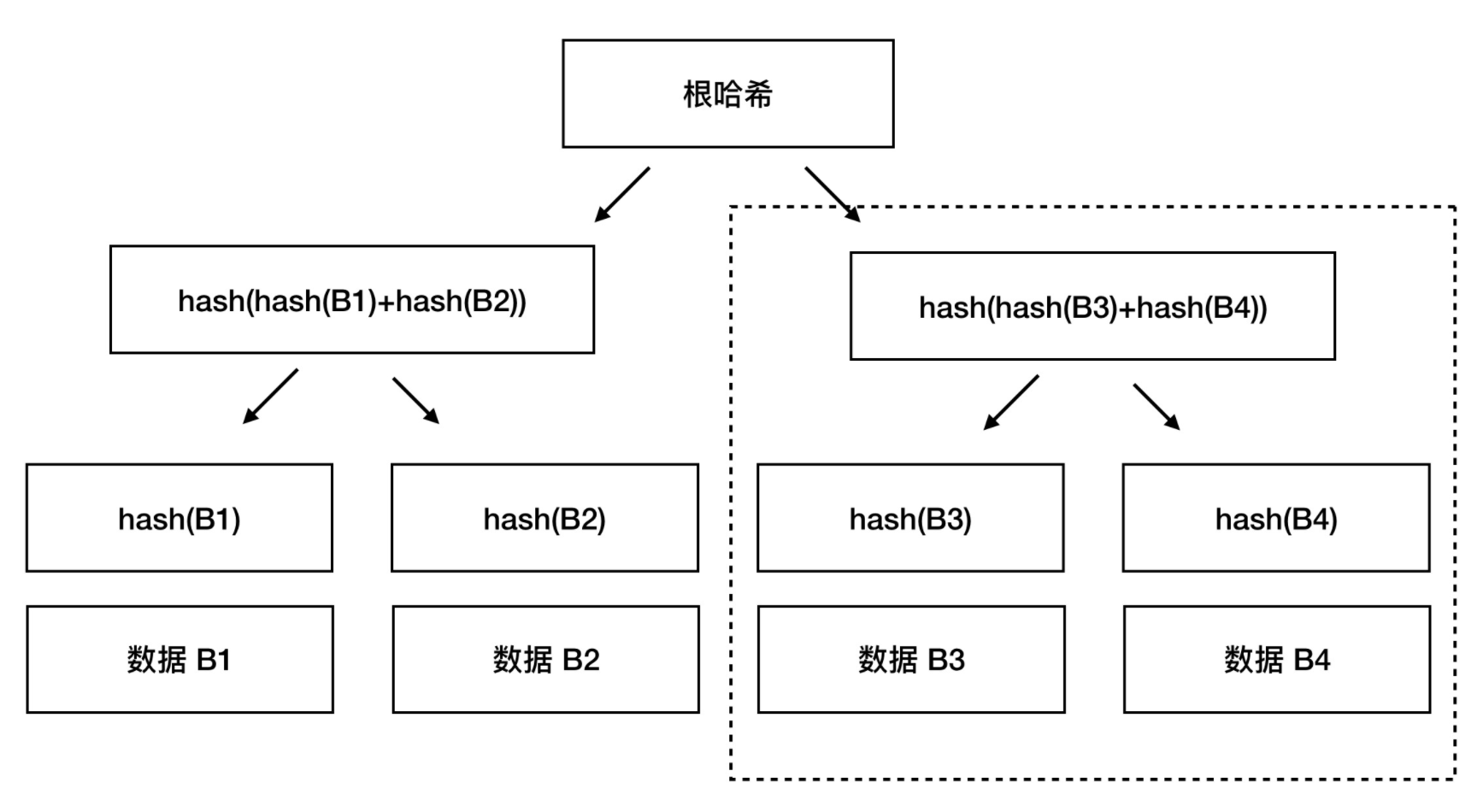
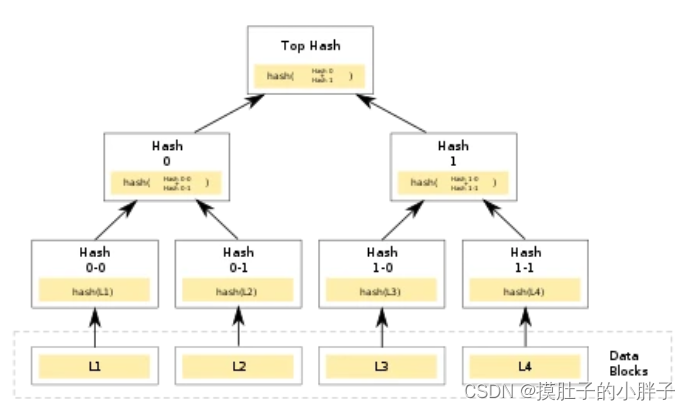
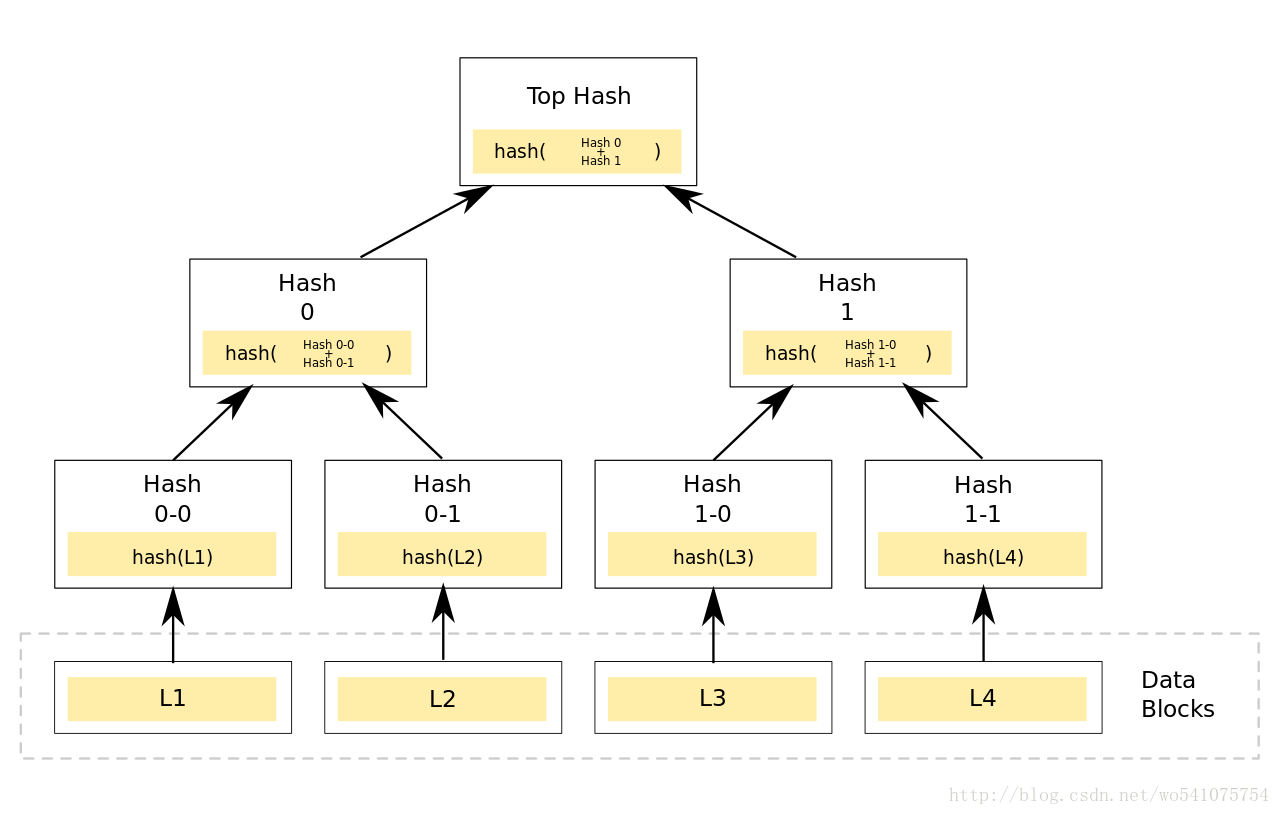
哈希函数:
简单来说就是把红框内的数字根据 一定规律 存放到下方白色的数组中 (称为哈希表)
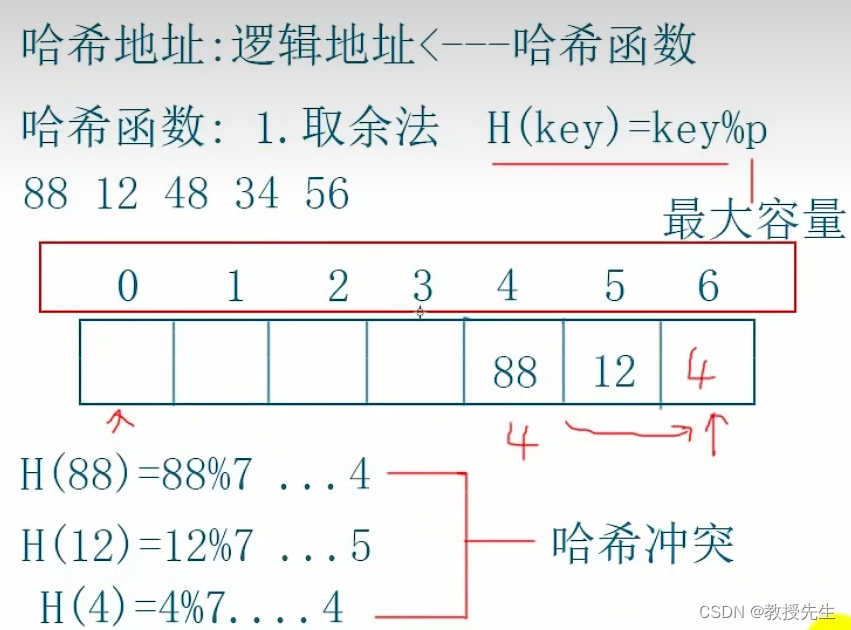
这里它的一定规律是 取余法 H(key)=key%p (还有其他方法,这里采用的是取余法),p为这个数组的最大容量,这里一共有7个数字,p就是7.取他们的余数依次按照从小到大的顺序依次排列到下方空数组(称为哈希表)中,
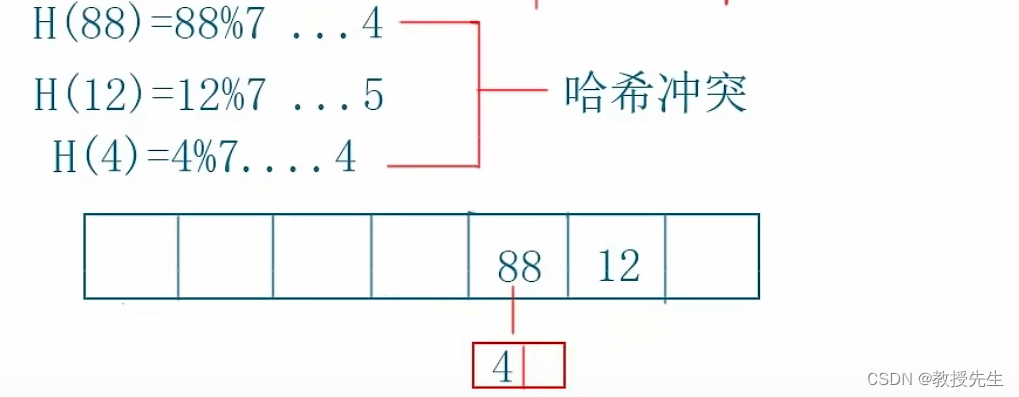
(哈希冲突:具体来说就是88%7==4和4%7==4,他们的余数都是4,按原本要求都是存放在第五个格子的位置,因为有两个相同的,他们就发送冲突了),因此这里我们采用的是开放地址法,就是开放后面地址的位置给存储空间
就是按照顺序依次往后顺延一个位置,若顺延后的位置仍然被占用,继续顺延,当顺延到最后一个格子时再顺延就重新回到第一个格子。(当所以格子都被数占满时候这个哈希表就满了)这个算法采用求余实现。
数学上可以称从实际值 到 哈希表上的键值之间的关系称为 映射
哈希表就是一种以键值对存储数据的结构
如果没有内存限制,那么可以直接将键作为数组的索引。那么所查找的时间复杂度为O(1);如果没有时间限制,那么我们可以使用无序数组并进行顺序查找,这样只需要很少的内存。
#include<stdio.h>
#include<stdlib.h>
#include<assert.h> //assert宏的原型定义在<assert.h>中,其作用是先计算表达式 expression ,如果expression的值为假(即为0),//那么它先向stderr打印一条出错信息,然后通过调用abort 来终止程序运行,若为真,则顺利执行。
