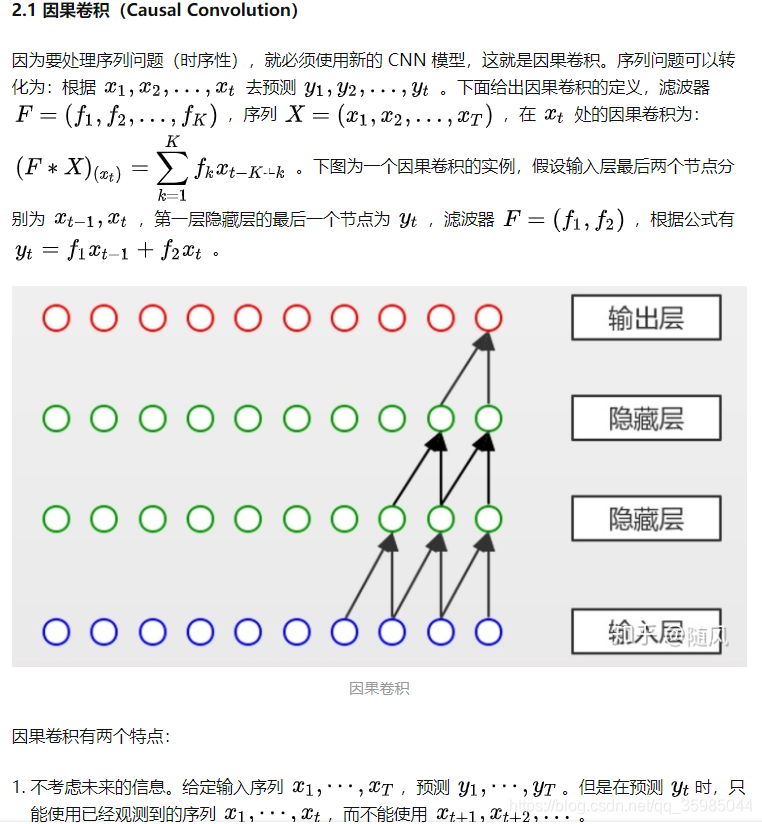
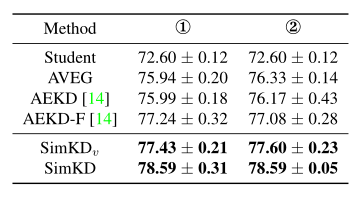
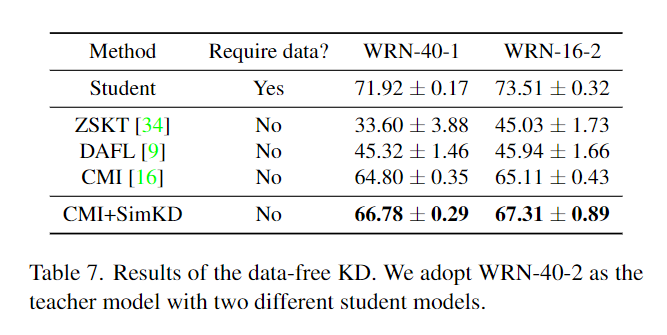
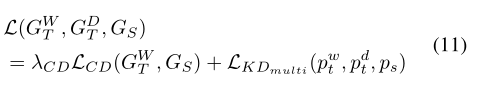目录
摘要
引言
相关工作
方法
框架和损失函数
方法特色
实验
不同的共享结构
CIFAR-10
rocket和AT的中间层注意图的可视化
结论
摘要
提出了用好网络帮助小网络训练的新的统一框架
这个框架中,好网络全程都在帮助小网络学习
分析了不同的loss的效果
用叫做gradient block的技巧同时提升了小网络和好网络的性能
引言
- 之前
分解和压缩解决推理时间长的问题,有矩阵SVD,MobileNet以及ShuffleNet
知识蒸馏,有KD,Fitnets
- 本文工作
名字叫做rocket launching
booster对应深的复杂的teacher,light net是student
light net和booster net都是这个架构的组成成分,训练的时候都参与训练
light net在训练过程中会学习booster net的知识
- 总结
设计了一个统一叫做rocket launching的架构,booster全程对student监督,student可以达到接近booster的效果
分析了不同的知识蒸馏函数
设计了gradient block技巧,使得booster在训练的时候不受light net的影响,给了booster更多的自由性
相关工作
- 简化计算和裁剪
SVD近似卷积
深度可分离卷积( MobileNets )
pointwise组卷积和通道的打乱(ShuffleNet)
用下一层的数据信息裁剪当前层的filters(ThiNet )
- teacher-student
用集成模型标记没有标签的数据,将数据用来训练小网络,表明大网络的知识可以迁移到小网络中
有论文使用softmax前的logits作为要迁移的知识,训练小网络
