以下内容完全由本人在实际操作中搜集整理总结得到,很细致的介绍:从如何在stata中导入数据,怎么定义面板数据,再到如何做局部和全局空间相关性检验(莫兰指数)和空间杜宾模型等。
1、导入面板数据
在excel中输入如下格式的数据:
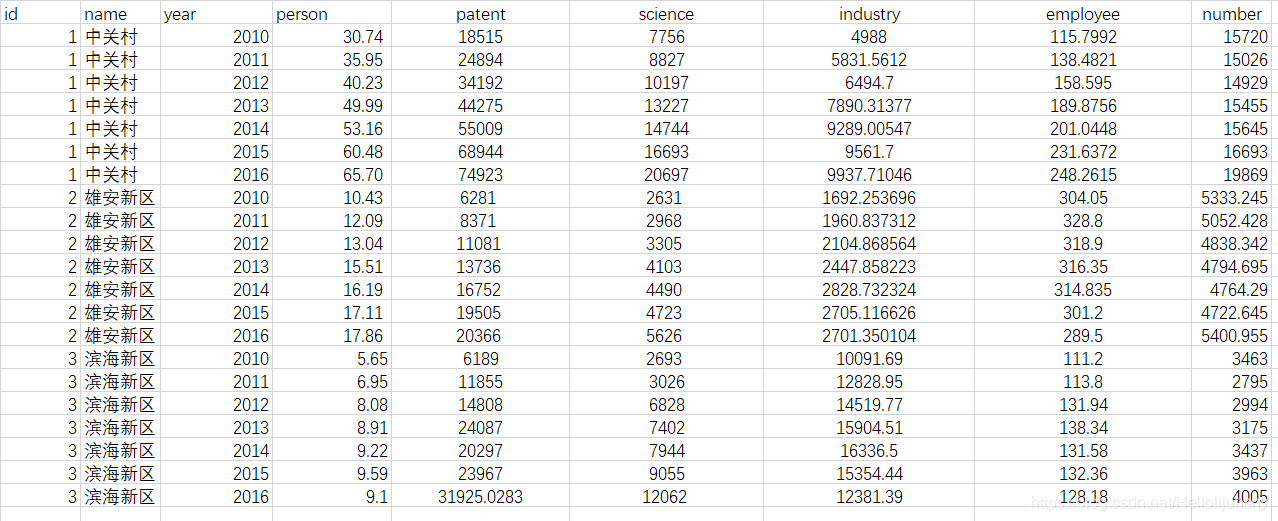
打开STATA,data-data editor- data editor(edit),将excel中数据复制上去
接着在STATA主界面的command窗口输入:xtset id year或tsset id year,并回车,这样STATA就知道id是个体,year是时间的面板数据了,面板数据形成!!!


面板数据已输入完成
需要取对数的话,输入gen lny=ln(y) 取对数;gen Lag_invest = L.invest产生一阶滞后
2.莫兰指数
(1)计算空间矩阵
执行命令:spatwmat using w.dta, name(w) standardize
注:加上standardize表示对空间矩阵进行行标准化;w为提前输入的空间矩阵,空间矩阵有邻接权重、距离矩阵、经济权重等,在本例其形式是三行三列的形式,且顺序要和导入的面板数据个体顺序一致。
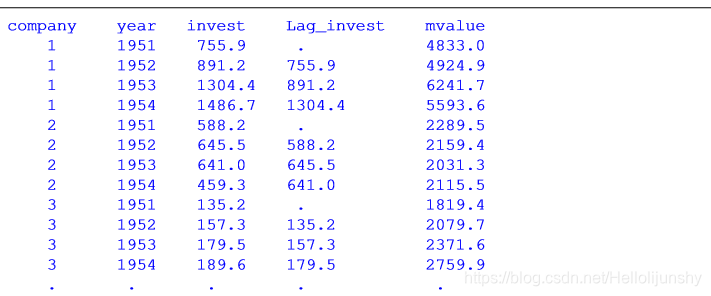
