self.directory = '/root/dataset/{}/{}'.format(fname[-3],fname[-2])if not os.path.exists(self.directory):os.makedirs(self.directory)# Save tensor to .pkl filewith open('{}/{}.pkl'.format(self.directory, fname[-1]), 'wb') as Normal_writer:pk.dump(buffer_normal, Normal_writer)capture.release()return buffer_normalif __name__ == '__main__':datapath = '/root/dataset/UCF101'process_num = 24for i in range(process_num):p = multiprocessing.Process(target=VideoDataset, args=(datapath, i, process_num))p.start()print('CPU core number:' + str(multiprocessing.cpu_count()))for p in multiprocessing.active_children():print('子进程' + p.name + ' id: ' + str(p.pid))print('all done')
之后对pkl文件进行处理
import os
from pathlib import Pathimport random
import cv2import numpy as np
import pickle as pk
from tqdm import tqdm
from PIL import Imageimport torchvision.transforms as transforms
from torch.utils.data import DataLoader, Datasetclass VideoDataset(Dataset):def __init__(self, directory_list, local_rank=0, enable_GPUs_num=0, distributed_load=False, resize_shape=[224, 224] , mode='train', clip_len=32, crop_size=160):self.clip_len, self.crop_size, self.resize_shape = clip_len, crop_size, resize_shapeself.mode = modeself.fnames, labels = [], []# get the directory of the specified splitfor directory in directory_list:folder = Path(directory)print("Load dataset from folder : ", folder)for label in sorted(os.listdir(folder)):for fname in os.listdir(os.path.join(folder, label)) if mode=="train" else os.listdir(os.path.join(folder, label))[:10]:self.fnames.append(os.path.join(folder, label, fname))labels.append(label)random_list = list(zip(self.fnames, labels))random.shuffle(random_list)self.fnames[:], labels[:] = zip(*random_list)# self.fnames = self.fnames[:240]'''if mode == 'train' and distributed_load:single_num_ = len(self.fnames)//enable_GPUs_numself.fnames = self.fnames[local_rank*single_num_:((local_rank+1)*single_num_)]labels = labels[local_rank*single_num_:((local_rank+1)*single_num_)]'''# prepare a mapping between the label names (strings) and indices (ints)self.label2index = {label:index for index, label in enumerate(sorted(set(labels)))} # convert the list of label names into an array of label indicesself.label_array = np.array([self.label2index[label] for label in labels], dtype=int)def __getitem__(self, index):# loading and preprocessing. TODO move them to transform classessbuffer = self.loadvideo(self.fnames[index])if self.mode == 'train':height_index = np.random.randint(buffer.shape[2] - self.crop_size)width_index = np.random.randint(buffer.shape[3] - self.crop_size)return buffer[:,:,height_index:height_index + self.crop_size, width_index:width_index + self.crop_size], self.label_array[index]else:return buffer, self.label_array[index]def __len__(self):return len(self.fnames)def loadvideo(self, fname):# initialize a VideoCapture object to read video data into a numpy arraywith open(fname, 'rb') as Video_reader:video = pk.load(Video_reader)while video.shape[0]<self.clip_len+2:index = np.random.randint(self.__len__())with open(self.fnames[index], 'rb') as Video_reader:video = pk.load(Video_reader)height, width = video.shape[1], video.shape[2]center = (height//2, width//2)flip, flipCode = True if np.random.random() < 0.5 else False, 1#rotation, rotationCode = True if np.random.random() < 0.2 else False, random.choice([-270,-180,-90,90,180,270])speed_rate = np.random.randint(1, 3) if video.shape[0] > self.clip_len*2+2 and self.mode == "train" else 1time_index = np.random.randint(video.shape[0]-self.clip_len*speed_rate)video = video[time_index:time_index+(self.clip_len*speed_rate):speed_rate,:,:,:]self.transform = transforms.Compose([transforms.Resize([self.resize_shape[0], self.resize_shape[1]]),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])self.transform_val = transforms.Compose([transforms.Resize([self.crop_size, self.crop_size]),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])if self.mode == 'train':# create a buffer. Must have dtype float, so it gets converted to a FloatTensor by Pytorch laterbuffer = np.empty((self.clip_len, 3, self.resize_shape[0], self.resize_shape[1]), np.dtype('float16'))for idx, frame in enumerate(video):if flip:frame = cv2.flip(frame, flipCode=flipCode)'''if rotation:rot_mat = cv2.getRotationMatrix2D(center, rotationCode, 1)frame = cv2.warpAffine(frame, rot_mat, (height, width))'''buffer[idx] = self.transform(Image.fromarray(frame))elif self.mode == 'validation':# create a buffer. Must have dtype float, so it gets converted to a FloatTensor by Pytorch laterbuffer = np.empty((self.clip_len, 3, self.crop_size, self.crop_size), np.dtype('float16'))for idx, frame in enumerate(video):buffer[idx] = self.transform_val(Image.fromarray(frame))return buffer.transpose((1, 0, 2, 3))if __name__ == '__main__':datapath = ['/root/data2/dataset/UCF-101']dataset = VideoDataset(datapath, resize_shape=[224, 224],mode='validation')dataloader = DataLoader(dataset, batch_size=16, shuffle=True, num_workers=0)bar = tqdm(total=len(dataloader), ncols=80)for step, (buffer, labels) in enumerate(dataloader):print(buffer.shape)print("label: ", labels)bar.update(1)