KD,用了T来放大输出概率的分布信息,证明了T无限大时,logits的方法是它的特例
用中间层的信息作为要迁移的知识(Fitnets)
用多层的信息,但是用attention map作为要迁移的知识
- 本文和之前做法的不同点
booster会在自己训练的整个过程的同时提供给light net知识,这是因为light net不仅仅需要最后尘埃落定后的知识,还需要整个训练过程的优化走向知识,也就是说怎么走到终点也是一个重要的要传递的知识
booster和light net底层的参数是共享的,这是因为同样的任务,低层次的特征表达应该是相同的
方法
框架和损失函数
- 框架
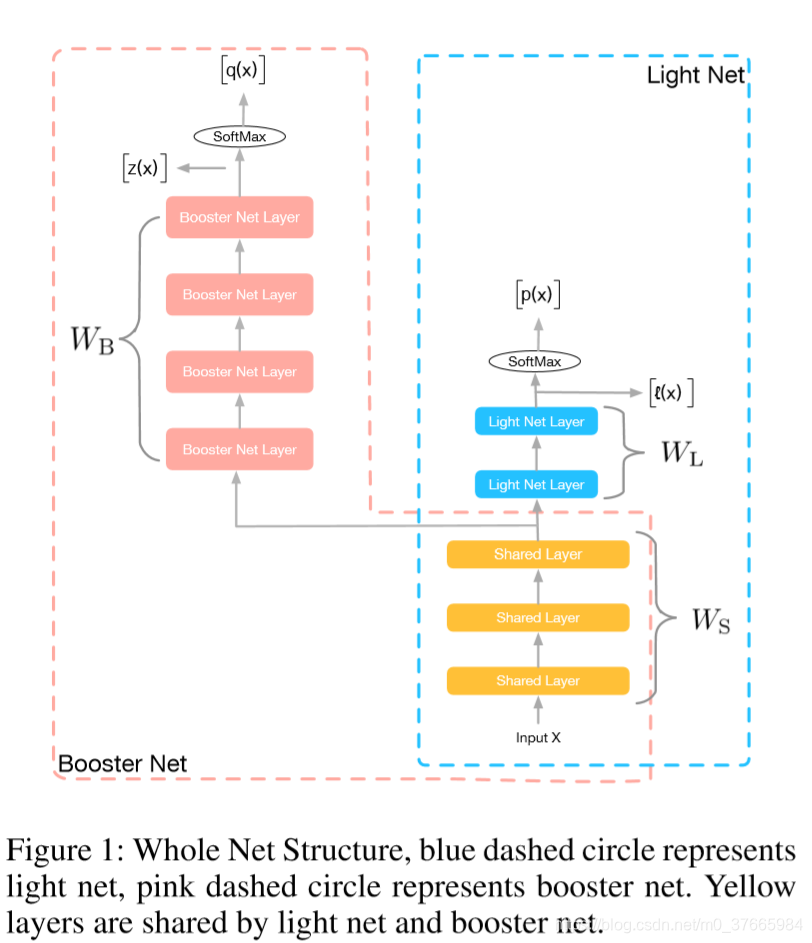
粉红色框是booster,蓝色框是light net
黄色块是共享参数,粉色块是booster的参数,蓝色块是light net的参数
- 损失函数
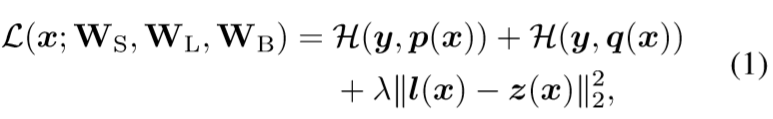
x是输入,y是标签,Ws是共享参数,Wl是light net的参数,Wb是booster的参数
H是普通交叉熵损失,两个交叉熵加一个监督损失
l(x)表示booster中从输入到softmax之前的logits的映射
z(x)表示light net中从输入到softmax之前的logits的映射
lamda权证两个损失的超参数
方法特色
- 参数共享
直接从booster中获取推力,带动light net获取更好的性能
多任务学习以前就有,计算机视觉中,假设多个任务的低层表达信息是类似的,可以通过共享参数来减少推理时间
另有论文表明共享参数可以帮助减少收敛时间
- 同时训练
同时训练使得light net不仅可以学到booster网络的最终的输入,而且可以学到booster是怎么一步一步走到最终的结果的,这个过程教导是之前的知识蒸馏方法没有的
- Hint loss
考虑以下三种知识蒸馏的损失函数:
MSE of final softmax:
![]()
