疲惫的生活里总要有些温柔梦想吧

目标URL:http://www.win4000.com/meinvtag4_1.html
爬取美桌网某个标签下的美女壁纸,点进详情页可以发现,里面是一组套图
一、网页分析
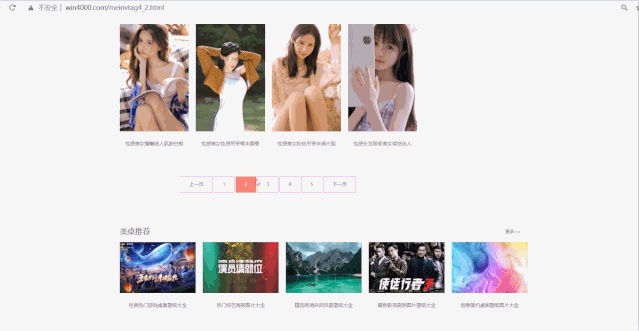
翻页查看 URL 变化规律:
http://www.win4000.com/meinvtag4_1.htmlhttp://www.win4000.com/meinvtag4_2.htmlhttp://www.win4000.com/meinvtag4_3.htmlhttp://www.win4000.com/meinvtag4_4.htmlhttp://www.win4000.com/meinvtag4_5.html页面里看到的每张图片点击进去有详情页,里面是套图
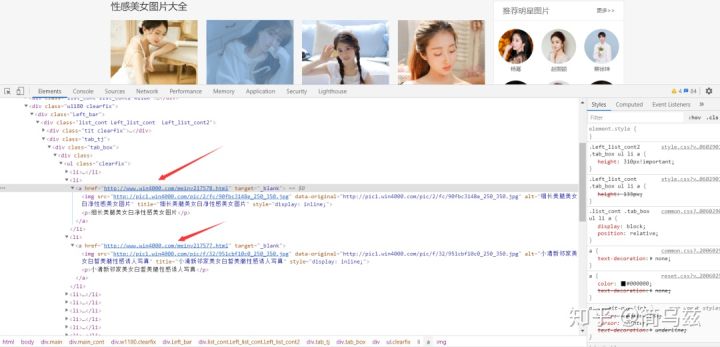
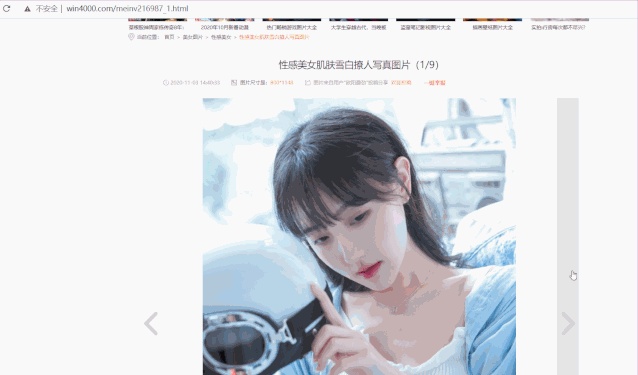
详情页里套图URL变化规律:
http://www.win4000.com/meinv216987_1.htmlhttp://www.win4000.com/meinv216987_2.htmlhttp://www.win4000.com/meinv216987_3.html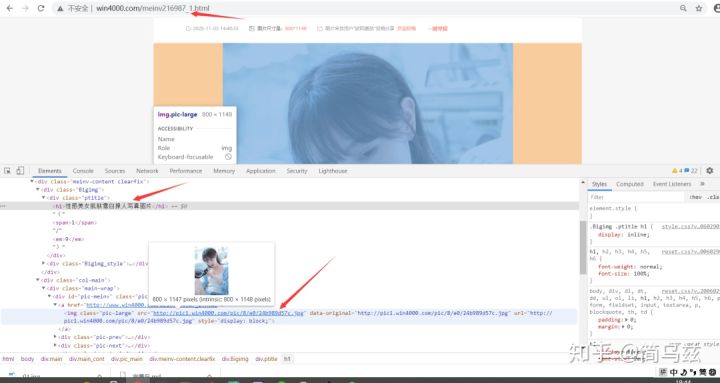
在网页源代码中也可以直接找到数据:
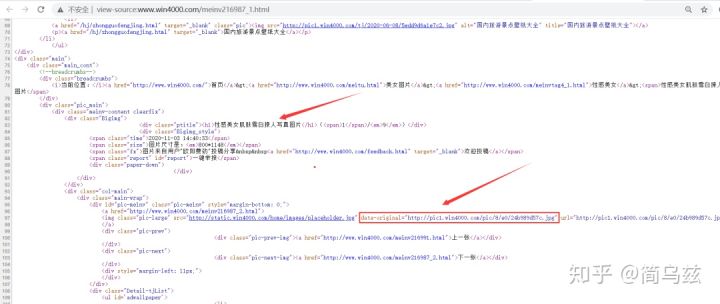
图片名称 下载链接性感美女肌肤雪白撩人写真图片http://pic1.win4000.com/pic/8/e0/24b989d57c.jpg二、爬虫基本思路
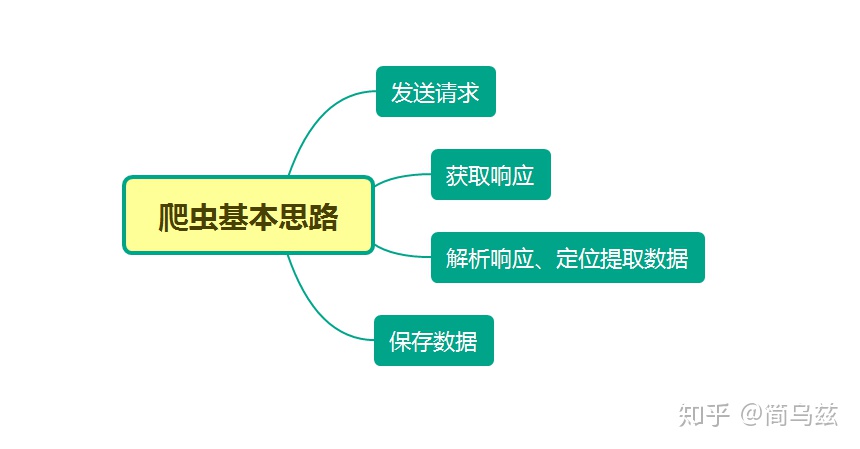
1. 获取5页的套图的URL
def get_taotu_url():for i in range(1, 6):url = f'http://www.win4000.com/meinvtag4_{i}.html'headers = {'User-Agent': choice(user_agent)}# 发送请求 获取响应rep = requests.get(url, headers=headers)# print(rep.status_code) 状态码 