(2)全局Moran‘s I和Geary’s c指数
计算各变量Moran‘s I,Geary’s c及其单侧检验概率,执行命令:spatgsa person, weights(W) moran geary
注:person是某一变量名字

计算各变量Moran‘s I,Geary’s c及其双侧检验概率,执行命令:spatgsa person, weights(W) moran geary twotail
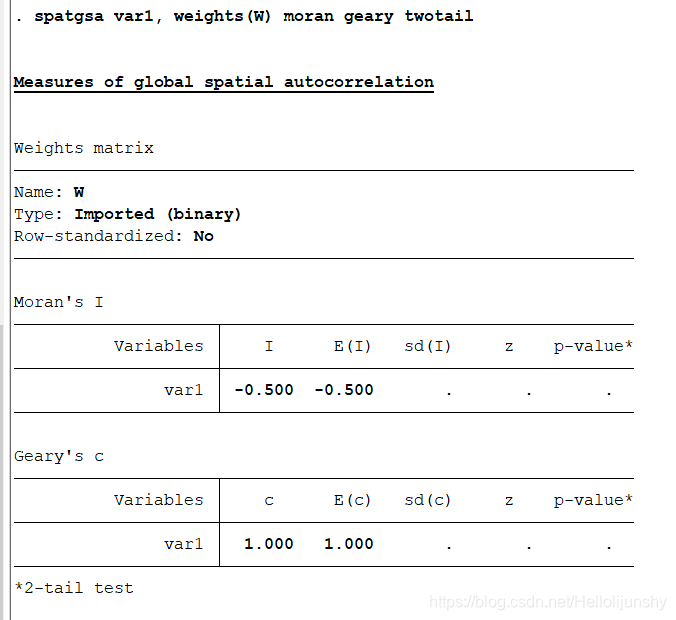
(3)局部Moran‘s I
执行命令:spatlsa person, weights(W) moran
注:这是未标准化的莫兰指数,不能画局部莫兰指数图
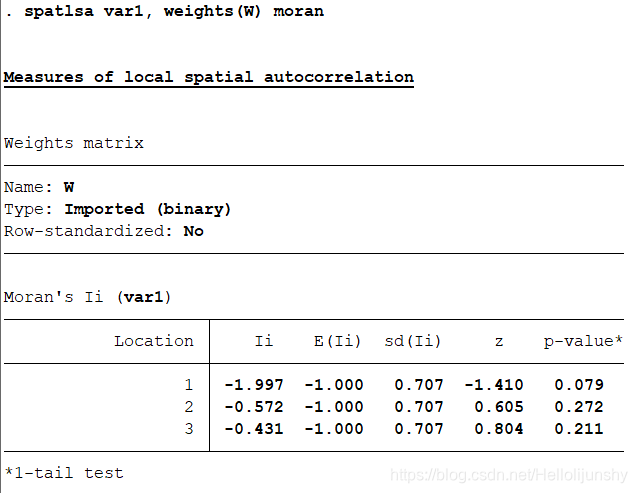
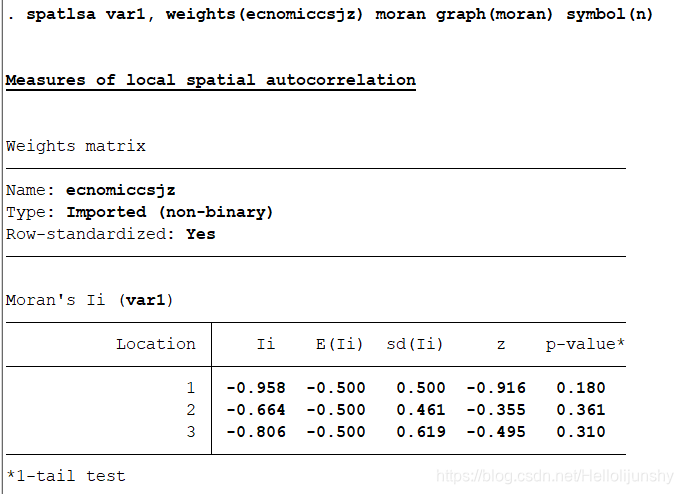
执行命令:spatlsa person, weights(WW) moran graph(moran) symbol(n)
注:这是行标准化过的空间权重矩阵,ww为标准化的空间矩阵,下图用的ecnomicsjz是另一个经过行标准化的空间矩阵,道理都一样,只是变量名字不同。
3.变量的描述性展示(最大值、最小值、均值等)
