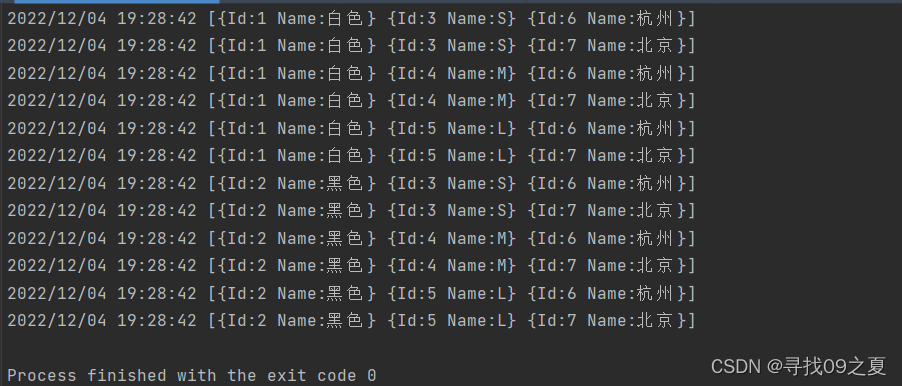
首先说一说什么是SKU。。。。。。。自己百度去。。。
类似京东上面,未来人类S5这个台笔记本(没错,我刚入手了)

都是S5这个型号,但是因为CPU,显卡,内存,硬盘等不同,价格也不一样。CPU,显卡,内存,硬盘等属性组合成的一个唯一的商品,就可以用一个SKU来表示,像图上就有10个SKU。一系列的SKU可以归到一个SPU下进行管理。
那么一个SKU是怎么生成的呢?下面结合自己的一些经验,说说一些电商平台的大致产品结构以及SKU的生成方式。
1.阿里速卖通平台,阿里国际站
这两个平台同一个爸爸,基本差不多。要创建一个商品需要先选一个类目,类目下面挂了一堆的属性,属性上又挂了一堆的属性值。属性分为销售属性和非销售属性(销售属性就是类似颜色,尺寸这些单个SKU独有的,非销售属性就是多个SKU共有的,比如同一个品牌型号“未来人类S5”)。非销售属性有必填和非必填,可以是单选,多选,文本等。销售属性就是构成SKU的关键。比如说有销售属性颜色和尺寸,颜色属性下有很多属性值(红,黄,蓝等等),尺寸(1,2,3,4等等)也是。当颜色选了红,黄,尺寸选了1,2,那么就应该生成2x2=4个SKU,每个SKU有各自的价格,库存等。保存SKU的时候会与对应的销售属性相关联。
大致的数据模型如下

当然,实际比这更加复杂(比如产品的图片,单个SKU的图片,多个SKU共同的图片,非销售属性可以自定义添加分类不具有的。。。)
2.eBay
跟上面两个平台类似,创建一个产品也要先选一个分类,分类下面也是有很多属性,属性有很多属性值。。。,不同的地方是eBay没有区分销售属性和非销售属性(或者说全部是非销售属性),也允许添加自定义属性和属性值。eBay上SKU是手动添加的,SKU上的属性(SKU上的属性暂且都叫做销售属性)也是自定义的。比如说添加了一个SKU A,价格和数量这两个是必须的,还可以手动加个颜色属性,然后填上属性值红色。当然,若果增加一个SKU B,那么这个SKU也会有颜色这个属性,属性值可以自定义。最后校验这些SKU的属性值组合起来是否唯一。

这样的优势就是可以随意控制SKU的数量,如果按照上面两个平台的规则,这里应该有4x4x1=16个SKU。这样自由度更高会不会使结构更加复杂呢?当然是NO,用上面的数据模型就可以搞定

3.Lazada,Linio平台
国际惯例,先选一个类目,类目下面一堆属性,有必填和非必填,属性下一堆属性值。最大的区别就是,一个产品只有一个SKU,属性不支持自定义。比如说要添加一个商品,有两种颜色,那么只能创建两个产品,这两个产品可能只有图片不一样(颜色不一样,可能没有颜色这个属性来选)

