数据集
因为数据量庞大,使用本地的 CSV 数据进行测试。

后续改进 CSV 文件保存到 mongodb 数据库,便于聚合查询。
数据分词
我们需要一个分词器将这些数据进行分词,用到的是 Golang 版的 jieba 库如下:
"github.com/go-ego/gse"最理想的分词器是将长短句中的名词进行提取,本 demo 使用自带的分词器。根据官方示例进行数据分词:
package utilimport ("flag""fmt""log""os""regexp""github.com/go-ego/gse""github.com/go-ego/gse/hmm/idf""github.com/go-ego/gse/hmm/pos"
)var (seg gse.SegmenterposSeg pos.Segmenter)// 分词库初始化
func init() {// Loading the default dictionaryerr := seg.LoadDict()// Loading the default dictionary with embed//err := seg.LoadDictEmbed()// Loading the traditional chinese dictionary//err := seg.LoadDict("zh_t")// 加载停用词//err := seg.LoadDict("../data/stopwords/baidu_stopwords.txt")//err := seg.LoadDict("../data/stopwords/cn_stopwords.txt")//err := seg.LoadDict("../data/stopwords/hit_stopwords.txt")//err := seg.LoadDict("../data/stopwords/scu_stopwords.txt")if err != nil {log.Println(err)return}
}func GetName(t string) {//cut := seg.Cut(t)cut := seg.CutSearch(t, true)cut = seg.Trim(cut)fmt.Println("cut all: ", cut)saveAsFile("NameArray.txt", cut)
}func saveAsFile(fileName string, data []string) {fp, _ := os.OpenFile(fileName, os.O_CREATE|os.O_APPEND|os.O_RDWR, os.ModeAppend|os.ModePerm) // 读写方式打开defer fp.Close()for _, v := range data {fp.WriteString(v + "\n")}
}
以上代码包括的官方示例和根据示例进行数据的分词,将分词结果保存为 txt 文件:
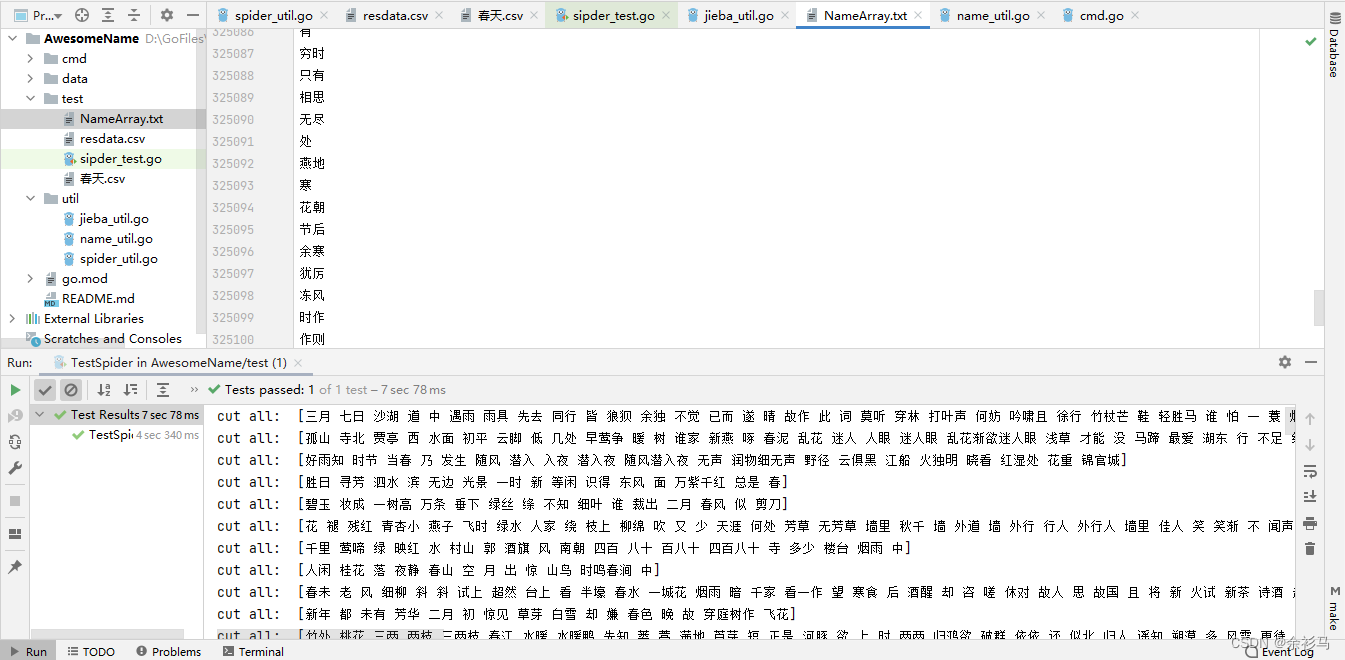
