目录
一、图像识别
二、最近邻分类器(Nearest Neighbor Classifier)
三、k-最近邻分类器(k - Nearest Neighbor Classifier)
四、超参数的设置(Hyperparameter)
五、分析
一、图像识别
对于人脑来说,图像识别是一个简单的问题,但是对于程序来说,这是一个值得研究的问题。总的来说,物体检测,分割等这些计算机视觉的问题都可以简化为图像识别。
图像识别存在许多需要考虑的问题。对于计算机来说,一张图像是相当于一个矩阵。如下所示:
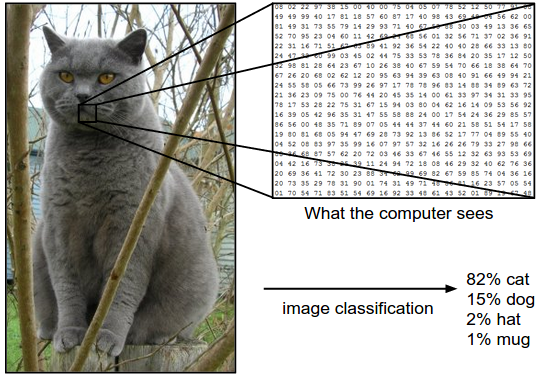
一张彩色的猫的图片对于计算机来说是一个3*248*400的三维张量。图像识别的任务就是给输入的一张图像一个标签。
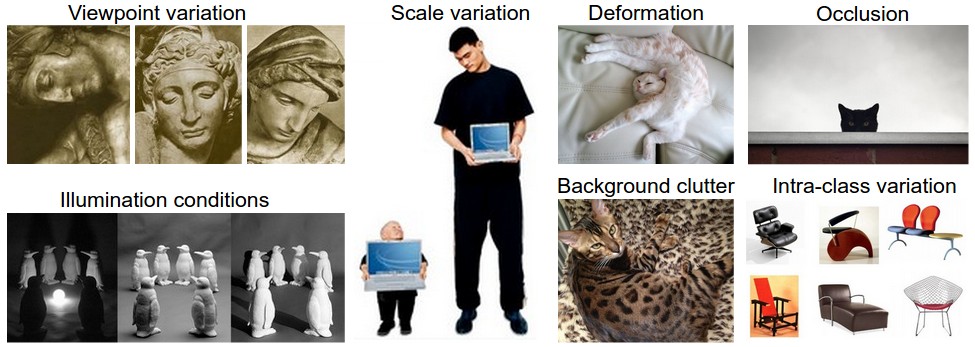
图像识别存在很多挑战:
1.视角变化(viewpoint variation)—一张物体在不同角度的拍摄下也会有不一样的效果。
2. 比列变换(scale variation)—— 物体不仅仅在图像中存在大小差异,同时在现实生活中也存在大小差异。
3.形变(deformation)—— 许多感兴趣的对象不是刚体,可以以极端方式变形。
4.遮挡(occlusion)——可以遮挡感兴趣的对象。 有时只能看到对象的一小部分(少至几个像素)。
5.光照条件(illumination conditions)—— 照明的影响在像素级别上是剧烈的。
6.背景杂波(bakground clutter)——感兴趣的对象可能会融入其环境,使其难以识别。
7.类内变异(intra-class variation)——感兴趣的对象通常比较广泛,比如椅子。这些对象有许多不同的类型,每种类型都有自己的外观。
data-driven approach:与其编写一个算法指定每个感兴趣的类别的样子,不如设计一个学习算法。向计算机提供每一个类别的许多例子,然后算法通过对这些例子进行学习得到每一个类别的视觉外观,这种方法被认为是data-driven approach,因为它依赖于具有标记的训练数据集。
图像识别的流程:训练,验证,测试。
Input:输入我们需要的具有标记的N张图像(监督学习)。
Learning:我们的任务就是利用分类器在数据集中学习到不同类别的特征。我们将此步骤称为训练分类器或者学习模型。
Evaluation: 我们通过要求分类器预测一组它以前从未见过的新图像的标签来评估分类器的质量。 然后我们将这些图像的真实标签与分类器预测的标签进行比较。
二、最近邻分类器(Nearest Neighbor Classifier)
在实际中,最近邻分类器是不常用的,但是它揭示了图像分类的部分依据。
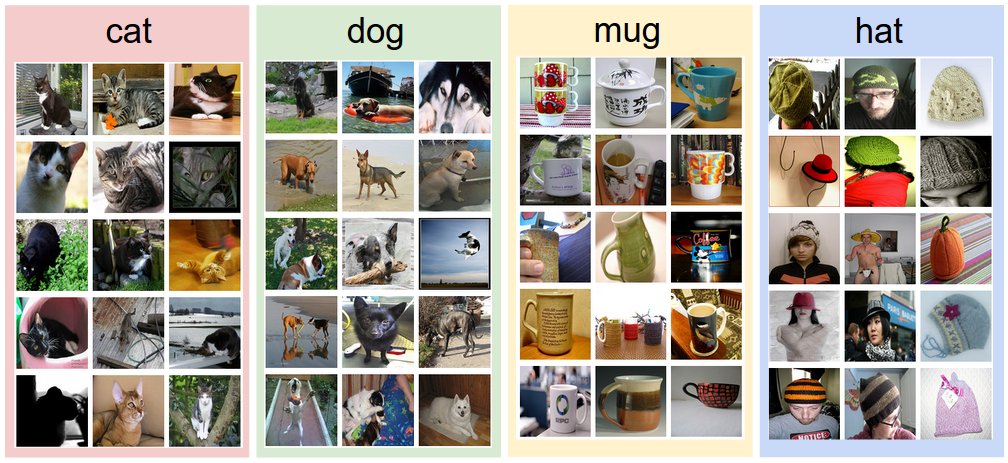
首先介绍一下数据集。CIFAR-10是一个图像分类常用的数据集。 它大约有60000张关于模型的小图片(图片尺寸大约为32*32)。这个数据集包含了10个不同的类别。

我们从这个数据集中提取10000张作为测试集,剩余的图像作为训练集。上图的右边就是分类器的分类结果,但是分类效果并不是很好。
对于最近邻分类器,图像分类的依据是L1 distance。
其在二维矩阵中的用法如下所示:
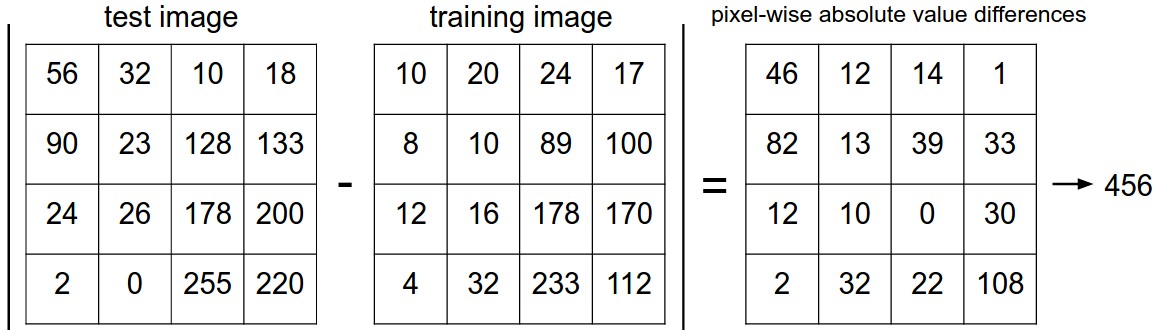
将两个图像元素相减,然后将所有差异相加为一个数字。 如果两个图像相同,则结果为零。 但如果图像非常不同,结果会很大。
Xtr, Ytr, Xte, Yte = load_CIFAR10('data/cifar10/') # a magic function we provide