(1)声明截面变量和时间变量,执行命令为tsset id year(同上)
命令执行后屏幕上会显示:

(2) 进行样本的描述性统计。首先我们看看样本的大体分布情况,命令为:xtdes 命令执行后屏幕上会显示:

注:若出现data not st的报错,说明数据不是survival-time形式,需要设定一下,在网上很轻易能搜到解决方案,需要在stata里下载一个命令去解决。
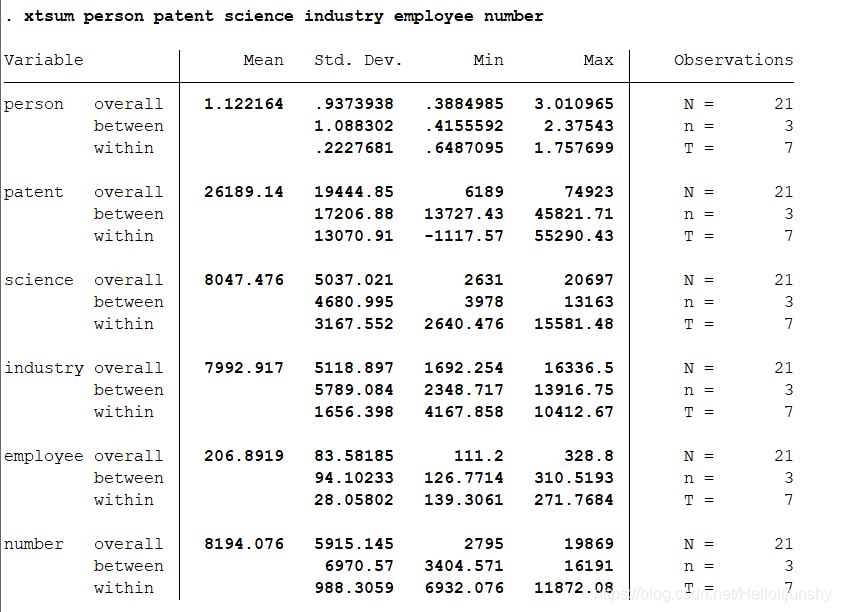
其次,看各个变量的情况,命令为:xtsum person patent science industry employee number命令执行后屏幕上会显示各个变量最大最小值、均值等信息:
4.判断是选择固定效应还是随机效应
(1)先做固定效应面板数据模型回归方程结果,命令为:xtreg person patent science industry employee number,fe命令执行后屏幕上会显示:
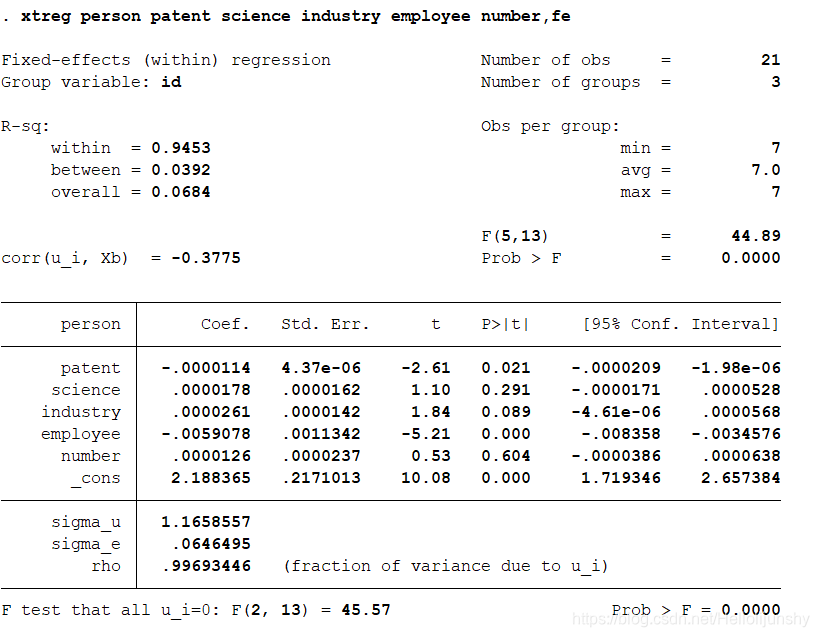
结果的前两行列示了模型的类别(本例中为固定效应模型)、截面变量、以及估计中使用的 样本数目和个体的数目。第 3 行到第 5 行列示了模型的拟合优度,分为组内、组间和样本总体三个层次。