#include<string.h>
typedef struct pair
{int key; //构造一个键出来 充当哈希地址的求解//这个一个自定义的结构体类型,同时存储key值,和char字符类型的信息 // 数据类型 char element[20];}DATA, * LPDATA; //* LPDATA 是这个自定义结构体的一级指针,DATA是这个结构体类型的别称
typedef struct hashTable //这个是一个哈希表
{ LPDATA* table;//二级指针,便于初始化,以及判断当前hash地址是否存在冲突 int divisor; //H(key)=key%p --->就是限定hash地址数目 int curSize;//定义的divisor为除数,cursize为curent size 的缩写,当前空间哈希表存储的个数 //限定数目[0,p-1]
}HASH, * LPHASH;//* LPHASH 是这个自定义结构体的一级指针,HASH是这个结构体类型的别称 LPHASH createHashTable(int p)//在定义的createHashTable函数使用前把哈希表里全部键值指向空NULL)
{LPHASH hash = (LPHASH)malloc(sizeof(HASH));//为结构体指针申请内存空间 assert(hash);//这个函数的头文件是 #include<assert.h> ,作用是检测hash这个是否申请成功 hash->curSize = 0;//初始化哈希表默认存储个数为0 hash->divisor = p;//传参赋值给除数 hash->table = (LPDATA*)malloc(sizeof(LPDATA) * hash->divisor);//为二级指针申请内存空间,//就是为哈希表申请分配内存 for (int i = 0;i < hash->divisor;i++){hash->table[i] = NULL;//将哈希表中的二级指针值指向为空,默认初始化 }return hash; //构建好这个函数后,返回这个函数类型