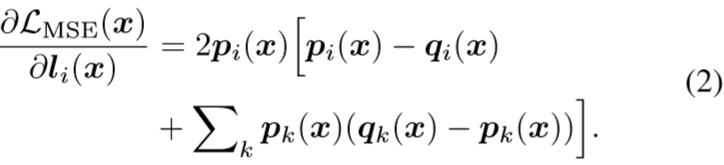
可以看到导数是跟输出的概率值成比例关系的,如果输出的概率接近于0,就算和真正的teacher的概率差别很大,梯度也会接近于0,有梯度消失的问题
MSE of logits before softmax activation
![]()
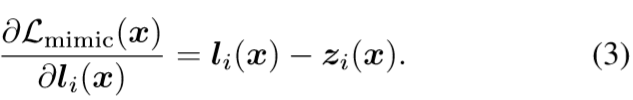
可以看到梯度直接是student和teacher的logits的差距,没有梯度消失的问题,在这几种loss中效果最好
knowledge distillation
![]()
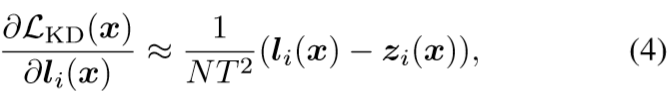
![]()
当T非常大时,KD原论文推到出logits是它的特例
不得不说这里的推导实在牵强的很,推到过程会用到如上所示的泰勒展开越等式,省掉了![]() 项,注意到(4)式是与它同等级的,那么按理说(4)式也可以忽略。。。
项,注意到(4)式是与它同等级的,那么按理说(4)式也可以忽略。。。
我认为这里省略掉的无穷小跟结果同级的情况下,得到的跟(3)式成比例的结论是靠不住的,因为假如考虑到被省略的无穷小的因素,完全可能会影响最终的同级别的无穷小的结果,导致结果不跟(3)式成比例
本论文的作者对推到差生了质疑,但是又肯定了以下的推论:
在T非常小的情况下,梯度会接近于pi-qi,所以当多个类别的qi接近于0时,最终输出的相似性信息是没有体现在梯度中的,所以网络会忽略掉这些信息;当T非常大的情况下,梯度会接近li-zi,这时的梯度是logits之间的差,就算最终的概率值都很小的情况下,由于logits的值并不小,而且logits之间也是有明显区别的,所以也会将概率接近于0的类别的相似性信息考虑到
所以KD原作者认为T取一个不过大的值效果好是有道理的,这会使得网络忽略掉一些值太小的类别间的差异,而这些差异很可能是噪音造成的;而本论文的作者通过实验表明logits蒸馏的效果最好,他认为这些值非常小的类别间的差异仍然是有用的
