一、前言
很早之前,我曾经写过一个古体诗生成器(详情可以戳TensorFlow练手项目二:基于循环神经网络(RNN)的古诗生成器),那个时候用的还是Python 2.7和TensorFlow 1.4。
随着框架的迭代,API 的变更,老项目已经很难无障碍运行起来了。有不少朋友在老项目下提出了各种问题,于是,我就萌生了使用TensorFlow 2.0重写项目的想法。
这不,终于抽空,重写了这个项目。
完整的项目已经放到了GitHub上:
AaronJny/DeepLearningExamples/tf2-rnn-poetry-generator (https://github.com/AaronJny/DeepLearningExamples/tree/master/tf2-rnn-poetry-generator)
先对项目做个简单展示。项目主要包含如下功能:
- 使用唐诗数据集训练模型。
- 使用训练好的模型,随机生成一首古体诗。
- 使用训练好的模型,续写一首古体诗。
- 使用训练好的模型,随机生成一首藏头诗。
随机生成一首古体诗:
金鹤有僧心,临天寄旧身。
石松惊枕树,红鸟发禅新。
不到风前远,何人怨夕时。
明期多尔处,闲此不依迟。
水泉临鸟声,北去暮空行。
林阁多开雪,楼庭起洞城。
夜来疏竹外,柳鸟暗苔清。
寂寂重阳里,悠悠一钓矶。
续写一首古体诗(以"床前明月光,"为例):
床前明月光,翠席覆银丝。
岁气分龙阁,无人入鸟稀。
圣明无泛物,云庙逐雕旗。
永夜重江望,南风正送君。
床前明月光,清水入寒云。
远景千山雨,萧花入翠微。
影云虚雪润,花影落云斜。
独去江飞夜,谁能作一花。
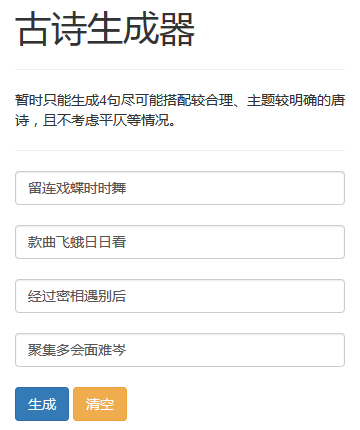
随机生成一首藏头诗(以"海阔天空"为例):
海口多无定,
阔庭何所难。
天山秋色上,
空石昼尘连。
海庭愁不定,
阔处到南关。
天阙青秋上,
空城雁渐催。
下面开始讲解项目实现过程。
转载请注明来源:https://blog.csdn.net/aaronjny/article/details/103806954
二、数据集处理
跟老项目一样,我们仍然使用四万首唐诗的文本作为训练集(已经上传,可以直接从GitHub上下载)。我们打开文本,看一下数据格式:
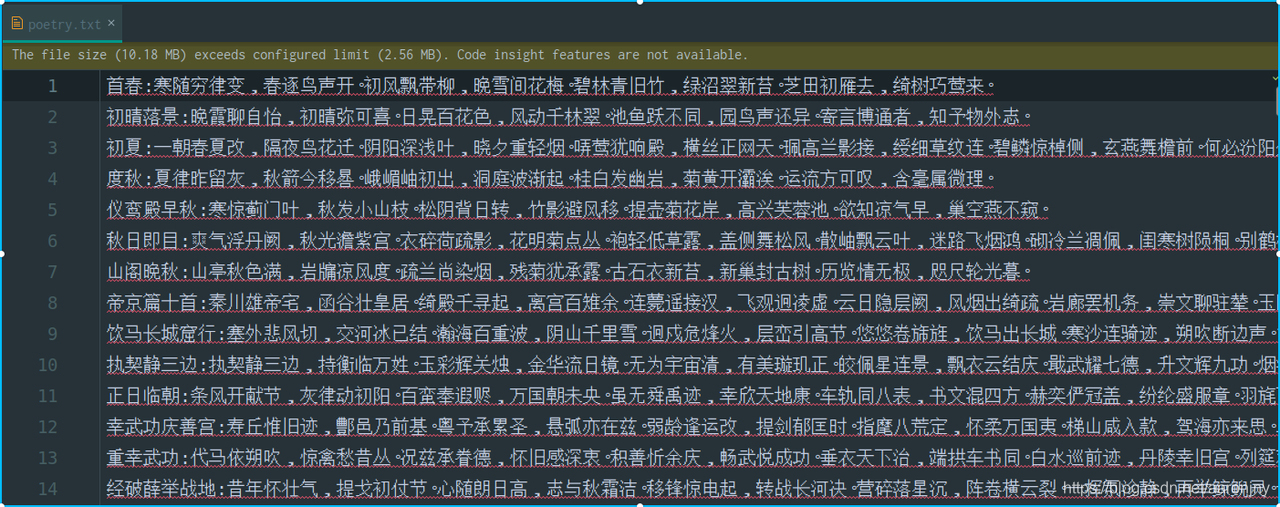
能够看到,文本中每行是一首诗,且使用冒号分割,前面是标题,后面是正文,且诗的长度不一。
我们对数据的处理流程大致如下:
- 读取文本,按行切分,构成古诗列表。
- 将全角、半角的冒号统一替换成半角的。
- 按冒号切分诗的标题和内容,只保留诗的内容。
- 考虑到模型的大小,我们只保留内容长度小于一定长度的古诗。
- 统计保留的诗中的词频,去掉低频词,构建词汇表。
代码如下:
# -*- coding: utf-8 -*-
# @File : dataset.py
# @Author : AaronJny
# @Time : 2019/12/30
# @Desc : 构建数据集
from collections import Counter
import math
import numpy as np
import tensorflow as tf
import settings# 禁用词
disallowed_words = settings.DISALLOWED_WORDS
# 句子最大长度
max_len = settings.MAX_LEN
# 最小词频
min_word_frequency = settings.MIN_WORD_FREQUENCY
# mini batch 大小
batch_size = settings.BATCH_SIZE# 加载数据集
with open(settings.DATASET_PATH, 'r', encoding='utf-8') as f:lines = f.readlines()# 将冒号统一成相同格式lines = [line.replace(':', ':') for line in lines]
# 数据集列表
poetry = []
# 逐行处理读取到的数据
for line in lines:# 有且只能有一个冒号用来分割标题if line.count(':') != 1:continue# 后半部分不能包含禁止词__, last_part = line.split(':')ignore_flag = Falsefor dis_word in disallowed_words:if dis_word in last_part:ignore_flag = Truebreakif ignore_flag:continue# 长度不能超过最大长度if len(last_part) > max_len - 2:continuepoetry.append(last_part.replace('\n', ''))# 统计词频