}
//找存储当前元素的地址
int search(LPHASH hash, int key)//这个是一个搜索函数,作用是查找当前key(需要查找的元素)值所对应的地址(键值)
{int pos = key % hash->divisor;//先计算hash的键值, 不存在冲突的hash //开放地址法 int curPos = pos;//将hash键值复制一份赋给curPos do{//key相同,采用覆盖的数据方式 if (hash->table[curPos] == NULL || hash->table[curPos]->key == key)return curPos;//若在哈希表中当前键值所指向元素为空,或者元素相同,则这个函数返回该键值,表示可以插入 curPos = (curPos + 1) % hash->divisor;//若上述条件不满足,顺延到下一位,当在最后以为顺延时回到第一位 } while ((curPos != pos));//上述条件若不满足,curPos就+1了, (curPos != pos)就返回1,//继续执行上述条件,判断顺延后的是否满足条件 return curPos;//若上述的do{} while(),当 (curPos != pos),curPos和pos相等时,已经把哈希表顺延遍历完成一次了//这时候就退出上面的 do{} while(),此时 curPos是通过( curPos = (curPos + 1) % hash->divisor)回到开始未顺延时的前一位, //这时候放回当前的地址,恰好完成全部哈希表的遍历
}
void insertData(LPHASH hash, DATA data)//传递参数,将哈希表的地址和需要插入的数据传入该函数
{//求hash地址int pos = search(hash, data.key);//通过上述search函数返回键值(哈希表中的位置) if (hash->table[pos] == NULL)//如果要插入哈希表的键值(位置)指向为空,则满足条件,允许插入 {hash->table[pos] = (LPDATA)malloc(sizeof(DATA));//重新为哈希表上的二级指针申请内存空间 memcpy(hash->table[pos], &data, sizeof(DATA));//再将要复制的数据信息赋给当前哈希表上(地址)键值对应的空间 hash->curSize++;//存储完毕,则 当前空间哈希表存储的个数 +1 }else//若不为空,则哈希表上键值对应空间已被占用,前面已经讲过,若对应键值相同,元素不同,则顺延存储。以下只有2种情况//1.键值(地址)相同对应的元素相同,则覆盖。//2.哈希表已经顺延过一次并且已经满了,打印 "hash表满了,无法插入!{if (hash->table[pos]->key == data.key){strcpy(hash->table[pos]->element, data.element);}else{printf("hash表满了,无法插入!\n");return;}}
}
void printHash(LPHASH hash)//哈希表打印函数,打印具体的哈希键值对应的数据,若为空,则打印为NULL
{for (int i = 0;i < hash->divisor;i++){if (hash->table[i] == NULL){printf("NULL\n");}else{printf("%d:%s\n", hash->table[i]->key, hash->table[i]->element);}}