第6行和第7 行分别列示了针对参数联合检验的F统计量和相应的 P 值,本例中分 别为 44.89和 0.0000,表明参数整体上相当显著。第 8-11 行列示了解释变量的估计系数、标准 差、t统计量和相应的P值以及 95%置信区间,这和我们在进行截面回归是得到的结果是一样 的。最后四行列示了固定效应模型中个体效应和随机干扰项的方差估计值(分别为 sigma u 和 sigma e )、二者之间的关系(rho)。最后一行给出了检验固定效应是否显著的 F 统计量和相 应的 P 值,本例中固定效应非常显著。
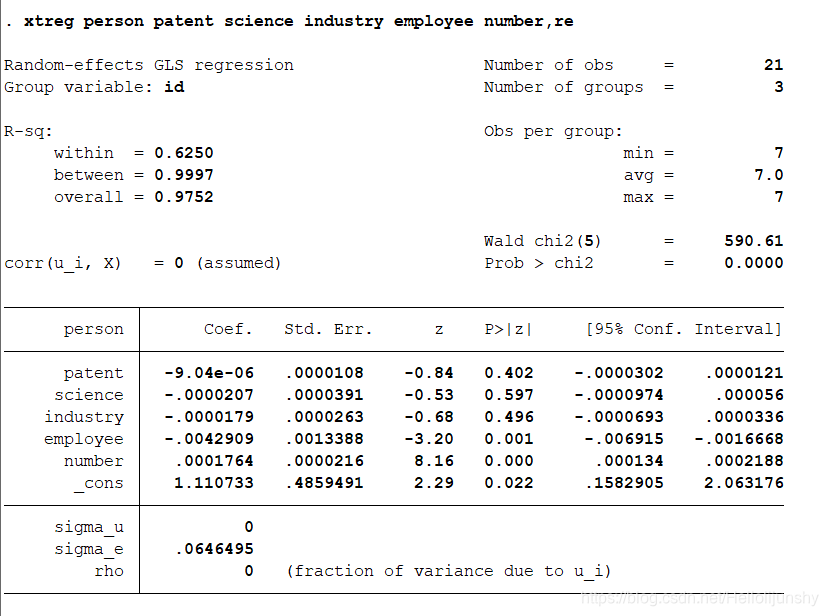
估计随机效应的命令为:xtreg person patent science industry employee number,re 命令执行后屏幕上会显示:
(2) 模型效应的筛选和检验。
第一步:检验个体效应的显著性(混合效应还是固定效应好)(原假设:使用OLS混合模型)。执行命令:xtreg person patent science industry employee number,fe,刚才我们做固定效应模型时,F 检验表明固定效应模型优于混合 OLS 模型。下面我们说明如何检验随机效应是否显著,【建议做完第一步,直接做第三步hausman检验即可】
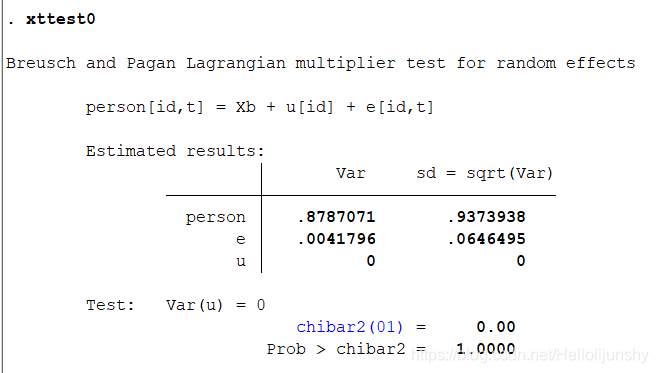