counter = Counter()
for line in poetry:counter.update(line)
# 过滤掉低频词
_tokens = [(token, count) for token, count in counter.items() if count >= min_word_frequency]
# 按词频排序
_tokens = sorted(_tokens, key=lambda x: -x[1])
# 去掉词频,只保留词列表
_tokens = [token for token, count in _tokens]# 将特殊词和数据集中的词拼接起来
_tokens = ['[PAD]', '[UNK]', '[CLS]', '[SEP]'] + _tokens
# 创建词典 token->id映射关系
token_id_dict = dict(zip(_tokens, range(len(_tokens))))
# 使用新词典重新建立分词器
tokenizer = Tokenizer(token_id_dict)
# 混洗数据
np.random.shuffle(poetry)
代码很简单,注释也很清晰,就不一行一行说了。有几点需要注意一下:
- 我们需要一些特殊字符,以完成特定的功能。这里使用的特殊字符有四个,为’[PAD]’, ‘[UNK]’, ‘[CLS]’, ‘[SEP]’,它们分别代表填充字符、低频词、古诗开始标记、古诗结束标记。
- 代码中出现了一个类——Tokenizer,这是为了方便我们完成字符转编号、编号转字符、字符串转编号序列、编号序列转字符串等操作而编写的一个辅助类。它的代码也很简单,我们来看一下。
class Tokenizer:"""分词器"""def __init__(self, token_dict):# 词->编号的映射self.token_dict = token_dict# 编号->词的映射self.token_dict_rev = {value: key for key, value in self.token_dict.items()}# 词汇表大小self.vocab_size = len(self.token_dict)def id_to_token(self, token_id):"""给定一个编号,查找词汇表中对应的词:param token_id: 带查找词的编号:return: 编号对应的词"""return self.token_dict_rev[token_id]def token_to_id(self, token):"""给定一个词,查找它在词汇表中的编号未找到则返回低频词[UNK]的编号:param token: 带查找编号的词:return: 词的编号"""return self.token_dict.get(token, self.token_dict['[UNK]'])def encode(self, tokens):"""给定一个字符串s,在头尾分别加上标记开始和结束的特殊字符,并将它转成对应的编号序列:param tokens: 待编码字符串:return: 编号序列"""# 加上开始标记token_ids = [self.token_to_id('[CLS]'), ]# 加入字符串编号序列for token in tokens:token_ids.append(self.token_to_id(token))# 加上结束标记token_ids.append(self.token_to_id('[SEP]'))return token_idsdef decode(self, token_ids):"""给定一个编号序列,将它解码成字符串:param token_ids: 待解码的编号序列:return: 解码出的字符串"""# 起止标记字符特殊处理spec_tokens = {'[CLS]', '[SEP]'}# 保存解码出的字符的listtokens = []for token_id in token_ids:token = self.id_to_token(token_id)if token in spec_tokens:continuetokens.append(token)# 拼接字符串return ''.join(tokens)我的注释都写得很细,阅读起来应该不存在问题。上面的代码中引用了一些配置项,这些配置项被我统一提取到了settings.py里,贴出来以供查阅:
# -*- coding: utf-8 -*-
# @File : settings.py
# @Author : AaronJny
# @Time : 2019/12/25
# @Desc :# 禁用词,包含如下字符的唐诗将被忽略
DISALLOWED_WORDS = ['(', ')', '(', ')', '__', '《', '》', '【', '】', '[', ']']