4.Wish平台
比较奇特,没有分类,产品有固定的属性,比如标题,描述,运费等。一个产品下可以有多个SKU,SKU的生成取决于固定的两大类属性,两个大类为:颜色和尺寸。比如颜色这个属性就是归类于颜色这个类,其他的属性(品牌,型号,容量等等归为尺寸这个大类)。尺寸类的属性值支持自定义,但只能选一个尺寸类属性(比如选了品牌就不能选容量,选了品牌后可以添加任意值)。两类属性不是必须同时存在,比如颜色选了红,可以不选尺寸类的属性,反之也一样。

忘记说了,一个SKU是靠一串唯一编码来标识的,比如1234A,1234B。一般来说一个平台下不会存在两个相同的SKU,或这一个店铺下不会存在两个相同的SKU。
大致的逻辑和数据模型就这些,接下来说说开发实现方面。
数据库大致就依靠上面的数据模型进行设计,编辑的时候,后端按照这些关联关系取出数据给到前端(我这边前后端未分离,页面还是后端渲染,但我还是把数据格式化为JSON再渲染到前端),保存的时候再进行相关的逻辑校验。因为后端的一些逻辑操作涉及后公司内部的业务,这里就不细说了。说说前端的具体细节,以速卖通的为例,用的是vue,前端拿到的数据如下
")
")
实现后的粗糙界面