第二步:检验时间效应的显著性(混合效应还是随机效应好)(检验方法:LM统计量)命令为:xttest0
P 值为 1.0000,表明随机效应非常不显著,混合效应非常显著 。
第三步:hausman检验
步骤:
step1:估计固定效应模型,存储估计结果;
step2:估计随机效应模型,存储估计结果;
step3:进行Hausman检验;
命令为:lnlocation lnindustrialization lnrd lnpatent lnexport lnemployee
qui xtreg person patent science industry employee number , fe
est store fe
qui xtreg person patent science industry employee number , re
est store re
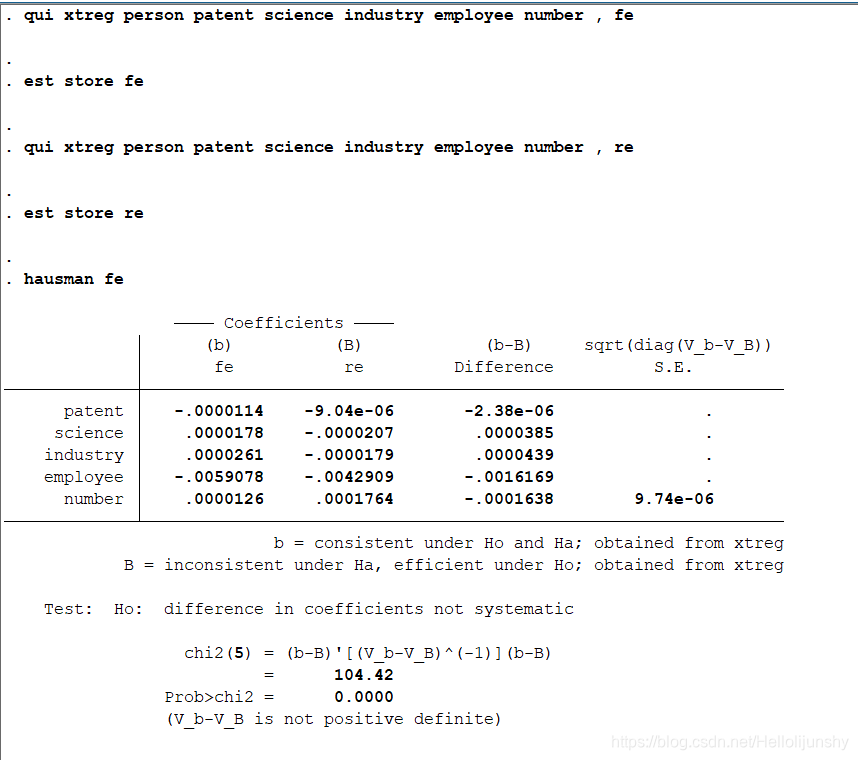
hausman fe
这里,qui 的作用在于不把估计结果输出到屏幕上,est store 的作用在于把估计结果存储到名称 为 fe 的临时性文件中