# flatten out all images to be one-dimensional
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows becomes 50000 x 3072
Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows becomes 10000 x 3072上段代码中,Xtr存储的是训练数据集,共50000张图片,Ytr存成的是训练集的标签,是一个一维数组(长度为50000)。Xte存储的是测试集的数据集,共10000张图片,Yte存储的是测试集的标签。
nn = NearestNeighbor() # create a Nearest Neighbor classifier class
nn.train(Xtr_rows, Ytr) # train the classifier on the training images and labels
Yte_predict = nn.predict(Xte_rows) # predict labels on the test images
# and now print the classification accuracy, which is the average number
# of examples that are correctly predicted (i.e. label matches)
print 'accuracy: %f' % ( np.mean(Yte_predict == Yte) )上面代码实现了分类器的训练。
import numpy as npclass NearestNeighbor(object):def __init__(self):passdef train(self, X, y):""" X is N x D where each row is an example. Y is 1-dimension of size N """# the nearest neighbor classifier simply remembers all the training dataself.Xtr = Xself.ytr = ydef predict(self, X):""" X is N x D where each row is an example we wish to predict label for """num_test = X.shape[0]# lets make sure that the output type matches the input typeYpred = np.zeros(num_test, dtype = self.ytr.dtype)# loop over all test rowsfor i in range(num_test):# find the nearest training image to the i'th test image# using the L1 distance (sum of absolute value differences)distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)min_index = np.argmin(distances) # get the index with smallest distanceYpred[i] = self.ytr[min_index] # predict the label of the nearest examplereturn Ypred上面的代码实现了最近邻分类器。
但是这个分类器的数据集CIFAR-10上的分类效果并不好,仅仅只有38.6%左右。
现在我们考虑换一个图像分类的依据。从最初的L1-distance换为L2-distance.
