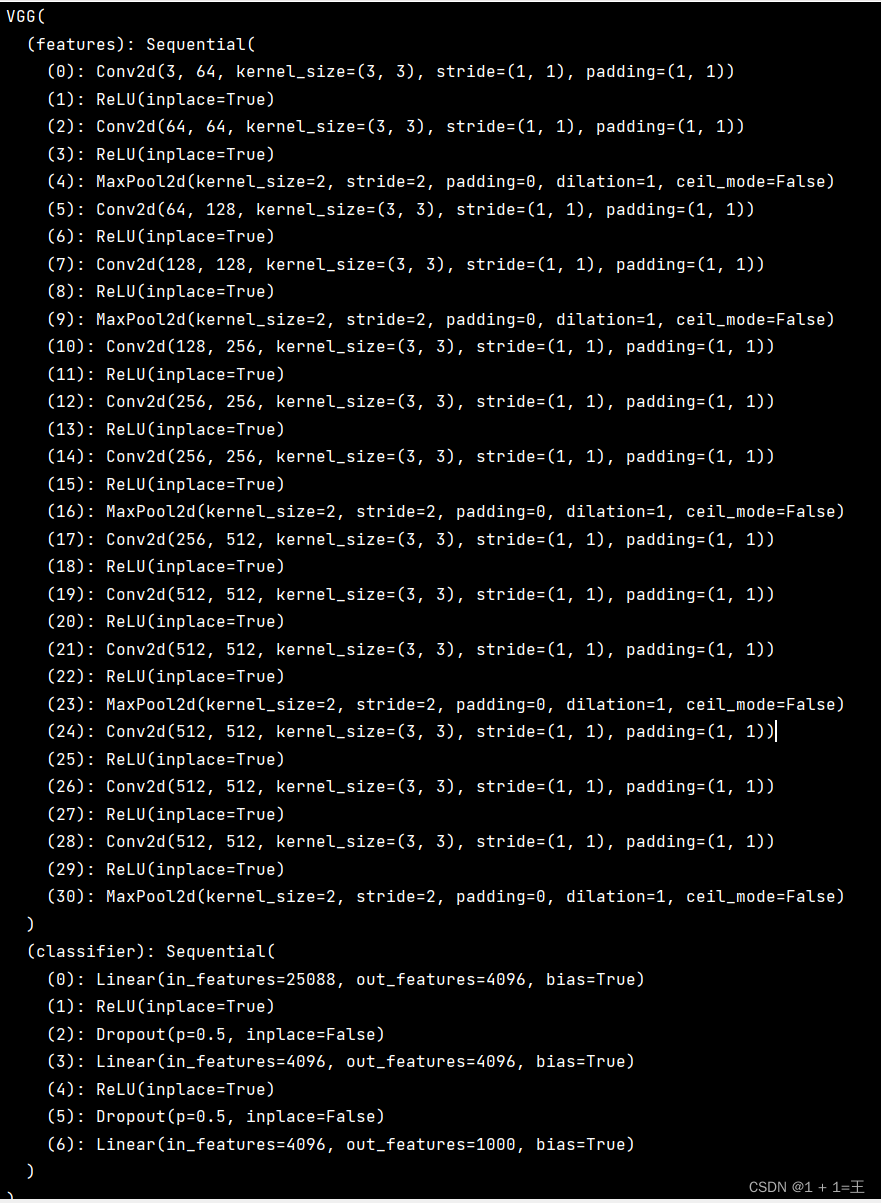
文章目录
- 过拟合
- 欠拟合
- 泛化能力
- 避免过拟合的一般方法
- 从数据集上规避
- 从训练模型上规避
- 从训练过程上规避
作为从「统计学(Statistics)」跟「计算机科学(Computer Science)」交叉而诞生的新学科「机器学习(Machine Learning)」,从诞生的那一刻,基因里就带上了很多来自统计学的概念。
我们用于处理类似「分类(Classification)」、「回归(Regression)」、「聚类(Clustering)」、「降维(Dimensionality Reduction)」以及「强化学习(Reinforcement)」等问题而设计的「机器学习模型(Machine Learning Model)」不可避免会遇到以下三个问题:
- 我们的模型是否合适(fitting)?
- 我们的模型是否与样本过拟合(overfitting)?
- 我们的模型是否与样本欠拟合(underfitting)?
在回答这些问题前,我们先从统计的角度解释什么是拟合、过拟合以及欠拟合。
过拟合
在统计学中,过拟合是指我们设计的模型过于紧密或精确的匹配了某特定数据,使得模型缺少泛化能力,而无法有效处理其他的、或未观测的数据的现象1。
欠拟合
欠拟合的概念恰恰与过拟合相反;它是指相对于数据而言,我们的预测模型过于简单,无法有效反应数据的特征规律,因此也缺少了泛化能力。