- Gradient block
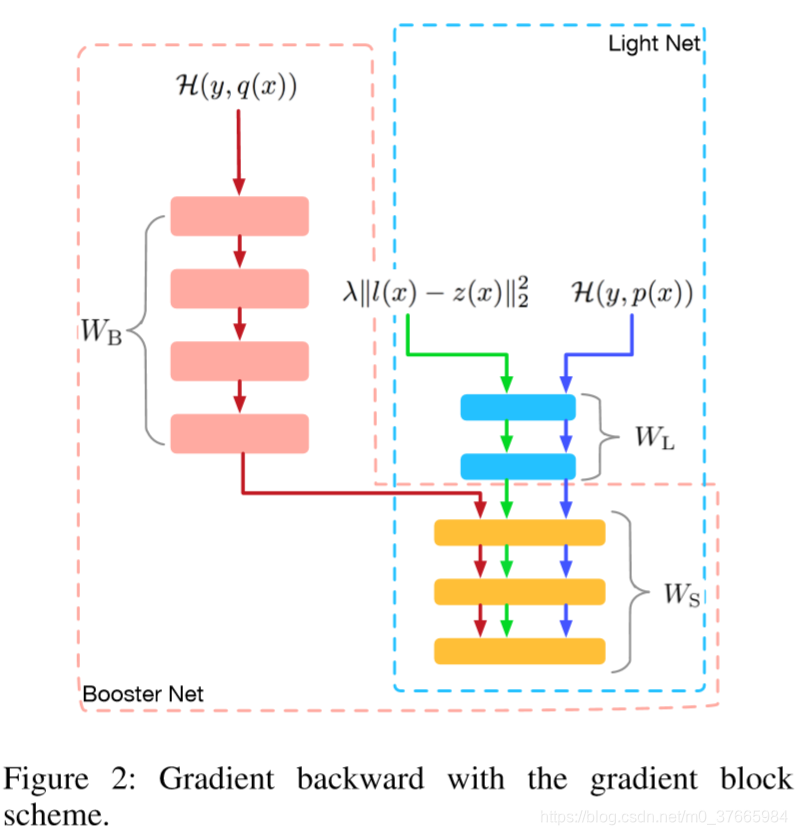
booster和light net同时训练时,hint loss会阻止booster直接从target中训练,从而影响到他的表现,而light net的知识又是从booster中来的,这也会进而影响到light net的表现
为了解决这个问题,作者采用gradient block阻止hint loss传入booster,这使得Wb不接受来自于hint loss的导数
实验
不同的共享结构
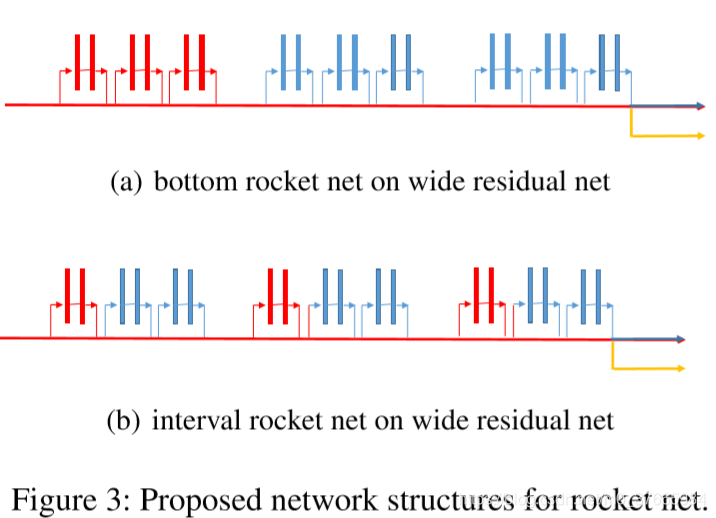
Figure 3中红色块时共享块
蓝色块时booster的独立块
黄色箭头指向light net的独立块
由于attention transfer不能直接在整个体系中直接实现(因为AT需要在每个块的结尾做知识监督,而若第一个块全用来共享,就不能再做知识监督了),所以实现了(b)的共享模式
CIFAR-10
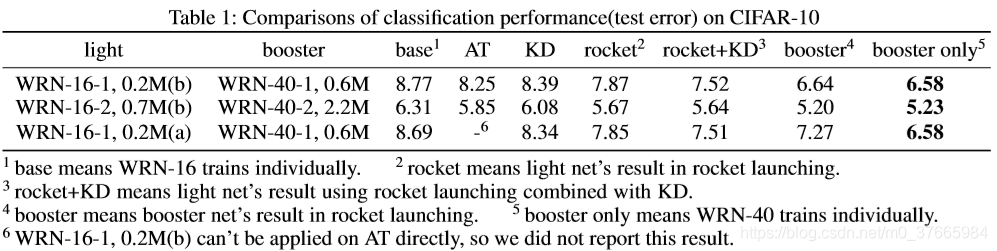
从表中可以看出rocket的效果要好于AT和KD的效果
并且rocket和KD相结合可以使最终的结果再次提升,这说明rocket和KD有不同的优化方向,是互补的
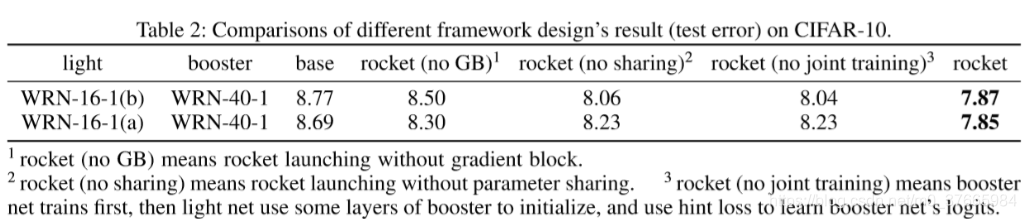
从表中可以看出每一个技巧都是有效的
rocket和AT的中间层注意图的可视化

可以看到,rocket(Figure 5(b))对于注意力图的学习力还要稍微强于AT(Figure 5(a))的能力
结论
提出了一种高效的叫做rocket launching的知识蒸馏框架
booster和light net同时训练,帮助light net学习整个优化的过程知识
booster和light net共享参数,使light net直接利用booster的底层表达能力
分析不同hint loss的影响
用gradient block技巧防止hint loss对booster网络造成不好的影响