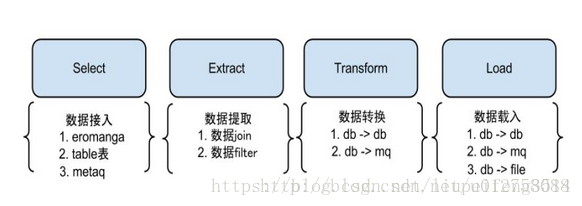
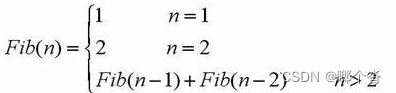一.概述
Otter 阿里巴巴分布式数据库同步系统:https://github.com/alibaba/otter
Otter底层依赖Canal接收和解析mysql binlog日志,提供了可配置化的同步机制,纯java开发,免费开源的,基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库,是一个分布式数据同步系统。
典型的应用场景:
- 1.异构库同步
- a. mysql -> mysql/oracle. (目前开源版只支持mysql增量,目标库可以是mysql或oracle,取决于canal的功能)
- 2.单机房同步 (数据库之间RTT < 1ms, RTT: 往返延迟)
- a.数据库版本升级
- b. 数据表迁移
- c. 异步二级索引
- 3.异地机房同步 (比如阿里巴巴国际站就是杭州和美国机房的数据库同步,RTT > 200ms)
- a. 机房容灾
- 4.双向同步
- a. 避免回环算法 (通用的解决方案,支持大部分关系型数据库)
- b. 数据一致性算法 (保证双A机房模式下,数据保证最终一致性)
- 5.文件同步
- a. 站点镜像 (进行数据复制的同时,复制关联的图片,比如复制产品数据,同时复制产品图片).
二.架构
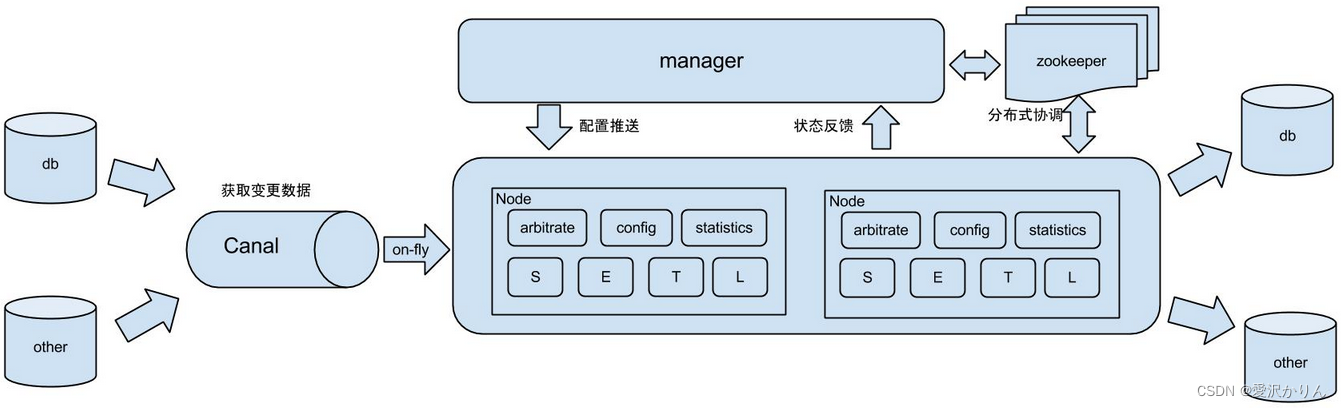
说明:
- db : 数据源以及需要同步到的库
- Canal : 获取数据库增量日志,canal支持独立部署和内嵌使用两种模式。otter使用canal的内嵌方法获取数据库增量日志
- manager : 配置同步规则设置数据源同步源等
- zookeeper : 协调node进行协调工作
- node : 负责任务处理,即根据任务配置对数据源进行解析并同步到目标数据库的操作。
原理描述:
基于Canal的开源产品,获取数据库增量日志数据。典型管理系统架构:manager(web管理)+node(工作节点)
1.manager运行时推送同步配置到node节点
2.node节点将同步状态反馈到manager上
3.基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作
单机房复制示意图:
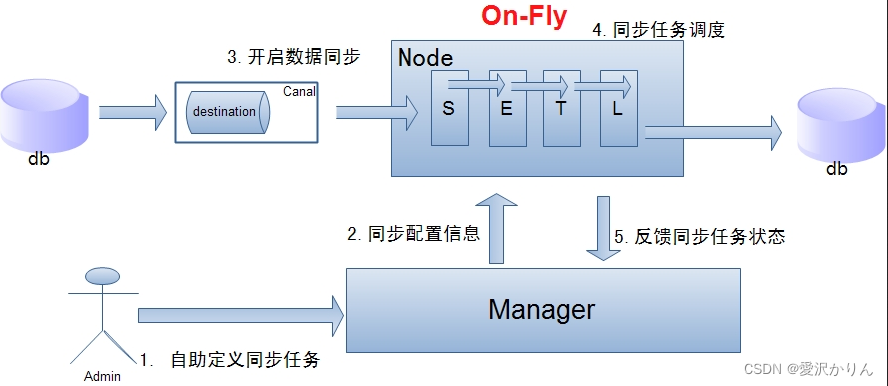
说明:
- 数据on-Fly,尽可能不落地,更快的进行数据同步.
- node节点可以有failover / loadBalancer.
三.前置准备
jdk、docker省略

