在爬取网站的时候我们有时候会遭受封ip等显现,因此我们需要搭建自己的ip池用于爬虫。
代码过程简述:
1、爬取代理ip网站信息
2、将获取的信息处理得到ip等关键信息
3、保存首次获取的ip信息并检测其是否可用
4、检测完毕将可用ip保存,搭建完成
本文是单线程,比较简单但效率可能没有那么快,多线程可以参考这篇文章:python搭建ip池(多线程)
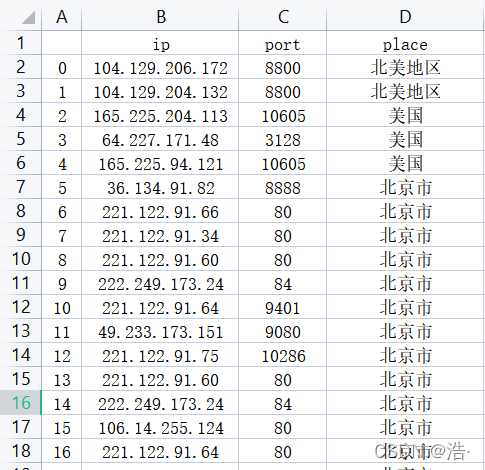
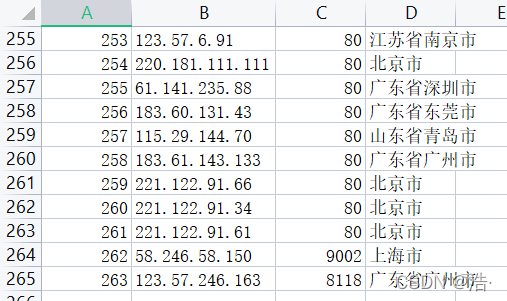
下面是搭建完后的ip池展示:
老规矩先放总的代码后再一步步解析
# -*- coding: gbk -*- # 防止出现乱码等格式错误
# ip代理网站:http://www.66ip.cn/areaindex_19/1.htmlimport requests
from fake_useragent import UserAgent
import pandas as pd
from lxml import etree # xpath# ---------------爬取该网站并获取通过xpath获取主要信息----------------
def get_list_ip(city_id):url = 'http://www.66ip.cn/areaindex_{}/1.html'.format(city_id)headers = {'User-Agent': UserAgent().random,}data_html = requests.get(url=url, headers=headers)data_html.encoding = 'gbk'data_html = data_html.texthtml = etree.HTML(data_html)etree.tostring(html)list_ip = html.xpath('//div[@align="center"]/table/tr/td/text()') # 获取html含有ip信息的那一行数据return list_ip# --------------将爬取的list_ip关键信息进行处理、方便后续保存----------------
def dispose_list_ip(list_ip):num = int((int(len(list_ip)) / 5) - 1) # 5个一行,计算有几行,其中第一行是标题直接去掉content_list = []for i in range(num):a = i * 5ip_index = 5 + a # 省去前面的标题,第5个就是ip,往后每加5就是相对应iplocation_index = 6 + aplace_index = 7 + aitems = []items.append(list_ip[ip_index])items.append(list_ip[location_index])items.append((list_ip[place_index]))content_list.append(items)return content_list# -----------将处理结果保存在csv-------------
def save_list_ip(content_list,file_path):columns_name=["ip","port","place"]test=pd.DataFrame(columns=columns_name,data=content_list) # 去掉索引值,否则会重复test.to_csv(file_path,mode='a',encoding='utf-8')print("保存成功")# -----------读取爬取的ip并验证是否合格-----------
def verify_ip(file_path):file = pd.read_csv(file_path)df = pd.DataFrame(file)verify_ip = []for i in range(len(df)):ip_port = str(df["ip"][i]) + ":" + str(df["port"][i]) # 初步处理ip及端口号headers = {"User-Agent": UserAgent().random}proxies = {'http': 'http://' + ip_port# 'https': 'https://'+ip_port}'''http://icanhazip.com访问成功就会返回当前的IP地址'''try:p = requests.get('http://icanhazip.com', headers=headers, proxies=proxies, timeout=3)item = [] # 将可用ip写入csv中方便读取item.append(df["ip"][i])item.append(df["port"][i])item.append(df["place"][i])verify_ip.append(item)print(ip_port + "成功!")except Exception as e:print("失败")return verify_ipif __name__ == '__main__':# ----------爬取与保存------------save_path = "test.csv"city_num = int(input("需要爬取几个城市ip")) # 1~34之间,该网站只有34个城市页面content_list = []for i in range(city_num): # 批量爬取list_ip关键信息并保存response = get_list_ip(i)list = dispose_list_ip(response)content_list += list # 将每一页获取的列表连接起来save_list_ip(content_list,save_path)# -----------验证--------------open_path = "test.csv"ip = verify_ip(open_path)# ---------保存验证结果-----------save_path = "verify_ip.csv"save_list_ip(ip,save_path)一、爬取代理ip网站信息
先导入所用到的库:
import requests
from fake_useragent import UserAgent # 用来随机UserAgent值(用自己的也不影响)
import pandas as pd
from lxml import etree # xpath随便找到一个免费的ip代理网站
这个网站没什么反爬机制,找到网站的url规律直接request get他就行