data: {properties: properties,skus: skus}遍历properties,得到材质,颜色,发货地,套餐这些属性对象,接着遍历这些对象里的values属性,得到属性值对象,根据属性对象的selectedValues判断属性值是否选上(因为我是后端渲染的js变量,所以初始化的时候selectedValues里的数据直接引用的属性值对象,如果是非后端渲染的话,要根据skus里的属性和属性值去初始化selectedValues的数据,并且存的是属性值对象的引用)
<tr v-for="(index,item) in properties"><td><strong>{{item.Name}}:</strong></td><td><label v-for="value in item.values"><input type="checkbox" :value="value" v-model="item.selectedValues"/>{{value.Name}}</label><table class="list_table" v-if="item.Name!='发货地'&&item.selectedValues.length>0"><tbody><tr><th>{{item.Name}}</th><th>自定义名称</th><th v-if="item.Name=='颜色'">图片(无图片可以不填)</th></tr><tr v-for="selectedValue in item.selectedValues"><td>{{selectedValue.Name}}</td><td><input type="text" v-model="selectedValue.DefinitionName" maxlength="20"/></td><td v-if="item.Name=='颜色'"><div style="float: left"><input type="file" style="width: 63px;"/></div><div style="float: right"><a href="" rel="link" target="_blank"><img :src="selectedValue.ImageUrl" width="30" height="35"/></a></div></td></tr></tbody></table></td></tr>因为selectedValues通过v-model绑定,当选中或取消一个属性值的时候后,selectedValues也会随着改变,selectedValues里的数据是直接引用属性值而不是拷贝一份数据,所以修改selectedValues中的数据也会直接反映到属性值上,实现了属性值的自定义。
那么怎么根据选中的属性值生成SKU呢?
SKU表格处的表头是要根据选中的属性动态更新的,可以这样做
<tr><th v-for="item in properties" v-if="item.selectedValues.length>0">{{item.Name}}</th><th><span class="c_red">*</span>零售价</th><th><span class="c_red">*</span>库存</th><th>商品编码</th></tr>如果属性里的属性值都没有被选中(selectedValues.length==0),就不在表头显示这个属性。
SKU的初始显示
<tr v-for="sku in skus"><td v-for="item in properties" v-if="item.selectedValues.length>0">{{getValueName(sku,item)}}</td><td>US $<input type="text" v-model="sku.SkuPrice" class="w50" maxlength="9"/><span name="productUnitTips"></span></td><td><input type="text" v-model="sku.StockQuantity" class="w50" maxlength="9"/></td><td><input type="text" v-model="sku.SkuCode" class="w180" maxlength="20"/></td>
</tr>也是利用selectedValues.length让SKU的属性值列数与表头列数保持一致。因为SKU对象里的保存的是属性值Id和属性Id,需要一个方法去获取属性值的值
getValueName: function (sku, property) {var valueName = "";$.each(sku.values,function () {var _this = this;if (this.propertyId == property.Id) {$.each(property.selectedValues, function () {if (_this.valueId == this.Id) {valueName = this.Name;return false;}});}});return valueName;}你没有看错,这是JQ。。。
接下来就是SKU表格的更新了,我的做法是变更整块区域,就是给skus重新赋值。赋的新值从哪来呢?
将选中的属性值放到一个数组中
var ori = [];$.each(vm.properties,function (index, item) {var selectValues = this.selectedValues;if (selectValues.length > 0) {ori.push(selectValues);}});得到这种结构的数组
[[{'PropertyId': 10,'Id': 477,'Name': '铝','DefinitionName': '','ImageUrl': ''},{'PropertyId': 10,'Id': 529,'Name': '帆布','DefinitionName': '','ImageUrl': ''}],[{'PropertyId': 200000828,'Id': 201655809,'Name': '壳+贴膜','DefinitionName': '','ImageUrl': ''},{'PropertyId': 200000828,'Id': 201655810,'Name': '壳+挂绳','DefinitionName': '','ImageUrl': ''}]
]求笛卡尔积后(后面有求笛卡尔积参考链接)
var ret = descartes(ori);[[{'PropertyId': 10,'Id': 477,'Name': '铝','DefinitionName': '','ImageUrl': ''},{'PropertyId': 200000828,'Id': 201655809,'Name': '壳+贴膜','DefinitionName': '','ImageUrl': ''}],[{'PropertyId': 10,'Id': 477,'Name': '铝','DefinitionName': '','ImageUrl': ''},{'PropertyId': 200000828,'Id': 201655810,'Name': '壳+挂绳','DefinitionName': '','ImageUrl': ''}],[{'PropertyId': 10,'Id': 529,'Name': '帆布','DefinitionName': '','ImageUrl': ''},{'PropertyId': 200000828,'Id': 201655809,'Name': '壳+贴膜','DefinitionName': '','ImageUrl': ''}],[{'PropertyId': 10,'Id': 529,'Name': '帆布','DefinitionName': '','ImageUrl': ''},{'PropertyId': 200000828,'Id': 201655810,'Name': '壳+挂绳','DefinitionName': '','ImageUrl': ''}]
]大前端也用上了算法有木有,这里需要弄明白拿到的是什么数据,需要的是什么数据,然后就去想实现就OK了。
想要的数据已经拿到,重新构建skus
for (var i = 0; i < ret.length; i++) {var sku = {SkuCode: "", SkuPrice: "", StockQuantity: ""};sku.values = [];$.each(ret[i],function () {sku.values.push({propertyId: this.PropertyId, valueId: this.Id});});vmSkus.push(sku);}到此,更新SKU表格的代码已经实现,数据驱动视图更新,很清晰。但是什么时候去触发这个更新呢(何时去重新构建skus)? 很简单嘛,就是勾选或取消勾选属性值的时候去触发更新操作。勾选或取消勾选我们能直接从selectedValues.length上得到反馈,然后使用vue 的watch就可以实现了。但是selectedValues是properties数组中元素的一个属性,vue的watch是无法用在数组元素的某一个字段上的(至少目前我发现是这样的),那么暴力一点,直接watch整个properties数组并且加上deep:true。这样是可以实现,但是当修改自定义属性的时候也会触发变更(业务会提刀来见的)。
最终解决方案
computed:{allCheckedLength:function(){var length=0;$.each(this.properties,function(){length+=this.selectedValues.length;});return length;}}watch: {'allCheckedLength': {handler: 'reBuild'}}reBuild就是重新构建的方法。
demo
Java 笛卡尔积算法的简单实现
Cartesian product of multiple arrays in JavaScript