}int main()
{ //创建哈希表内存大小 LPHASH hash = createHashTable(10);DATA array[5] = { 1,"雷电",11,"春秒",23,"四月",44,"baby",56,"virtual" };//赋值传参 for (int i = 0;i < 5;i++){insertData(hash, array[i]);//调用插入函数,for循环5次插入 }printHash(hash);//调用打印函数,输出结果,判断 printf("根据结果观察,可知 1和11都应该存储到 第二个位置上(1%%10==1,11%%10==1)\n"); printf("但11的信息排到了第三位,因为他顺延了"); return 0;
}//本代码翻译于b站up主 C语言编程__Plus的源代码,博客作者在深度研究视频基础上手敲代码,并翻译
//如有版权侵犯请联系作者,还请多多包涵,创作目是学习交流,欢迎更多读者共同交流,同时附上b站up主视频链接
// https://www.bilibili.com/video/BV1aB4y1m7av?p=1&vd_source=cd01b7a7d56751172d6e57f07196d3ec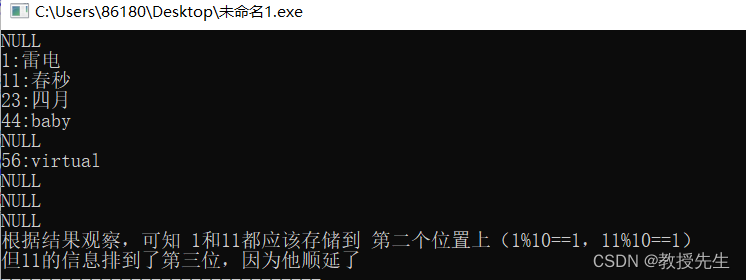 为什么哈希算法存取比较快呢?
为什么哈希算法存取比较快呢?
important: 哈希算法会根据你要存入的数据,先通过该算法,计算出一个地址值,这个地址值就是你需要存入到集合当中的数据的位置,而不会像数组那样一个个的进行挨个存储,挨个遍历一遍后面有空位就存这种情况了,而你查找的时候,也是根据这个哈希算法来的,将你的要查找的数据进行计算,得出一个地址,这个地址会印射到集合当中的位置,这样就能够直接到这个位置上去找了,而不需要像数组那样,一个个遍历,一个个对比去寻找,这样自然增加了速度,提高了效率了.