我们注意到输出结果的最后一行提示说固定效应模型和随机效应模型的参数估计方差的差是一 个非正定矩阵,因此 sqrt(diag(V b-V B)) 一项全为缺失值。这是在进行 Hausman 检验过程中经 常遇到的问题,有时我们还会得到负的 chi2 值。产生这些情况的原因可能有多种,但我认为一 个主要的原因是我们的模型设定有问题,导致 Hausman 检验的基本假设得不到满足。这时,我们最好先对模型的设定进行分析,看看是否有遗漏变量的问题,或者某些变量是非平稳的等 等。在确定模型的设定没有问题的情况下再进行 Hausman 检验,如果仍然拒绝原假设或是出现上面的问题,那么我们就认为随机效应模型的基本假设(个体效应与解释变量不相关)得不到满足。此时,需要采用工具变量法或是使用固定效应模型。
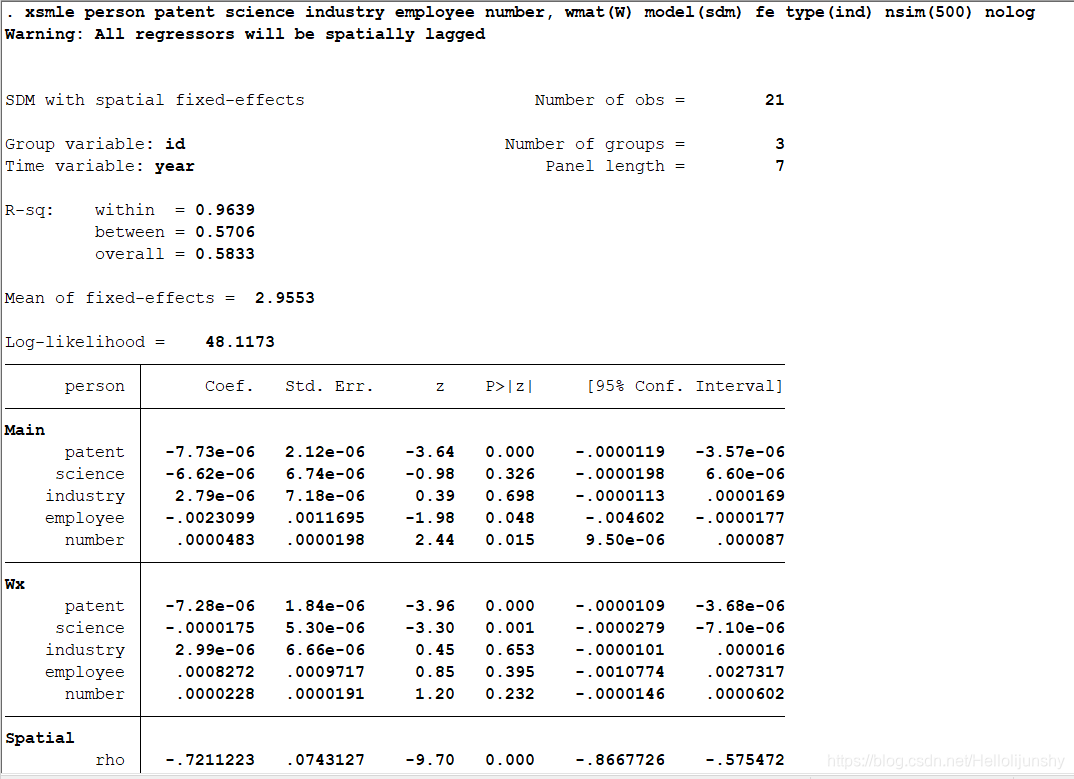
5带固定效应的空间面板杜宾模型
Stata命令:xsmle person patent science industry employee number, wmat(W) model(sdm) fe type(ind) nsim(500) nolog effects
其中W为已建立好的权重矩阵,加上effect会输出直接效应、间接效应等,不加effect只会输出各个变量的系数等,但文献上大多数是用直接效应和间接效应分析,因为系数可能不准确。

来源于Hellolijunshy 的CSDN 博客,如有侵权,联系删除!