L2-distance:
distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))但一般在实际操作中不会选择平方后再开根号,而是选择直接平方就好了,这样会提高算法的复杂度。
三、k-最近邻分类器(k - Nearest Neighbor Classifier)
K-最近邻分类器跟最近邻分类器非常的相像。不同的是K-最近邻分类器不是考虑最接近的那一张图像而是考虑最接近的那K张图像。

利用分类器对最左边的图像按照颜色将点分开。我们可以看到NN classifier 分类器存在了过拟合的状态,这样的分类器往往在其他的数据中表现很差。5-NN classifier 分类结果中存在白色的部分,这部分是分类器无法判别的部分(也就是说利用L2-distance计算时,至少有两个以上的类别在这片区域出现了相等的情况)。我们可以看到5-NN classifier 的分类结果更平滑,也就是说更有泛化能力。
四、超参数的设置(Hyperparameter)
注意:我们不能将测试集用于调整超参数。每当您设计机器学习算法时,您都应该将测试集视为一种非常宝贵的资源,最好在最后一次之前永远不要接触它。最后只对测试集进行一次评估。
但是我们可以通过验证集去选择最合适的超参数。
这个想法是将我们的训练集分成两部分:一个稍小的训练集,以及我们所说的验证集。 以 CIFAR-10 为例,我们可以使用 49,000 张训练图像进行训练,并留出 1,000 张用于验证。 这个验证集本质上用作一个假测试集来调整超参数。
# assume we have Xtr_rows, Ytr, Xte_rows, Yte as before
# recall Xtr_rows is 50,000 x 3072 matrix
Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation
Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :] # keep last 49,000 for train
Ytr = Ytr[1000:]# find hyperparameters that work best on the validation set
validation_accuracies = []
for k in [1, 3, 5, 10, 20, 50, 100]:# use a particular value of k and evaluation on validation datann = NearestNeighbor()nn.train(Xtr_rows, Ytr)# here we assume a modified NearestNeighbor class that can take a k as inputYval_predict = nn.predict(Xval_rows, k = k)acc = np.mean(Yval_predict == Yval)print 'accuracy: %f' % (acc,)# keep track of what works on the validation setvalidation_accuracies.append((k, acc))但是当训练集数量很少的时候,我们没有办法提取出验证集的时候,就可以采用交叉验证(Cross-validation)的方法。
例如,在5倍交叉验证中,我们将训练数据分成5倍,其中4倍用于训练,1倍用于验证。然后我们进行迭代,从之前的训练集中抽一份用做验证,而之前当作验证集的数据又称为验证集,这样我们就可以得到五个准确率,然后将其进行平均。
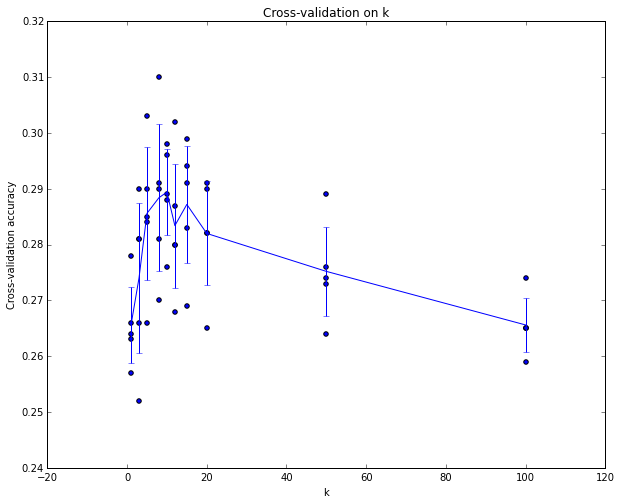
参数 k 的 5 折交叉验证运行示例。 对于 k 的每个值,我们训练 4 次并在第 5 次评估。 因此,对于每个 k,我们在交叉验证上收到 5 个精度(精度是 y 轴,每个结果是一个点)。 趋势线是通过每个 k 的结果的平均值绘制的,误差线表示标准偏差。 请注意,在此特定情况下,交叉验证表明,大约 k = 7 的值在此特定数据集上效果最佳(对应于图中的峰值)。 如果我们使用超过 5 次折叠,我们可能会期望看到更平滑(即噪声更少)的曲线。
但是在实际操作中,一般情况下不会选择交叉验证,因为这种方法的计算代价很昂贵,只有在训练集数量实在不够的情况下再选择这种方法。
五、分析
最邻近分类算法在低维度的时候可能是一个很好的选择,但是在高维度的情况下,最邻近算法就表现的很差。

最左边这个图是原图。后面三张图与原图的L2-distance距离是一致的。

采用一种可视化技术叫做t-SNE 对数据集CIFAR-10 images进行操作。图中,图片距离越近就代表着两者之间的L2-distance值越小。在这个结果中,我们可以清楚的知道图片的背景对最邻近分类器的结果的影响很大。
因此我们在进行图像分类时,不能仅仅局限于图像上看得见的像素信息,还要挖掘更深层的信息。