可以看到我把’th服务器’克隆了两份,ip分配是
th服务器:192.168.136.160
th克隆1:192.168.136.161
th克隆2:192.168.136.162
四.Otter安装配置
一.MySQL安装
4.1.1创建源数据库
在th克隆1服务器创建数据库作为otter源数据库
cd /mnt
#创建目录,用于存放MySQL源库所需配置文件和数据,后续启动MySQL容器时需要进行目录映射
mkdir mysql_src
cd mysql_src
#conf目录用于存放MySQL数据库配置文件,data用于存放数据
mkdir conf data
cd conf
#创建MySQL数据库配置文件
vim docker.cnf
#文件内容
[mysqld]
server_id=1
character-set-server=utf8
collation-server=utf8_general_ci
binlog_format=row
log-bin=mysql-bin
sql_mode='ONLY_FULL_GROUP_BY,NO_AUTO_VALUE_ON_ZERO,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
#启动MySQL容器
docker run -id --name otter_mysql1 \
-v /mnt/mysql_src/data:/var/lib/mysql \
-v /mnt/mysql_src/conf:/etc/mysql/conf.d \
-p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
4.1.2创建目标数据库
在th克隆2服务器创建数据库作为otter目标数据库
cd /mnt
#创建目录,用于存放MySQL目标库所需配置文件和数据,后续启动MySQL容器时需要进行目录映射
mkdir mysql_dest
cd mysql_dest
#conf目录用于存放MySQL数据库配置文件,data用于存放数据
mkdir conf data
cd conf
#创建MySQL数据库配置文件
vim docker.cnf
#文件内容
[mysqld]
server_id=2
character-set-server=utf8
collation-server=utf8_general_ci
binlog_format=row
log-bin=mysql-bin
sql_mode='ONLY_FULL_GROUP_BY,NO_AUTO_VALUE_ON_ZERO,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
#启动MySQL容器
docker run -id --name otter_mysql2 \
-v /mnt/mysql_dest/data:/var/lib/mysql \
-v /mnt/mysql_dest/conf:/etc/mysql/conf.d \
-p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
mysql源数据库的binlog必须配置成row,才能够进行数据同步:
-- 必须开启log-bin二进制日志
show variables like 'log_bin';
-- binlong 格式必须是row,以下命令查看当前数据库binlog方式:
show variables like 'binlog_format';
-- 必须有server_id,该参数跟数据库复制有关,详情看官网
show variables like 'server_id';
-- 字符集character_set_server 必须是utf8,否则配置数据源表验证不通过。
show variables like 'character_set_server';
4.1.3初始化Otter配置数据库
在th服务器上创建数据库
cd /mnt
#创建目录,用于存放MySQL目标库所需配置文件和数据,后续启动MySQL容器时需要进行目录映射
mkdir mysql_otter
cd mysql_otter
#conf目录用于存放MySQL数据库配置文件,data用于存放数据
mkdir conf data
cd conf
#创建MySQL数据库配置文件
vim docker.cnf
#文件内容
[mysqld]
server_id=3
character-set-server=utf8
collation-server=utf8_general_ci
binlog_format=row
log-bin=mysql-bin
sql_mode='ONLY_FULL_GROUP_BY,NO_AUTO_VALUE_ON_ZERO,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
#启动MySQL容器
docker run -id --name otter_mysql \
-v /mnt/mysql_otter/data:/var/lib/mysql \
-v /mnt/mysql_otter/conf:/etc/mysql/conf.d \
-p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
在准备安装Otter的服务器的MySQL中执行以下SQL,创建名称为otter的数据库
create database otter DEFAULT CHARACTER SET utf8;
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
GRANT ALL PRIVILEGES ON `otter`.* TO 'canal'@'%';
flush PRIVILEGES;
在otter数据库中创建表
https://github.com/alibaba/otter/blob/master/manager/deployer/src/main/resources/sql/otter-manager-schema.sql
二. zookeeper安装
在th服务器,安装一个单机的就行
#启动容器:
docker run -id --name my_zookeeper -p 2181:2181 zookeeper:3.4.14
#查看容器运行情况:
docker logs -f my_zookeeper
使用客户端连接zookeeper:
docker run -it --rm --link my_zookeeper:zk zookeeper:3.4.14 zkCli.sh -server zk
三.aria2安装
在th服务器安装,aria2是一个多线程下载工具,运行otter需要aria2的支持
yum -y install epel-release aria2
四.Otter manager
在th服务器安装
https://github.com/alibaba/otter/releases
mkdir /opt/otter
cd /opt/otter
# 将文件下载到/opt/otter目录
wget https://github.com/alibaba/otter/releases/download/otter-4.2.18/manager.deployer-4.2.18.tar.gz
wget https://github.com/alibaba/otter/releases/download/otter-4.2.18/node.deployer-4.2.18.tar.gz
# 解压manager
mkdir manager
tar -zxf manager.deployer-4.2.18.tar.gz -C manager
我建议先开代理下好后再上传到服务器中
修改otter manager配置文件:

