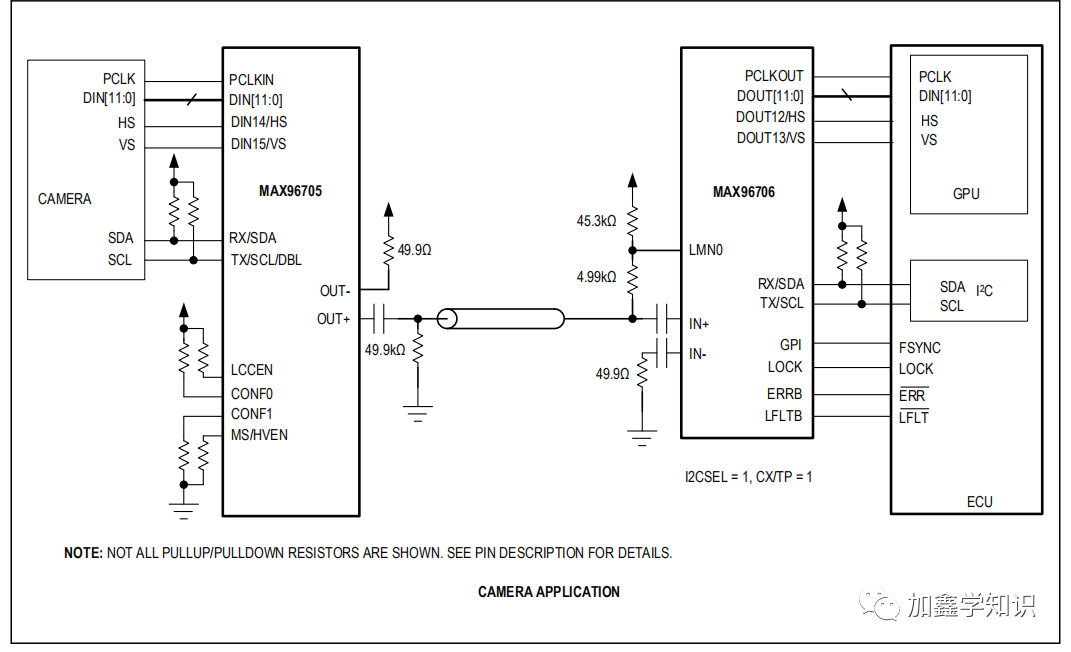
逻辑回归
Logistic回归一种二分类算法,它利用的是Sigmoid函数阈值在[0,1]这个特性。Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。其实,Logistic本质上是一个基于条件概率的判别模型(Discriminative Model)。
梯度上升算法
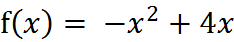
求函数的极值:
"""
函数说明:梯度上升算法测试函数求函数f(x) = -x^2 + 4x的极大值Parameters:无
Returns:无
"""
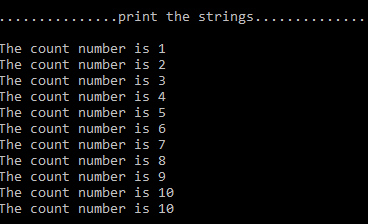
def Gradient_Ascent_test():def f_prime(x_old): #f(x)的导数return -2 * x_old + 4x_old = -1 #初始值,给一个小于x_new的值x_new = 0 #梯度上升算法初始值,即从(0,0)开始alpha = 0.01 #步长,也就是学习速率,控制更新的幅度presision = 0.00000001 #精度,也就是更新阈值while abs(x_new - x_old) > presision:x_old = x_newx_new = x_old + alpha * f_prime(x_old) #上面提到的公式print(x_new) #打印最终求解的极值近似值if __name__ == '__main__':Gradient_Ascent_test()
运行结果:
1.999999515279857
通过运行结果可以了解到,同过python所求出来的解十分的接近2了。
案例
数据集下载:https://github.com/Jack-Cherish/Machine-Learning/blob/master/Logistic/testSet.txt
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
0.667394 12.741452 0
-2.460150 6.866805 1
0.569411 9.548755 0
-0.026632 10.427743 0
这个数据有两维特征,因此可以将数据在一个二维平面上展示出来。我们可以将第一列数据(X1)看作x轴上的值,第二列数据(X2)看作y轴上的值。而最后一列数据即为分类标签。根据标签的不同,对这些点进行分类。
import matplotlib.pyplot as plt
import numpy as np"""
函数说明:加载数据Parameters:无
Returns:dataMat - 数据列表labelMat - 标签列表
"""
def loadDataSet():dataMat = [] #创建数据列表labelMat = [] #创建标签列表fr = open('testSet.txt') #打开文件 for line in fr.readlines(): #逐行读取lineArr = line.strip().split() #去回车,放入列表dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #添加数据labelMat.append(int(lineArr[2])) #添加标签fr.close() #关闭文件return dataMat, labelMat #返回"""
函数说明:绘制数据集Parameters:无
Returns:无
"""