# 句子最大长度
MAX_LEN = 64
# 最小词频
MIN_WORD_FREQUENCY = 8
# 训练的batch size
BATCH_SIZE = 16
# 数据集路径
DATASET_PATH = './poetry.txt'
# 每个epoch训练完成后,随机生成SHOW_NUM首古诗作为展示
SHOW_NUM = 5
# 共训练多少个epoch
TRAIN_EPOCHS = 20
# 最佳权重保存路径
BEST_MODEL_PATH = './best_model.h5'好的,我们已经对数据进行了处理,并构建了分词器。为了方便训练,我们还需要再编写一个生成器,对数据集进行封装:
class PoetryDataGenerator:"""古诗数据集生成器"""def __init__(self, data, random=False):# 数据集self.data = data# batch sizeself.batch_size = batch_size# 每个epoch迭代的步数self.steps = int(math.floor(len(self.data) / self.batch_size))# 每个epoch开始时是否随机混洗self.random = randomdef sequence_padding(self, data, length=None, padding=None):"""将给定数据填充到相同长度:param data: 待填充数据:param length: 填充后的长度,不传递此参数则使用data中的最大长度:param padding: 用于填充的数据,不传递此参数则使用[PAD]的对应编号:return: 填充后的数据"""# 计算填充长度if length is None:length = max(map(len, data))# 计算填充数据if padding is None:padding = tokenizer.token_to_id('[PAD]')# 开始填充outputs = []for line in data:padding_length = length - len(line)# 不足就进行填充if padding_length > 0:outputs.append(np.concatenate([line, [padding] * padding_length]))# 超过就进行截断else:outputs.append(line[:length])return np.array(outputs)def __len__(self):return self.stepsdef __iter__(self):total = len(self.data)# 是否随机混洗if self.random:np.random.shuffle(self.data)# 迭代一个epoch,每次yield一个batchfor start in range(0, total, self.batch_size):end = min(start + self.batch_size, total)batch_data = []# 逐一对古诗进行编码for single_data in self.data[start:end]:batch_data.append(tokenizer.encode(single_data))# 填充为相同长度batch_data = self.sequence_padding(batch_data)# yield x,yyield batch_data[:, :-1], tf.one_hot(batch_data[:, 1:], tokenizer.vocab_size)del batch_datadef for_fit(self):"""创建一个生成器,用于训练"""# 死循环,当数据训练一个epoch之后,重新迭代数据while True:# 委托生成器yield from self.__iter__()
写成生成器的形式,主要出于内存方面的考虑。训练时需要对数据进行填充、转one-hot形式等操作,会占用较多内存。如果提前对全部数据都进行处理,内存可能会溢出。而以生成器的形式,可以只在要进行训练的时候,处理相应batch size的数据即可。
另外,注意这一句:
yield batch_data[:, :-1], tf.one_hot(batch_data[:, 1:], tokenizer.vocab_size)
前面部分是数据x,后面部分是标签y。将诗的内容错开一位分别作为数据和标签,举个例子,假设有诗是“[CLS]床前明月光,疑是地上霜。举头望明月,低头思故乡。[SEP]”,则数据为“[CLS]床前明月光,疑是地上霜。举头望明月,低头思故乡。”,标签为“床前明月光,疑是地上霜。举头望明月,低头思故乡。[SEP]”,两者一一对应,y是x中每个位置的下一个字符。
