哈希表
哈希表顾名思义是一张表,可以用它来存储键值对这种对应的数据,大家都知道,哈希表的查找速度很快,时间复杂度伪O(1),那么它的查找速度为什么很快呢?
实际上,哈希表将键值变为数组的下标,而将下标对应的值变为键值对的值,这样的话就可以通过下标的方式来获取对应的值,因此其查找速度非常快。
那么key值是如何变为哈希表的下标的呢?这里就要用到散列函数,通过散列函数将key值变为数组的下标。
最常用的构造散列函数的方法是除留余数法。对于散列表长为m的散列函数公式为:
f(key) = key mod p(p≤m)
这种方法不仅可以对关键字直接取模,也可在折叠、平方取中后再取模。散列表长为m,通常p为小于或等于表长(最好接近m)的最小质数或不包含小于20质因子的合数。
举个例子,哈希函数是
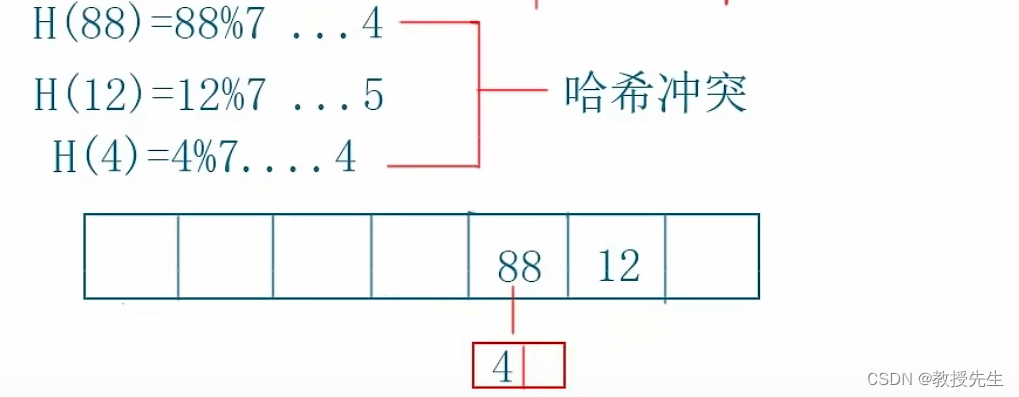
H(k)=k Mod m。m=12,k=100,H(100)=4。
而如果m=2k,那么无论k是什么,H(K)的值都是一个0和奇数,也即是说只要奇数槽和0槽被占用,其他的偶数槽都是浪费掉了。如果m=2^r,那么H(k)的值就是k的低r位(化成二进制)。这样造成的后果是某一个槽有很多的关键字。所以来说一般的m取值尽量不要接近2的整数幂,而且还要是质数。
由上面的散列函数可知,同一个key可以对应多个value,这就是哈希冲突 。当关键字值域远大于哈希表的长度,而且事先并不知道关键字的具体取值时,冲突就难免会发生。另外,当关键字的实际取值大于哈希表的长度时,而且表中已装满了记录,如果插入一个新记录,不仅发生冲突,而且还会发生溢出。因此,处理冲突和溢出是哈希技术中的两个重要问题。一般有开放地址法、链地址法。
链地址法:将所有关键字为同义词的记录存储在一个单链表中,这种链表叫做同义词子表,使用除留余数法,就不存在冲突的问题了,只是在链表中增加一个结点。
红黑树
二叉排序树
二叉排序树,又称二叉查找树、二叉搜索树
二叉排序树是具有下列性质的二叉树:
- 若左子树不空,则左子树上所有结点的值均小于它的根结点的值
- 若右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值
- 左、右子树也分别为二叉排序树
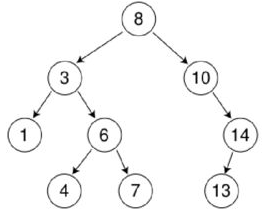
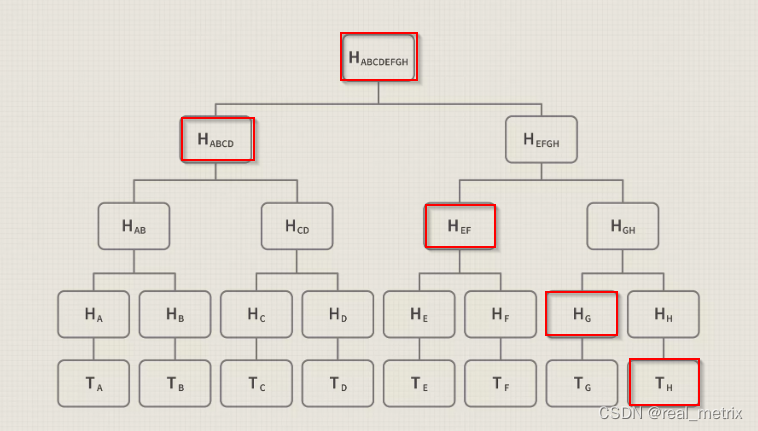
根据二叉排序树这个特点我们可以知道,二叉排序树的中序遍历一定是从小到大的,比如上图,中序遍历结果是:
1 3 4 6 7 8 10 13 14
二叉排序树的性能取决于二叉树的层数:
- 最好的情况是 O(logn),存在于完全二叉排序树情况下,其访问性能近似于折半查找
- 最差时候会是 O(n),比如插入的元素是有序的,生成的二叉排序树就是一个链表,这种情况下,需要遍历全部元素才行(见下图 b)