启动otter manager:
/opt/otter/manager/bin/startup.sh
查看日志:
tail -500f /opt/otter/manager/logs/manager.log
用浏览器打开: http://{otter主机ip}:8080/
默认密码:admin/admin

五.Manager配置
4.5.1配置zookeeper

我布置的是单机的
4.5.1配置node


- 机器名称:可以随意定义,方便记忆即可
- 机器ip:对应node节点将要部署的机器ip,如果有多ip时,可选择其中一个ip进行暴露. (此ip是整个集群通讯的入口,实际情况千万别使用127.0.0.1,否则多个机器的node节点会无法识别)
- 机器端口:对应node节点将要部署时启动的数据通讯端口
- 下载端口:对应node节点将要部署时启动的数据下载端口
- 外部ip :对应node节点将要部署的机器ip,存在的一个外部ip,允许通讯的时候走公网处理
- zookeeper集群:为提升通讯效率,不同机房的机器可选择就近的zookeeper集群
- node这种设计,是为解决单机部署多实例而设计的,允许单机多node指定不同的端口
端口默认即可,添加完node后,列表中第一列是nid(此id要保存到node/conf/nid文件中的值):

六.Otter node
# 解压到node目录中
cd /opt/otter/
mkdir node
tar -zxf node.deployer-4.2.18.tar.gz -C node/
# 添加nid(在manager中添加的node节点的nid)
cd /opt/otter/node/conf/
echo 1 > nid
启动node:
/opt/otter/node/bin/startup.sh
六.设置同步任务
6.1数据库创建
在源数据库和目标数据库中都需要创建数据库otter_test,并执行以下建表语句:
DROP TABLE IF EXISTS `tb_item`;
CREATE TABLE `tb_item` (`id` bigint(20) NOT NULL COMMENT '商品id,同时也是商品编号',`title` varchar(100) NOT NULL COMMENT '商品标题',`sell_point` varchar(500) DEFAULT NULL COMMENT '商品卖点',`price` bigint(20) NOT NULL COMMENT '商品价格,单位为:分',`image` varchar(500) DEFAULT NULL COMMENT '商品图片',`status` tinyint(4) NOT NULL DEFAULT '1' COMMENT '商品状态,1-正常,2-下架,3-删除',`created` datetime NOT NULL COMMENT '创建时间',`updated` datetime NOT NULL COMMENT '更新时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='商品表';

6.2数据源配置

配置源数据库:

配置目标数据库:


6.3数据表配置