def plotDataSet():dataMat, labelMat = loadDataSet() #加载数据集dataArr = np.array(dataMat) #转换成numpy的array数组n = np.shape(dataMat)[0] #数据个数xcord1 = []; ycord1 = [] #正样本xcord2 = []; ycord2 = [] #负样本for i in range(n): #根据数据集标签进行分类if int(labelMat[i]) == 1:xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2]) #1为正样本else:xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2]) #0为负样本fig = plt.figure()ax = fig.add_subplot(111) #添加subplotax.scatter(xcord1, ycord1, s = 20, c = 'red', marker = 's',alpha=.5)#绘制正样本ax.scatter(xcord2, ycord2, s = 20, c = 'green',alpha=.5) #绘制负样本plt.title('DataSet') #绘制titleplt.xlabel('x'); plt.ylabel('y') #绘制labelplt.show() #显示if __name__ == '__main__':plotDataSet()
运行结果:

从上图可以看出数据的分布情况。假设Sigmoid函数的输入记为z,那么z=w0x0 + w1x1 + w2x2,即可将数据分割开。其中,x0为全是1的向量,x1为数据集的第一列数据,x2为数据集的第二列数据。另z=0,则0=w0 + w1x1 + w2x2。横坐标为x1,纵坐标为x2。这个方程未知的参数为w0,w1,w2,也就是我们需要求的回归系数(最优参数)。
import numpy as np"""
函数说明:加载数据Parameters:无
Returns:dataMat - 数据列表labelMat - 标签列表
"""
def loadDataSet():dataMat = [] #创建数据列表labelMat = [] #创建标签列表fr = open('testSet.txt') #打开文件 for line in fr.readlines(): #逐行读取lineArr = line.strip().split() #去回车,放入列表dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #添加数据labelMat.append(int(lineArr[2])) #添加标签fr.close() #关闭文件return dataMat, labelMat #返回"""
函数说明:sigmoid函数Parameters:inX - 数据
Returns:sigmoid函数
"""
def sigmoid(inX):return 1.0 / (1 + np.exp(-inX))"""
函数说明:梯度上升算法Parameters:dataMatIn - 数据集classLabels - 数据标签
Returns:weights.getA() - 求得的权重数组(最优参数)
"""
def gradAscent(dataMatIn, classLabels):dataMatrix = np.mat(dataMatIn) #转换成numpy的matlabelMat = np.mat(classLabels).transpose() #转换成numpy的mat,并进行转置m, n = np.shape(dataMatrix) #返回dataMatrix的大小。m为行数,n为列数。alpha = 0.001 #移动步长,也就是学习速率,控制更新的幅度。maxCycles = 500 #最大迭代次数weights = np.ones((n,1))for k in range(maxCycles):h = sigmoid(dataMatrix * weights) #梯度上升矢量化公式error = labelMat - hweights = weights + alpha * dataMatrix.transpose() * errorreturn weights.getA() #将矩阵转换为数组,返回权重数组if __name__ == '__main__':dataMat, labelMat = loadDataSet() print(gradAscent(dataMat, labelMat))
运行结果:
[[ 4.12414349][ 0.48007329][-0.6168482 ]]
求解出回归系数[w0,w1,w2]