为了改变二叉排序树的不足,出现了二叉平衡树,其实红黑树也是一种二叉平衡树,只是没有二叉平衡树那么平衡。
二叉平衡树
二叉平衡数(AVL)只是在二叉搜索数的基础上又加了一条定义:
- 每个节点左子树的高度与右子树高度之差的绝对值不超过1

5号节点的左子树高度为3,右子树高度为1,两边高度之差绝对值为2,违反了规则,不是平衡二叉树。
平衡二叉树其实就是高度相对平衡的有两个子节点的有序树。
红黑树
红黑树本质上是一种二叉查找树,但它在二叉查找树的基础上额外添加了一个标记(颜色),同时具有一定的规则。这些规则使红黑树保证了一种平衡,插入、删除、查找的最坏时间复杂度都为 O(logn)。
它的统计性能要好于平衡二叉树(AVL树),因此,红黑树在很多地方都有应用。比如在 STL中的Map的key和Set。

红黑树规则如下:
- 每个节点要么是红色,要么是黑色;
- 根节点永远是黑色的;
- 所有的叶节点都是是黑色的(注意这里说叶子节点其实是上图中的 NIL 节点);
- 每个红色节点的两个子节点一定都是黑色;
- 从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点;
平衡二叉树和红黑树的区别:
1、平衡二叉树的左右子树的高度差绝对值不超过1,但是红黑树在某些时刻可能会超过1,只要符合红黑树的五个条件即可。
2、二叉树只要不平衡就会进行旋转,而红黑树不符合规则时,有些情况只用改变颜色不用旋转,就能达到平衡。
Hash与红黑树的区别:
权衡三个因素: 查找速度, 数据量, 内存使用,可扩展性,有序性。
hash查找速度会比RB树快,而且查找速度基本和数据量大小无关,属于常数级别;而RB树的查找速度是log(n)级别。并不一定常数就比log(n) 小,因为hash还有hash函数的耗时。当元素达到一定数量级时,考虑hash。但若你对内存使用特别严格, 希望程序尽可能少消耗内存,那么hash可能会让你陷入尴尬,特别是当你的hash对象特别多时,你就更无法控制了,而且 hash的构造速度较慢。
- 红黑树是有序的,Hash是无序的,根据需求来选择。
- 红黑树占用的内存更小(仅需要为其存在的节点分配内存),而Hash事先应该分配足够的内存存储散列表,即使有些槽可能弃用
- 红黑树查找和删除的时间复杂度都是O(logn),Hash查找和删除的时间复杂度都是O(1)。