这里可以看出只是改了一下数字而已,直接get他
# ---------------爬取该网站并获取通过xpath获取主要信息----------------
def get_list_ip(city_id): # city_id用来询问要爬取多少个城市url = 'http://www.66ip.cn/areaindex_{}/1.html'.format(city_id)headers = {'User-Agent': UserAgent().random,}data_html = requests.get(url=url, headers=headers)data_html.encoding = 'gbk'data_html = data_html.texthtml = etree.HTML(data_html)etree.tostring(html)list_ip = html.xpath('//div[@align="center"]/table/tr/td/text()') # 获取html含有ip信息的那一行数据return list_ip尝试输出一下看一下结果
city_num = int(input("需要爬取几个城市ip")) # 1~34之间,该网站只有34个城市页面for i in range(city_num): # 批量爬取list_ip关键信息并保存response = get_list_ip(i)print(response)
二、将获取的信息处理得到ip等关键信息
从上面返回的结果看出,列表每隔五个出现一次循环,假设列表有n个元素,那么就有n/5个ip,第五个开始出现ip,第六个出现端口号,第七个出现地址,列表第5+5个出现第二个ip,6+5个位置出现第二个端口号,有这个规律后就可以开始处理。
def dispose_list_ip(list_ip):num = int((int(len(list_ip)) / 5) - 1) # 5个一行,计算有几行,其中第一行是标题直接去掉content_list = []for i in range(num):a = i * 5ip_index = 5 + a # 省去前面的标题,第5个就是ip,往后每加5就是相对应iplocation_index = 6 + aplace_index = 7 + aitems = []items.append(list_ip[ip_index])items.append(list_ip[location_index])items.append((list_ip[place_index]))content_list.append(items)return content_list尝试输出一下:
city_num = int(input("需要爬取几个城市ip")) # 1~34之间,该网站只有34个城市页面content_list = []for i in range(city_num): # 批量爬取list_ip关键信息并保存response = get_list_ip(i)list = dispose_list_ip(response)content_list += list # 将每一页获取的列表连接起来print(content_list)
三、保存首次获取的ip信息并检测其是否可用
保存代码:
def save_list_ip(content_list,file_path):columns_name=["ip","port","place"]test=pd.DataFrame(columns=columns_name,data=content_list) # 去掉索引值,否则会重复test.to_csv(file_path,mode='a',encoding='utf-8')print("保存成功")首次保存后,读取保存的ip并对其进行一个验证是否可用,验证完毕后再将可用ip保存到csv中
# -----------读取爬取的ip并验证是否合格-----------
def verify_ip(file_path):file = pd.read_csv(file_path)df = pd.DataFrame(file)verify_ip = []for i in range(len(df)):ip_port = str(df["ip"][i]) + ":" + str(df["port"][i]) # 初步处理ip及端口号headers = {"User-Agent": UserAgent().random}proxies = {'http': 'http://' + ip_port# 'https': 'https://'+ip_port}'''http://icanhazip.com访问成功就会返回当前的IP地址'''try:p = requests.get('http://icanhazip.com', headers=headers, proxies=proxies, timeout=3)item = [] # 将可用ip写入csv中方便读取item.append(df["ip"][i])item.append(df["port"][i])item.append(df["place"][i])verify_ip.append(item)print(ip_port + "成功!")except Exception as e:print("失败",e)return verify_ip最终运行:
将上面全部功能模块合并在一起就搭建完成啦!
if __name__ == '__main__':# ----------爬取与保存------------save_path = "test.csv"city_num = int(input("需要爬取几个城市ip")) # 1~34之间,该网站只有34个城市页面content_list = []for i in range(city_num): # 批量爬取list_ip关键信息并保存response = get_list_ip(i)list = dispose_list_ip(response)content_list += list # 将每一页获取的列表连接起来print(content_list)save_list_ip(content_list,save_path)# -----------验证--------------open_path = "test.csv"ip = verify_ip(open_path)# ---------保存验证结果-----------save_path = "verify_ip.csv"save_list_ip(ip,save_path)




![mysql一张表复制到另外一张表,报错[23000][1062] Duplicate entry ‘1‘ for key ‘big_2.PRIMARY‘](https://img-blog.csdnimg.cn/img_convert/0e88983003b16ef11aae3a22819d5821.png)


![[23000][1452] Cannot add or update a child row: a foreign key constraint fails (`test2`.`#sql-1238_5](https://img-blog.csdnimg.cn/8290f2862edd4b0384d8e3811d2b6f8c.gif)
![[23000][1062] Duplicate entry ‘6‘ for key ‘PRIMARY‘](https://img-blog.csdnimg.cn/dd6f11dc96204dccaaaac85d7085be65.gif)
![SQLSTATE[23000]: Integrity constraint violation:1062 Duplicate entry1664187678631531497821000‘ 解决办法](https://img-blog.csdnimg.cn/79832d39af8c43f2bf67e08f5da5ffd2.png)