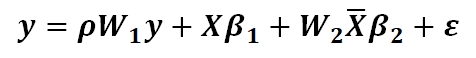T个周期,N个地区,K个解释变量。
1.基准面板回归模型
其中,x1为核心的解释变量,其余为控制变量。
2.空间面板滞后模型SPLM
其中,W为n*n阶距离矩阵,为空间滞后系数。揭示了邻近地区Y值对本地区Y值的影响效应。
3.空间面板杜宾模型SPDM
其中,是长度为K的向量,代表K个解释变量的空间滞后系数。揭示了领近地区X值对本地区Y值的影响效应。
Lesage(2009)指出空间溢出效应研究无法通过SPDM模型估计系数真实反映,要进一步采用偏微分方程来度量。
(每次都要写的清清楚楚明明白白我才会算矩阵的偏微分...)
考虑解释变量对被解释变量
的影响效应,计算如下。
,其中w11=0
式(14)对角线元素为对
的直接效应,非对角线元素为 为
对
的间接效应(溢出效应),总效应=直接效应+间接效应。
式(14)每一行反映了地区i受到本地区的直接影响和其他地区
的间接影响情况。每一列反映了
地区i的对本地区
的直接影响和对其他地区
的间接影响情况。