为了更好的帮助你理解,我举个不太恰当的栗子
假设有一个厨师,需要给客人准备食物;客人提出的要求是「好吃,好看的食物,最好还是圆的」。
对于 「欠拟合」 的厨师来说,他可能会把味道、样子还凑合的食材当作食物给客人;结果客人吃到了带着鱼鳞的鱼肉,带着芽的土豆,发了霉的花生米,然后把酒店给投诉了。
对于 「过拟合」 的厨师,他可能是个超级强迫症,他不仅会拿着圆规度量土豆是不是足够圆,还要拿着放大镜挑干净肉的每一个毛囊;甚至为了追求豆腐的新鲜度,还要亲自种豆子……于是客人等了一个多小时,什么菜也没吃到,气冲冲的回家然又把酒店给投诉了。
所以对于欠拟合与过拟合来说,最大的问题就是「该做到的事没有做到」,反应在数据上都是 「泛化能力不足」,也就是没有正确地反应数据的特征。既然这里提到了「泛化能力」这个概念,那么接下来我们就来讨论什么是泛化能力。
泛化能力
机器学习的主要挑战是我们的算法必须能够在先前未观测到的新输入上表现良好,而不只是在训练集上表现良好。在未观测到的输入上也能表现良好的能力被称为 泛化(generalization)。2
通常,我们为了评估模型在观测样本上的表现情况,会使用到 「误差」 这个评价指标。常用的一个评价指标,被称为「均方差」,其公式一般写为:
M S E = 1 n ∑ i = 1 n ( x i − μ ) 2 MSE = \frac{1}{n} \sum_{i=1}^{n} (x_i - \mu)^2 MSE=n1i=1∑n(xi−μ)2
这里的 x i x_i xi 通常是指样本值, μ \mu μ 一般是期望。MSE(Mean Square Deviation Error 或 Mean Square Error)越大,表示样本与目标(期望)的离散程度也越大;反之,MSE越小,样本于目标的离散程度越小。
通常情况下,训练机器学习模型时,我们可以使用某个训练集,在训练集上计算一些被称为 训练误差(training error) 的度量误差,目标是降低训练误差。
到目前为止,我们讨论的是一个简单的优化问题。机器学习和优化不同的地方在于,我们也希望 泛化误差(generalization error) (也被称为测试误差(test error))很低2。
简单来说:
- 训练误差 —— 指的是训练集样本与结果的误差;
- 泛化误差 —— 指的是模型预测情况与真实样本的误差;
对于我们来说,比起「训练误差」,我们更关心「泛化误差」,无论对于欠拟合还是过拟合也好,在「泛化误差」上表现都是一致的。如果我们单看这样一张表,就能理解它们之间在训练和真实环境下的表现差异了。
| 拟合类型 | 训练误差 | 泛化误差 |
|---|---|---|
| 欠拟合 | 误差大 | 误差大 |
| 拟合 | 误差适中 | 误差适中 |
| 过拟合 | 误差小 | 误差大 |
在实际训练过程中,随着训练过程的增加,往往会看到这样一组曲线,通常在「惊叹号」位置是我们比较理想的权重,在它左侧一般是「欠拟合」的情况,在它右侧是「过拟合」的情况。