当然了,以字符的形式举例是为了方便理解,实际上不论是数据还是标签,都是使用tokenizer编码后的编号序列。
还有一点不同的是,标签部分使用了one-hot进行处理,而数据部分没有使用。原因在于,数据部分准备输入词嵌入层,而词嵌入层的输入不需要进行one-hot;而标签部分,需要和模型的输出计算交叉熵,输出层的激活函数是softmax,所以标签部分也要转成相应的shape,故使用one-hot形式。
三、构建模型
数据处理完成后,该着手构建模型了。因为不涉及自定义程度比较高的层,所以我选择使用TensorFlow 2.0的高级接口tf.keras构建模型。
使用tf.keras构建模型非常简单快捷,估计使用过Keras的朋友都深有体会:
# -*- coding: utf-8 -*-
# @File : model.py
# @Author : AaronJny
# @Time : 2020/01/01
# @Desc :
import tensorflow as tf
from dataset import tokenizer# 构建模型
model = tf.keras.Sequential([# 不定长度的输入tf.keras.layers.Input((None,)),# 词嵌入层tf.keras.layers.Embedding(input_dim=tokenizer.vocab_size, output_dim=128),# 第一个LSTM层,返回序列作为下一层的输入tf.keras.layers.LSTM(128, dropout=0.5, return_sequences=True),# 第二个LSTM层,返回序列作为下一层的输入tf.keras.layers.LSTM(128, dropout=0.5, return_sequences=True),# 对每一个时间点的输出都做softmax,预测下一个词的概率tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(tokenizer.vocab_size, activation='softmax')),
])# 查看模型结构
model.summary()
# 配置优化器和损失函数
model.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.categorical_crossentropy)使用tf.keras.Sequential构建了一个顺序的模型,选择Adam作为优化器,交叉熵作为损失函数。让我们看一下模型的结构:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 128) 439552
_________________________________________________________________
lstm (LSTM) (None, None, 128) 131584
_________________________________________________________________
lstm_1 (LSTM) (None, None, 128) 131584
_________________________________________________________________
time_distributed (TimeDistri (None, None, 3434) 442986
=================================================================
Total params: 1,145,706
Trainable params: 1,145,706
Non-trainable params: 0
模型参数数量在1M左右,挺小的一个模型。
四、训练模型
数据和模型都已就位,可以开始训练了。在这之前,先考虑一个问题,如何评价训练结果呢?除了loss以外,人工观察模型生成的古体诗的质量也是一个选择。让我们先编写几个工具方法,用于使用模型随机生成古体诗。
# -*- coding: utf-8 -*-
# @File : utils.py
# @Author : AaronJny
# @Time : 2019/12/30
# @Desc :
import numpy as np
