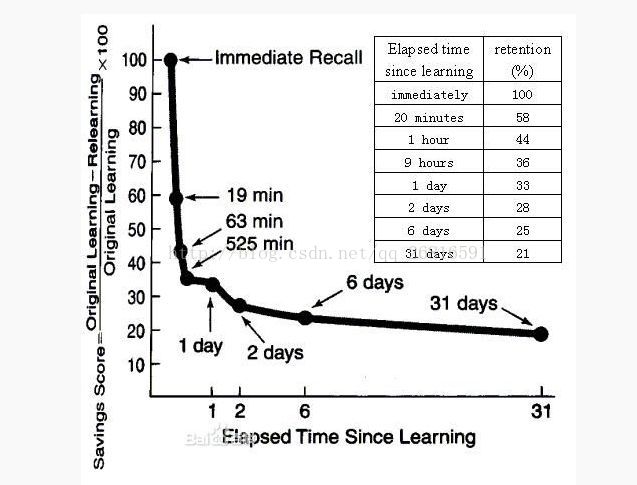
根据 ”艾宾浩斯遗忘曲线“复习时间点生成的复习计划模板
编程小白,写的可能有点乱见谅哈。
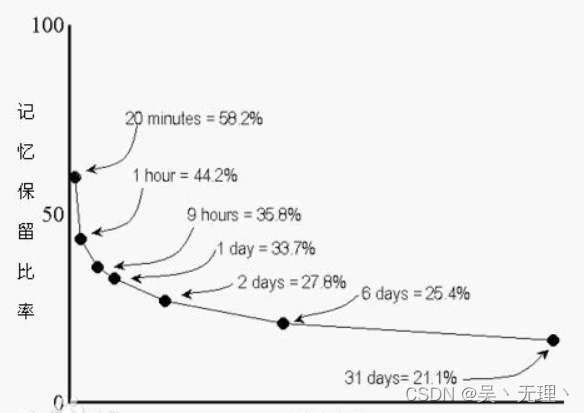
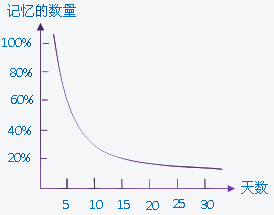
这几天一直在看学习方法之类的内容,加上自己在备考cpa。就经常需要记忆很多东西。突然想起来很久之前看到过的 ”艾宾浩斯遗忘曲线“。看到网上有一些根据这个曲线,总结分享出来的复习时间点,但是没有哪种比较通用的模板可以直接复制,就想着自己写一个。
使用方式:使用方式非常简单,只需要设置一下起始和终止日期,还有文件的生成路径就可以。(也可以去掉注释生成在当前路径下)
结果:代码运行完会生成一个excel表格,每天学习完成之后,将1,2等天数在excel中 ctrl+H 替换为学习的章节即可,如 1 → ‘第一章’,选择全部替换。
注意:如果工作量比较大,可以设置15天为一个周期,把 get_Ebbinghaus_table() 函数的默认参数中的30去掉。
希望对大家的学习有所帮助!

【注意】需要勾选 Match entire cell contents,不然会把所有2开头的也替换掉
import os
import pandas as pd
import numpy as np
import time
import datetime# 计划时长
start_date = '2021-1-14'
end_date = '2021-2-28'plan_days = (pd.to_datetime(end_date) - pd.to_datetime(start_date)).days# 生成excel表格,设置路径
path = r''# 生成到当前工作路径(optional)
# path = os.getcwd()
# name = path + 'Ebbinghaus-review-plan.xlsx'def get_Ebbinghaus_table(start_date,end_date,plan_days,review_interval = [0,1,2,4,7,15,30]):# 遗忘曲线的复习时间点,不要改了,单位:天,设置为行索引# 生成日期seriescolumn_date = pd.Series(pd.date_range(start_date, end_date))Ebbinghaus = pd.DataFrame([column_date + pd.Timedelta(days=i) for i in review_interval],index=review_interval)Ebbinghaus_T = Ebbinghaus.T# 设置日期为列索引1Ebbinghaus_table = Ebbinghaus_T.set_index([pd.Index(column_date)])# 设置天数为列索引列2,也可以改为事件列表days = range(1,plan_days+2)events = ''Ebbinghaus_table = Ebbinghaus_table.set_index([pd.Index(days)],append=True).Treturn Ebbinghaus_tabledef generate(Ebbinghaus_table):dic = {}for i in range(Ebbinghaus_table.shape[1]):# 获取第一行日期column1_date = (Ebbinghaus_table.columns[i])[0]# 获取第二行第几天column2_days = (Ebbinghaus_table.columns[i])[1]# 如果当前列或者当前列的左边有与当前日期相同的,则取他对应的第二行索引df3 = ~pd.isna(Ebbinghaus_table[Ebbinghaus_table.iloc[:,range(column2_days)].isin([column1_date])]).all()date = (Ebbinghaus_table.columns[i])[0]to_datetime = date.to_pydatetime().date()date_fmt = datetime.datetime.strftime(to_datetime,'%Y-%m-%d')dic[date_fmt] = []# 获取所有满足条件的天数for n in df3[df3].index:dic[date_fmt].append(n[1])return dicdef get_review_plan():Ebbinghaus_table = get_Ebbinghaus_table(start_date,end_date,plan_days)process_table = generate(Ebbinghaus_table)index = process_table.keys()values = process_table.values()review_plan = pd.DataFrame(values,dtype=object,index = index)review_plan.to_excel(path,encoding='utf-8',header=0)return review_plan# 使用时将1,2等天数在excel中 ctrl+H 替换为学习的章节即可 如 1 → '第一章',选择全部替换
get_review_plan()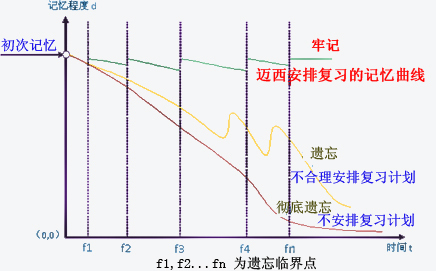






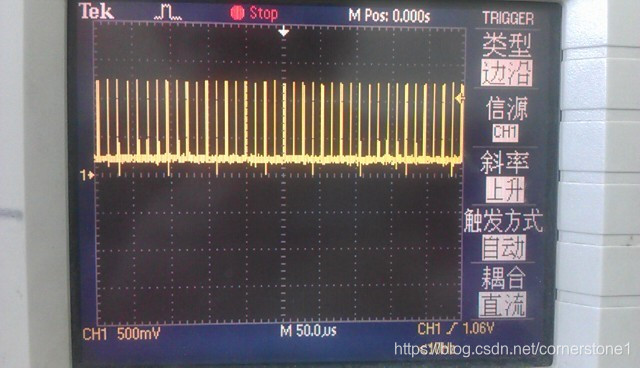
![[RK3399][Android8.1] 调试记录 --- LT9611驱动调试](https://img-blog.csdnimg.cn/20191224090736997.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L29saXZlcko=,size_16,color_FFFFFF,t_70)