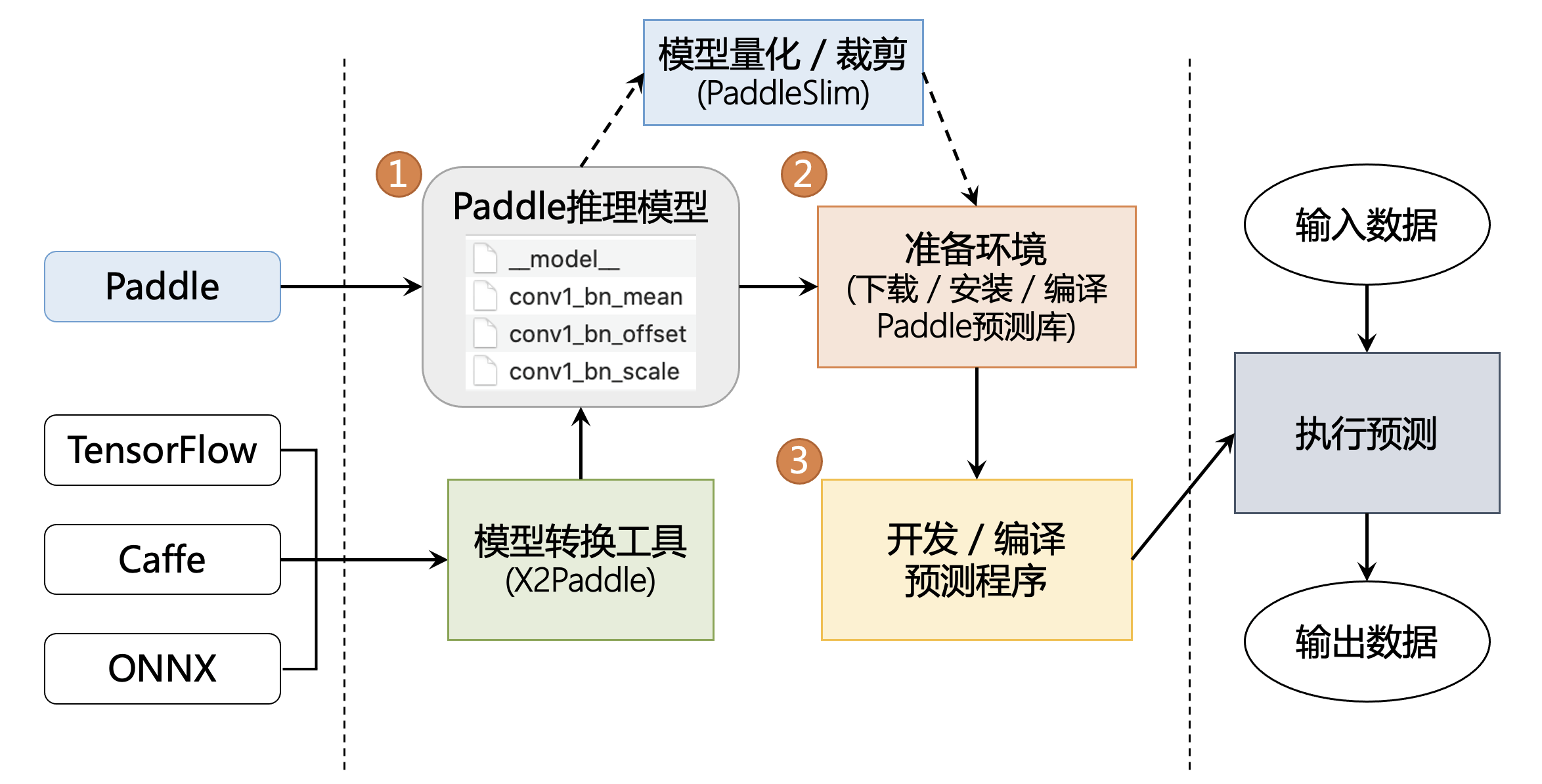
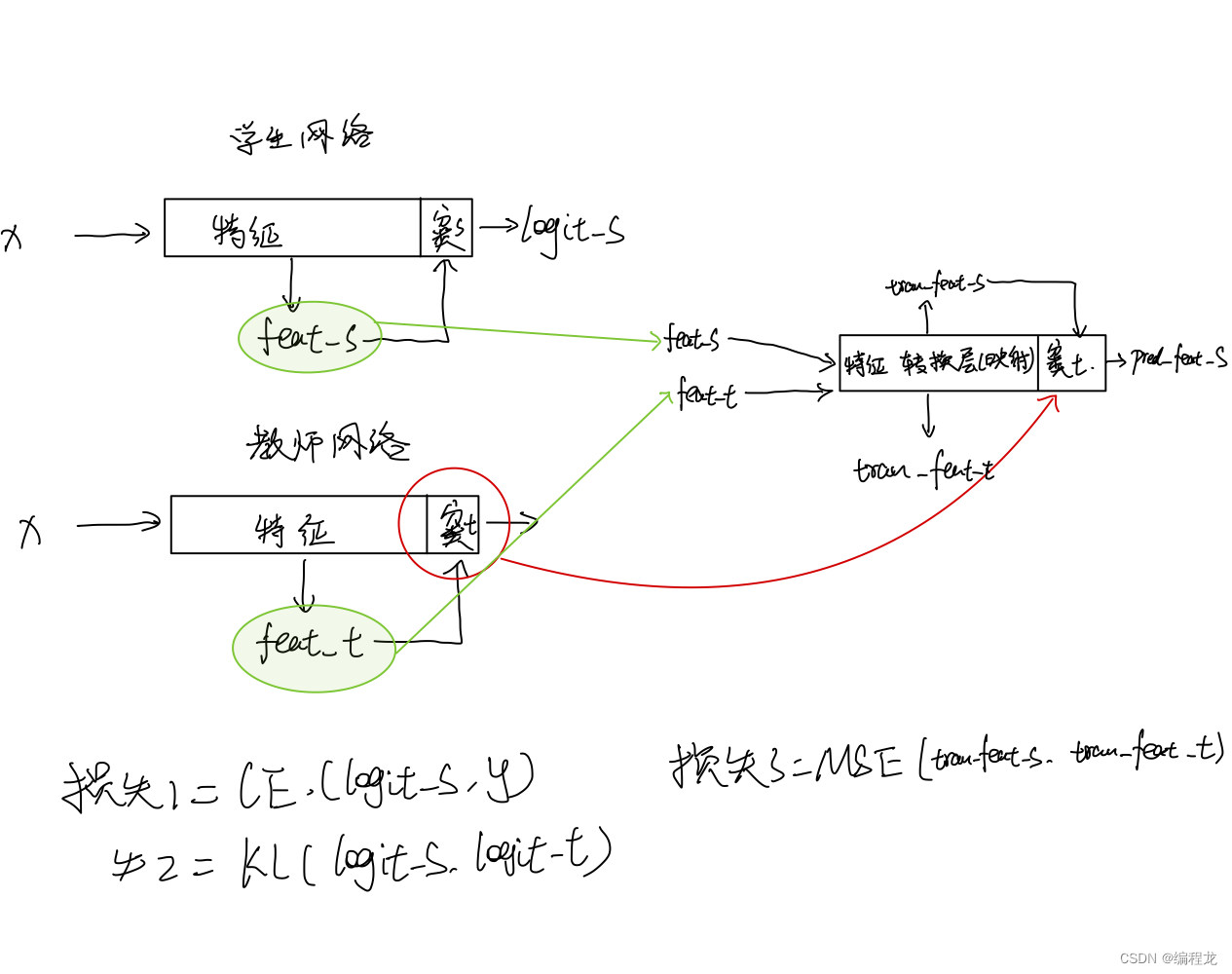
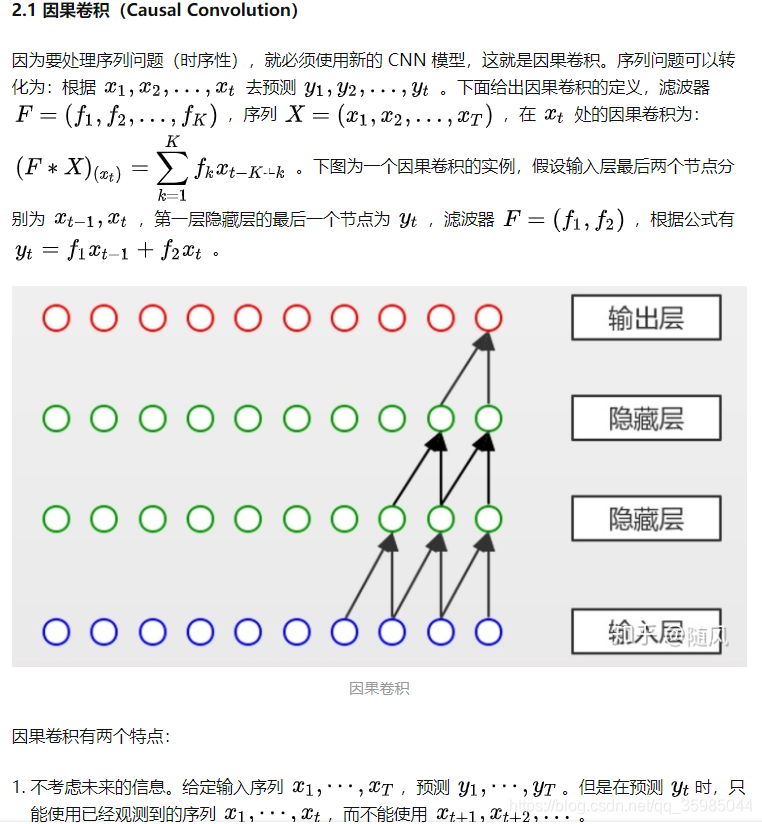
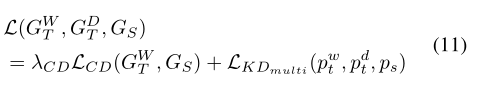一、空间杜宾模型
1.空间杜宾模型形式
空间杜宾模型(SDM)是空间滞后模型和空间误差项模型的组合扩展形式,可通过对空间滞后模型和空间误差模型增加相应的约束条件设立。空间杜宾模型(SDM)是一个通过加入空间滞后变量而增强的SAR模型(空间滞后模型)。即:
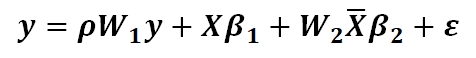
式中𝑾𝟏是因变量的空间相关关系,
空间杜宾模型(SDM)是空间滞后模型和空间误差项模型的组合扩展形式,可通过对空间滞后模型和空间误差模型增加相应的约束条件设立。空间杜宾模型(SDM)是一个通过加入空间滞后变量而增强的SAR模型(空间滞后模型)。即:
式中𝑾𝟏是因变量的空间相关关系,