import settingsdef generate_random_poetry(tokenizer, model, s=''):"""随机生成一首诗:param tokenizer: 分词器:param model: 用于生成古诗的模型:param s: 用于生成古诗的起始字符串,默认为空串:return: 一个字符串,表示一首古诗"""# 将初始字符串转成tokentoken_ids = tokenizer.encode(s)# 去掉结束标记[SEP]token_ids = token_ids[:-1]while len(token_ids) < settings.MAX_LEN:# 进行预测,只保留第一个样例(我们输入的样例数只有1)的、最后一个token的预测的、不包含[PAD][UNK][CLS]的概率分布_probas = model.predict([token_ids, ])[0, -1, 3:]# print(_probas)# 按照出现概率,对所有token倒序排列p_args = _probas.argsort()[::-1][:100]# 排列后的概率顺序p = _probas[p_args]# 先对概率归一p = p / sum(p)# 再按照预测出的概率,随机选择一个词作为预测结果target_index = np.random.choice(len(p), p=p)target = p_args[target_index] + 3# 保存token_ids.append(target)if target == 3:breakreturn tokenizer.decode(token_ids)def generate_acrostic(tokenizer, model, head):"""随机生成一首藏头诗:param tokenizer: 分词器:param model: 用于生成古诗的模型:param head: 藏头诗的头:return: 一个字符串,表示一首古诗"""# 使用空串初始化token_ids,加入[CLS]token_ids = tokenizer.encode('')token_ids = token_ids[:-1]# 标点符号,这里简单的只把逗号和句号作为标点punctuations = [',', '。']punctuation_ids = {tokenizer.token_to_id(token) for token in punctuations}# 缓存生成的诗的listpoetry = []# 对于藏头诗中的每一个字,都生成一个短句for ch in head:# 先记录下这个字poetry.append(ch)# 将藏头诗的字符转成token idtoken_id = tokenizer.token_to_id(ch)# 加入到列表中去token_ids.append(token_id)# 开始生成一个短句while True:# 进行预测,只保留第一个样例(我们输入的样例数只有1)的、最后一个token的预测的、不包含[PAD][UNK][CLS]的概率分布_probas = model.predict([token_ids, ])[0, -1, 3:]# 按照出现概率,对所有token倒序排列p_args = _probas.argsort()[::-1][:100]# 排列后的概率顺序p = _probas[p_args]# 先对概率归一p = p / sum(p)# 再按照预测出的概率,随机选择一个词作为预测结果target_index = np.random.choice(len(p), p=p)target = p_args[target_index] + 3# 保存token_ids.append(target)# 只有不是特殊字符时,才保存到poetry里面去if target > 3:poetry.append(tokenizer.id_to_token(target))if target in punctuation_ids:breakreturn ''.join(poetry)两个方法,一个用于随机生成古体诗,另一个用于随机生成藏头诗。在训练时,我们只用随机生成古体诗的方法观察效果。在Keras里,可以通过回调(callback)执行测试方法。
# -*- coding: utf-8 -*-
# @File : train.py
# @Author : AaronJny
# @Time : 2020/01/01
# @Desc :
import tensorflow as tf
from dataset import PoetryDataGenerator, poetry, tokenizer
from model import model
import settings