200# print(rep.text)html = etree.HTML(rep.text)taotu_url = html.xpath('//div[@class="tab_tj"]/div/div/ul/li/a/@href')# 过滤掉无效的urltaotu_url = [item for item in taotu_url if len(item) == 39]# 一个页面有24个图片print(taotu_url, len(taotu_url), sep='\n')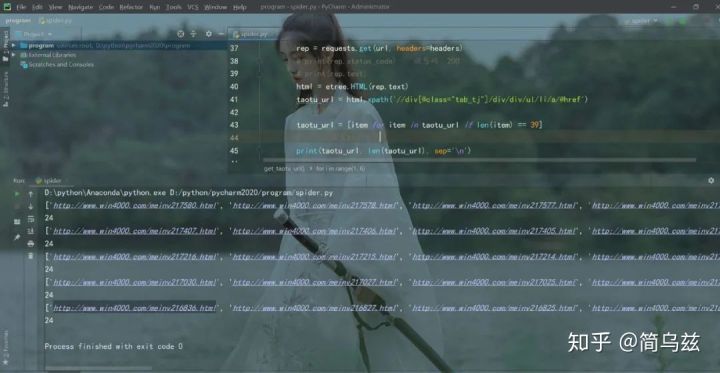
2. 进入套图详情页爬取图片def get_img(url):headers = {'User-Agent': choice(user_agent)}# 发送请求 获取响应rep = requests.get(url, headers=headers)# 解析响应html = etree.HTML(rep.text)# 获取套图名称 最大页数name = html.xpath('//div[@class="ptitle"]/h1/text()')[0]os.mkdir(r'./女神套图/{}'.format(name))max_page = html.xpath('//div[@class="ptitle"]/em/text()')# 字符串替换 便于之后构造url请求url1 = url.replace('.html', '_{}.html')for i in range(1, int(max_page[0]) + 1):url2 = url1.format(i)sleep(randint(1, 3))reps = requests.get(url2, headers=headers)dom = etree.HTML(reps.text)src = dom.xpath('//div[@class="main-wrap"]/div[1]/a/img/@data-original')[0]file_name = name + f'第{i}张.jpg'img = requests.get(src, headers=headers).contentwith open(r'./女神套图/{}/{}'.format(name, file_name), 'wb') as f:f.write(img)print(f'成功下载图片:{file_name}')