添加源数据库表

添加目标数据库表

6.4添加canal


源数据库

6.5添加channel


行记录模式:如果目标库中不存在记录时,执行插入。
列记录模式:变更哪个字段就同步哪个字段,在双A同步时,为减少数据冲突,建议使用此选项。(双A只的是双主、且会同时修改同一条记录)
6.6添加pipeline
点击这个channel名称


pipeline参数
- 1.并行度. ==> 查看文档:Otter调度模型,主要是并行化调度参数.(滑动窗口大小)
- 2.数据反查线程数. ==> 如果选择了同步一致性为反查数据库,在反查数据库时的并发线程数大小
- 3.数据载入线程数. ==> 在目标库执行并行载入算法时并发线程数大小
- 4.文件载入线程数. ==> 数据带文件同步时处理的并发线程数大小
- 5.主站点. ==> 双A同步中的主站点设置
- 6.消费批次大小. ==> 获取canal数据的batchSize参数
- 7.获取批次超时时间. ==> 获取canal数据的timeout参数
pipeline 高级设置
- 1.使用batch. ==> 是否使用jdbc batch提升效率,部分分布式数据库系统不一定支持batch协议
- 2.跳过load异常. ==> 比如同步时出现目标库主键冲突,开启该参数后,可跳过数据库执行异常
- 3.仲裁器调度模式. ==> 查看文档:Otter调度模型
- 4.负载均衡算法. ==> 查看文档:Otter调度模型
- 5.传输模式. ==> 多个node节点之间的传输方式,RPC或HTTP. HTTP主要就是使用aria2c,如果测试环境不装aria2c,可强制选择为RPC
- 6.记录selector日志. ==> 是否记录简单的canal抓取binlog的情况
- 7.记录selector详细日志. ==> 是否记录canal抓取binlog的数据详细内容
- 8.记录load日志. ==> 是否记录otter同步数据详细内容
- 9.dryRun模式. ==> 只记录load日志,不执行真实同步到数据库的操作
- 10.支持ddl同步. ==> 是否同步ddl语句
- 11.是否跳过ddl异常. ==> 同步ddl出错时,是否自动跳过
- 12.文件重复同步对比 ==> 数据带文件同步时,是否需要对比源和目标库的文件信息,如果文件无变化,则不同步,减少网络传输量.
- 13.文件传输加密 ==> 基于HTTP协议传输时,对应文件数据是否需要做加密处理
- 14.启用公网同步 ==> 每个node节点都会定义一个外部ip信息,如果启用公网同步,同步时数据传递会依赖外部ip.
- 15.跳过自由门数据 ==> 自定义数据同步的内容
- 16.跳过反查无记录数据 ==> 反查记录不存在时,是否需要进行忽略处理,不建议开启.
- 17.启用数据表类型转化 ==> 源库和目标库的字段类型不匹配时,开启改功能,可自动进行字段类型转化
- 18.兼容字段新增同步 ==> 同步过程中,源库新增了一个字段(必须无默认值),而目标库还未增加,是否需要兼容处理
- 19.自定义同步标记 ==> 级联同步中屏蔽同步的功能.
6.7添加映射关系表


下一步

全部字段映射

完成

6.8测试
启用channel

源数据库中插入一条数据

查看目标数据库