import utilsclass Evaluate(tf.keras.callbacks.Callback):"""在每个epoch训练完成后,保留最优权重,并随机生成settings.SHOW_NUM首古诗展示"""def __init__(self):super().__init__()# 给loss赋一个较大的初始值self.lowest = 1e10def on_epoch_end(self, epoch, logs=None):# 在每个epoch训练完成后调用# 如果当前loss更低,就保存当前模型参数if logs['loss'] <= self.lowest:self.lowest = logs['loss']model.save(settings.BEST_MODEL_PATH)# 随机生成几首古体诗测试,查看训练效果print()for i in range(settings.SHOW_NUM):print(utils.generate_random_poetry(tokenizer, model))# 创建数据集
data_generator = PoetryDataGenerator(poetry, random=True)
# 开始训练
model.fit_generator(data_generator.for_fit(), steps_per_epoch=data_generator.steps, epochs=settings.TRAIN_EPOCHS,callbacks=[Evaluate()])通过执行train.py脚本,即可完成模型的训练。观察模型在每个epoch结束后的表现是一件很有意思的事。
刚开始训练,模型的输出有些乱七八糟的。字、标点胡乱的混在一起,完全没有格式。比如(每行是一首):
门长风,黄有秋尽天天白。门为还下长,去人上独。寒开入行水。时还客。莫月不鸟尽前,远
知白酒上,风青白中。无无风,春山白知,不如,雨新玉归,,知来知来。中月秋流。家何玉。,不山欲知难,空
玉知初归去,水酒尽如,欲长不未。林边还城,朝未无水,愁月思不,归烟声白。酒
风知家君子,秋客叶不,草生花此中,,林时下见长。烟天深何,时客,谁水雨时,白生雨不白。不向归闻。更玉远马。烟知满去。未见行有,
处风去阳,水西向水朝。行叶风水。空南天飞有。是今不白鸟。高有此得,应来日远道。万,将自秋水,人
从第二、三个epoch开始,模型的输出有些格式了。但还是有些很明显的问题,比如标点用错,上下句子长度不同。比如:
三行山此日,清朝不客人。寒知自一,似子夜,开城春身。云风雪天,不云客过。松未入无,千入里月。
再几个epoch之后,意境和用词先且不谈,模型算是成功学到了句式:
白竹芳人别,江云云云乡。野山连山鸟,深来上有心。夜时何时月,江马几路朝。何日能前客,青为复自情。
清人多三重,年上一未时。自云中有月,诗树风人泉。寒风非阳外,为影水未烟。到乡已何苦,留家不时明。
闲林山溪下,清花楚过时。花人自长去,窗树旧不时。水知远见花,愁此长云波。此中不声鹤,风雨亦更看。
下雨花山客,初开是有西。孤山无古后,青头到几乡。楚日时下路,天山松天秋。且来犹人下,何游白如诗。有君相几归,重泪不长开。
花高江水老,风向到花台。月山自日石,故叶雪海间。
随着迭代次数的增加,模型的输出看起来也变得像模像样了。我们在下一个小节使用训练了20个epoch后的权重,演示一下对模型的测试。
五、测试模型
逻辑很简单,加载训练好的模型,通过工具方法生成古体诗和藏头诗,两个工具方法前面都给出了,没什么好说的,直接看代码吧:
# -*- coding: utf-8 -*-
# @File : eval.py
# @Author : AaronJny
# @Time : 2020/01/01
# @Desc :
import tensorflow as tf
from dataset import tokenizer
import settings
import utils# 加载训练好的模型
model = tf.keras.models.load_model(settings.BEST_MODEL_PATH)
# 随机生成一首诗
print(utils.generate_random_poetry(tokenizer, model))
# 给出部分信息的情况下,随机生成剩余部分
print(utils.generate_random_poetry(tokenizer, model, s='床前明月光,'))
# 生成藏头诗
print(utils.generate_acrostic(tokenizer, model, head='海阔天空'))
执行脚本:
新安不忍赋,名步亦悠悠。夜向云沙雪,城连塞井边。潮销千雨入,云过露荷鲜。尽日相逢处,应怜别路遥。
床前明月光,声洒绿苔轻。惊梦知何事,春中亦相逢。绿云含露发,月月出铜罍。又共红脂袖,花香意欲同。
海前多道长,阔地为行游。天汉一家疾,空林应自秋。
再来一次:
江郭茫茫径复霜,月明帆落半相思。莫伤白日犹深笑,明月同来见五京。
床前明月光,水在紫楼长。水晓风犹尽,山从雪暮霜。风枝回枕急,湖树向流塘。早日知同客,沧溟满谷川。
海上长初入,阔山谁独同。天开天际里,空尽一声声。
六、结语
好了,如上就是本篇文章的全部内容,希望对你有所帮助。
如果你喜欢这篇文章的话,麻烦给点个赞呗~
菜鸟一只,如有纰漏之处,请大佬们指正,欢迎各位大佬拍砖~
参考
bojone/bert4keras