2. 直接对视频文件处理
总体处理过程与pkl文件类似,只是处理主体变成了视频文件,代码:
import os
from pathlib import Pathimport randomimport numpy as np
import pickle as pk
import cv2
from tqdm import tqdm
from PIL import Imageimport torchvision.transforms as transforms
import torchfrom prefetch_generator import BackgroundGenerator
from torch.utils.data import DataLoader, Datasetclass VideoDataset(Dataset):def __init__(self, directory_list, local_rank=0, enable_GPUs_num=0, distributed_load=False, resize_shape=[224, 224] , mode='train', clip_len=32, crop_size = 168):self.clip_len, self.crop_size, self.resize_shape = clip_len, crop_size, resize_shapeself.mode = modeself.fnames, labels = [],[]# get the directory of the specified splitfor directory in directory_list:folder = Path(directory)print("Load dataset from folder : ", folder)for label in sorted(os.listdir(folder)):for fname in os.listdir(os.path.join(folder, label)) if mode=="train" else os.listdir(os.path.join(folder, label))[:10]:self.fnames.append(os.path.join(folder, label, fname))labels.append(label)random_list = list(zip(self.fnames, labels))random.shuffle(random_list)self.fnames[:], labels[:] = zip(*random_list)# self.fnames = self.fnames[:240]if mode == 'train' and distributed_load:single_num_ = len(self.fnames)//enable_GPUs_numself.fnames = self.fnames[local_rank*single_num_:((local_rank+1)*single_num_)]labels = labels[local_rank*single_num_:((local_rank+1)*single_num_)]# prepare a mapping between the label names (strings) and indices (ints)self.label2index = {label:index for index, label in enumerate(sorted(set(labels)))} # convert the list of label names into an array of label indicesself.label_array = np.array([self.label2index[label] for label in labels], dtype=int)def __getitem__(self, index):# loading and preprocessing. TODO move them to transform classessbuffer = self.loadvideo(self.fnames[index])height_index = np.random.randint(buffer.shape[2] - self.crop_size)width_index = np.random.randint(buffer.shape[3] - self.crop_size)return buffer[:,:,height_index:height_index + self.crop_size, width_index:width_index + self.crop_size], self.label_array[index]def __len__(self):return len(self.fnames)def loadvideo(self, fname):# initialize a VideoCapture object to read video data into a numpy arrayself.transform = transforms.Compose([transforms.Resize([self.resize_shape[0], self.resize_shape[1]]),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])flip, flipCode = 1, random.choice([-1,0,1]) if np.random.random() < 0.5 and self.mode=="train" else 0try:video_stream = cv2.VideoCapture(fname)frame_count = int(video_stream.get(cv2.CAP_PROP_FRAME_COUNT))except RuntimeError:index = np.random.randint(self.__len__())video_stream = cv2.VideoCapture(self.fnames[index])frame_count = int(video_stream.get(cv2.CAP_PROP_FRAME_COUNT))while frame_count<self.clip_len+2:index = np.random.randint(self.__len__())video_stream = cv2.VideoCapture(self.fnames[index])frame_count = int(video_stream.get(cv2.CAP_PROP_FRAME_COUNT))speed_rate = np.random.randint(1, 3) if frame_count > self.clip_len*2+2 else 1time_index = np.random.randint(frame_count - self.clip_len * speed_rate)start_idx, end_idx, final_idx = time_index, time_index+(self.clip_len*speed_rate), frame_count-1count, sample_count, retaining = 0, 0, True# create a buffer. Must have dtype float, so it gets converted to a FloatTensor by Pytorch laterbuffer = np.empty((self.clip_len, 3, self.resize_shape[0], self.resize_shape[1]), np.dtype('float16'))while (count <= end_idx and retaining):retaining, frame = video_stream.read()if count < start_idx:count += 1continueif count % speed_rate == speed_rate-1 and count >= start_idx and sample_count < self.clip_len:if flip:frame = cv2.flip(frame, flipCode=flipCode)try:buffer[sample_count] = self.transform(Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)))except cv2.error as err:continuesample_count += 1count += 1video_stream.release()return buffer.transpose((1, 0, 2, 3))if __name__ == '__main__':datapath = ['/root/data1/datasets/UCF-101']dataset = VideoDataset(datapath, resize_shape=[224, 224],mode='validation')dataloader = DataLoader(dataset, batch_size=8, shuffle=True, num_workers=24, pin_memory=True)bar = tqdm(total=len(dataloader), ncols=80)prefetcher = DataPrefetcher(BackgroundGenerator(dataloader), 0)batch = prefetcher.next()iter_id = 0while batch is not None:iter_id += 1bar.update(1)if iter_id >= len(dataloader):breakbatch = prefetcher.next()print(batch[0].shape)print("label: ", batch[1])'''for step, (buffer, labels) in enumerate(BackgroundGenerator(dataloader)):print(buffer.shape)print("label: ", labels)bar.update(1)'''