(2)构造方法
①、直接定址法
②、数字分析法
③、平方取中法
④、折叠法
⑤、除留余数法
⑥、随机数法
本节描述的哈希的构造方法是除留余数法,此外还有其他方法,请自己自行探索。
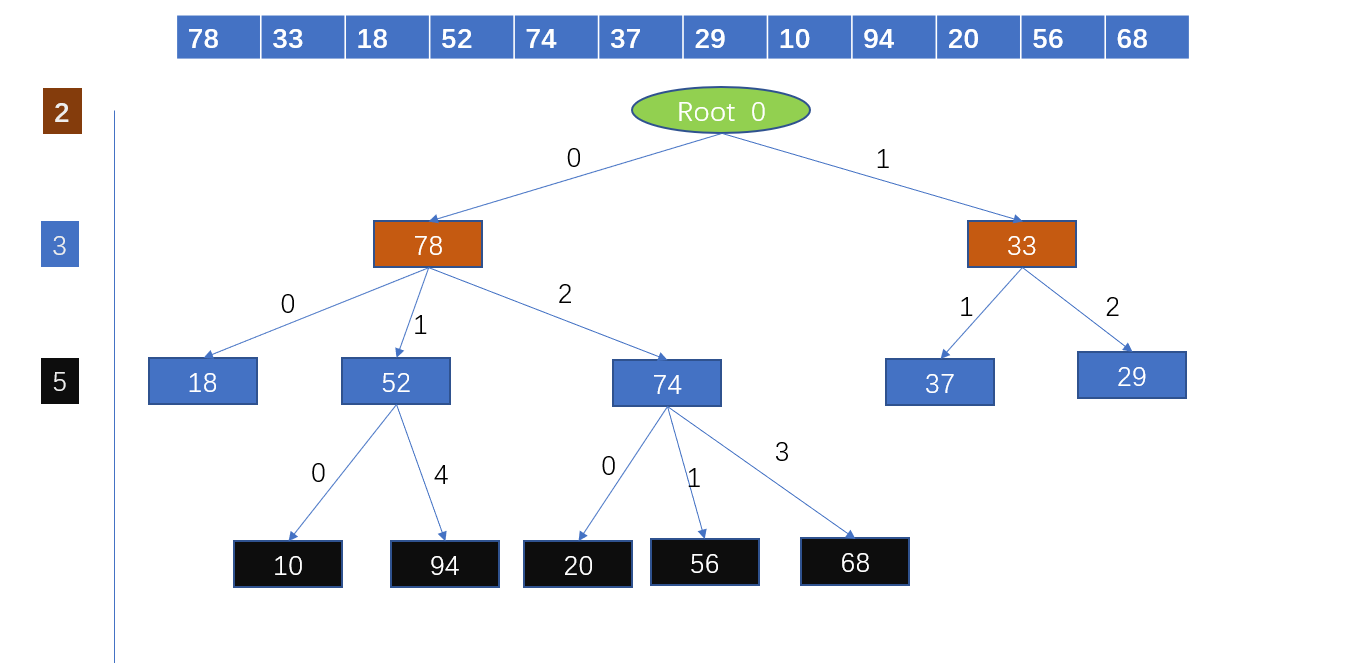
在解决哈希冲突的过程中 ,上述我们讲述的是开放地址法,另外还有邻接表法,如下图,就是在发生冲突的哈希表上再连接一个链表(数组),将发送冲突的key值存储到这个内存空间当中去
//本代码翻译于b站up主 C语言编程__Plus的源代码,博客作者在深度研究视频基础上手敲代码,并翻译
//如有版权侵犯请联系作者,还请多多包涵,创作目是学习交流,欢迎更多读者共同交流,同时附上b站up主视频链接
// https://www.bilibili.com/video/BV1aB4y1m7av?p=1&vd_source=cd01b7a7d56751172d6e57f07196d3ec