监督学习(例如神经网络)中的过拟合/过训练。训练误差用蓝色表示,验证误差用红色表示。二者均为训练迭代次数的函数。若训练误差稳定下降,但验证误差上升,则说明可能出现过拟合。最佳模型应当是验证误差位于最低点时的模型3。
「欠拟合」通常是训练不足或参数落入「局部最优解」导致的;解决方法也相对简单,比如增加训练量、增加样本数,或者给参数加入「冲量」,而关于「冲量」的内容我会在以后的章节里介绍。
而「过拟合」现象出现的原因相对比较复杂,而且不容易被发现。经验性的,我们通常认为以下三种情况容易出现过拟合现象的发生。
- 训练集样本单一或样本不足;
- 训练集样本的噪声干扰过大;
- 训练模型过于复杂。
避免过拟合的一般方法
在机器学习以及统计学里,我们为了避免上述情况的出现,通常会从三个方面来着手。
- 从数据集上规避;
- 从训练模型上规避;
- 从训练过程上规避。
从数据集上规避
从数据集上规避,首先需要评估数据集的整体情况;比如样本是否符合「简单随机分布」,样本特征是否存在某种「偏见」。如果条件许可,我们可以在处理数据前对数据作一些可视化处理,输出数据的「关联直方图」或者「散点图」,其中一个著名的案例就是「鸢尾花」的特征分布分析。
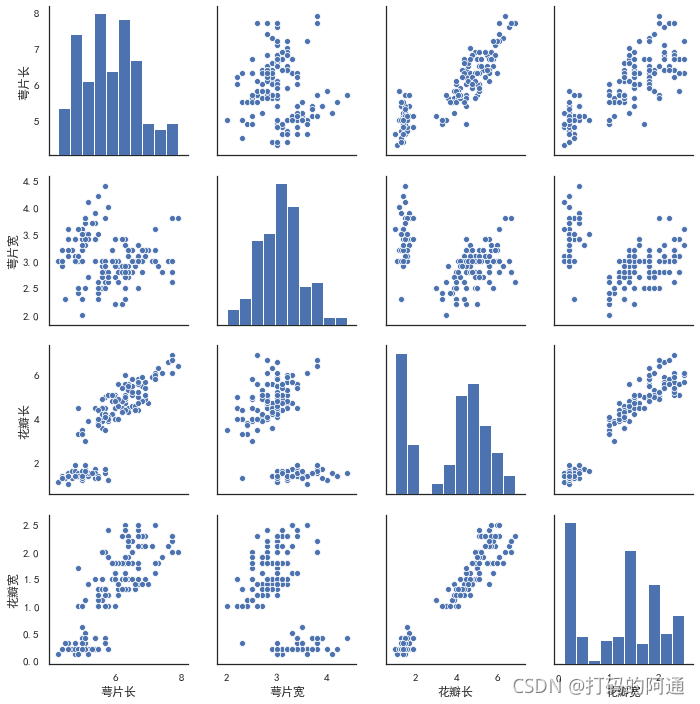
图片来自 https://www.cnblogs.com/cgmcoding/p/13274481.html
如果数据存在某种偏见,条件允许的情况下,可以尝试采集更多的数据样本以减少结果的某种「偏见」。如果不具备这样的条件,可以通过「交叉验证(Cross Validation)」、「正则化(Normalization)」等方法来处理数据。
从训练模型上规避
依据「一般方法论」的原则,能用简单的模型即可得到结果的就应该避免使用复杂的模型。此外,在确定了模型后,也应该依据「贝叶斯信息量准则」,减少不必要的参数使用。对模型和数据必要的「剪枝」也是十分的关键。使用「池化技术」或「Dropout」,减少传递的参数量有时也会十分重要。
从训练过程上规避
我们可以使用一些对付「欠拟合」时用到的方法,比如「冲量」。此外,还可以采用「提前停止」的概念,及时地结束不必要的训练过程;甚至你也可以设置类似于「模拟退火」或者「回滚」的策略,及时的保存训练过程中出现的「全局最优」。
https://zh.wikipedia.org/wiki/%E9%81%8E%E9%81%A9 ↩︎
Ian Goodfellow(伊恩·古德费洛),Aaron Courville(亚伦·库维尔),Yoshua Bengio(约书亚·本吉奥). 深度学习(异步图书) (Chinese Edition) (Kindle Locations 2127-2134). 人民邮电出版社. Kindle Edition. ↩︎ ↩︎
https://zh.wikipedia.org/wiki/%E9%81%8E%E9%81%A9 ↩︎

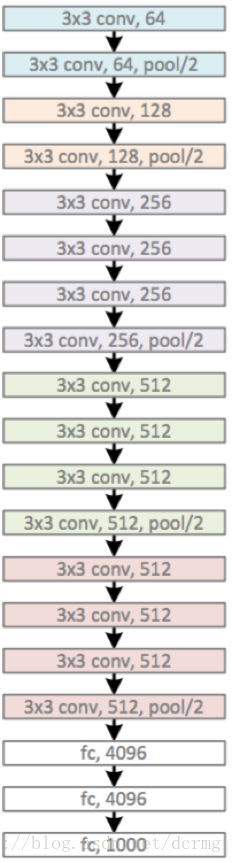







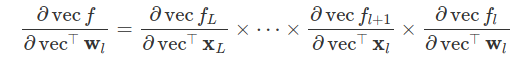



![[VGG16]——网络结构介绍及搭建(PyTorch)](https://img-blog.csdnimg.cn/6b465e7131a343c2b96bf46da7e39b82.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAU3RhcuaYn-Wxueeoi-W6j-iuvuiuoQ==,size_20,color_FFFFFF,t_70,g_se,x_16)