以回车符为标志,保存分词结果,是为了后续能够随机地取单词,通过行数的随机数生成,就可以随机读取单词,达到随机取词效果。
随机参数
根据时间种子进行随机数生成,返回十个随机单词:
package utilimport ("bufio""io""log""math/rand""os""time"
)func GenerateName() {// 时间戳作为随机种子rand.Seed(time.Now().Unix())//getNameFile("../test/NameArray.txt")for i := 0; ; {random := rand.Intn(16497)name := ReadLine("../test/NameArray.txt", random, 3*2)if len(name) > 0 {log.Println(name)i++if i > 10 {break}}}
}func ReadLine(fileName string, lineNumber, length int) string {file, _ := os.Open(fileName)fileScanner := bufio.NewScanner(file)lineCount := 1for fileScanner.Scan() {if lineCount == lineNumber {name := fileScanner.Text()if len(name) == length {return name} else {//log.Println(fileScanner.Text(), len(fileScanner.Text()), length)return ""}break}lineCount++}defer file.Close()return ""
}func getNameFile(fileName string) {fp, e := os.OpenFile(fileName, os.O_RDONLY, 0644)if e != nil {log.Println(e)}defer fp.Close()//读入缓存buff := bufio.NewReader(fp)for {//以'\n'为结束符读入一行line, e := buff.ReadString('\n')if e != nil || io.EOF == e {log.Println(e)break}log.Println(line)}
}
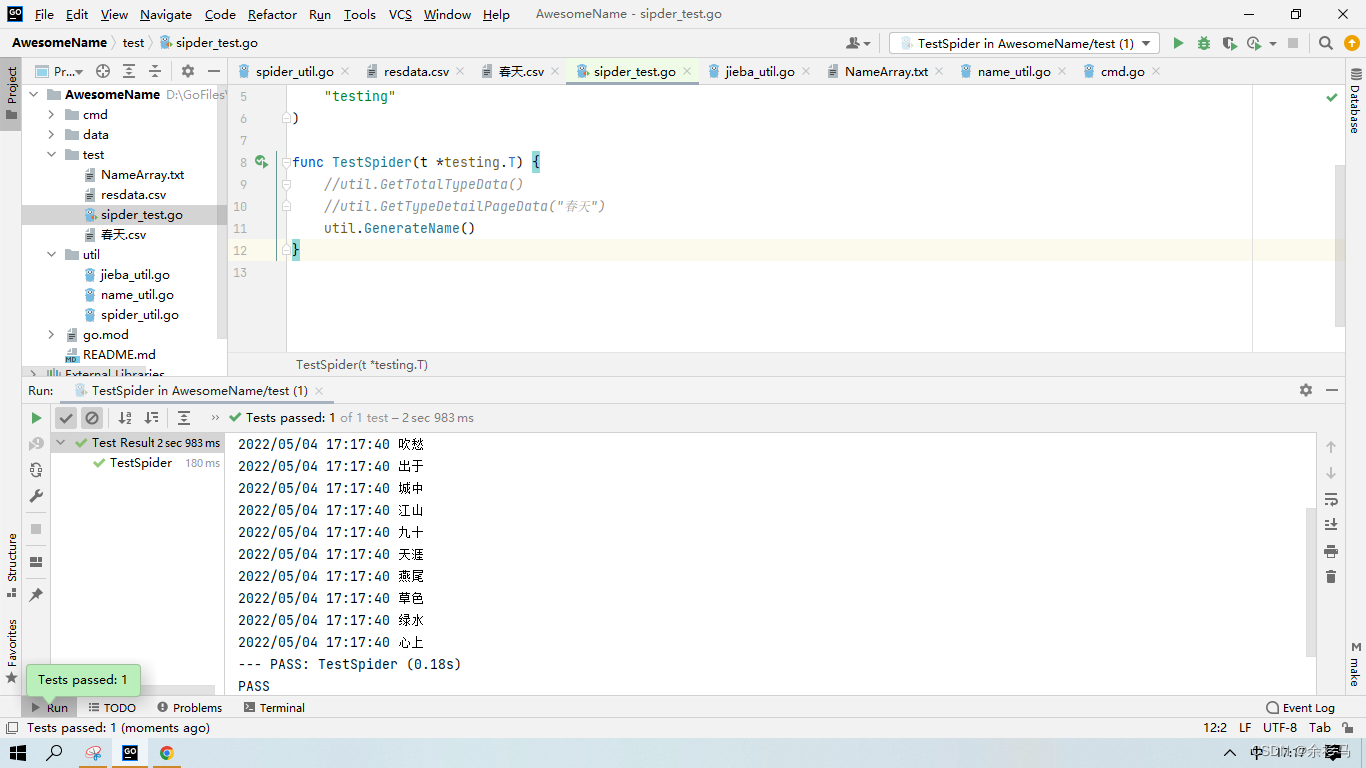
2022/05/04 17:17:40 绿波
2022/05/04 17:17:40 吹愁
2022/05/04 17:17:40 出于
2022/05/04 17:17:40 城中
2022/05/04 17:17:40 江山
2022/05/04 17:17:40 九十
2022/05/04 17:17:40 天涯
2022/05/04 17:17:40 燕尾
2022/05/04 17:17:40 草色
2022/05/04 17:17:40 绿水
2022/05/04 17:17:40 心上由输出结果可见,分词结果和随机参数效果并不是很好,需要后续改进。
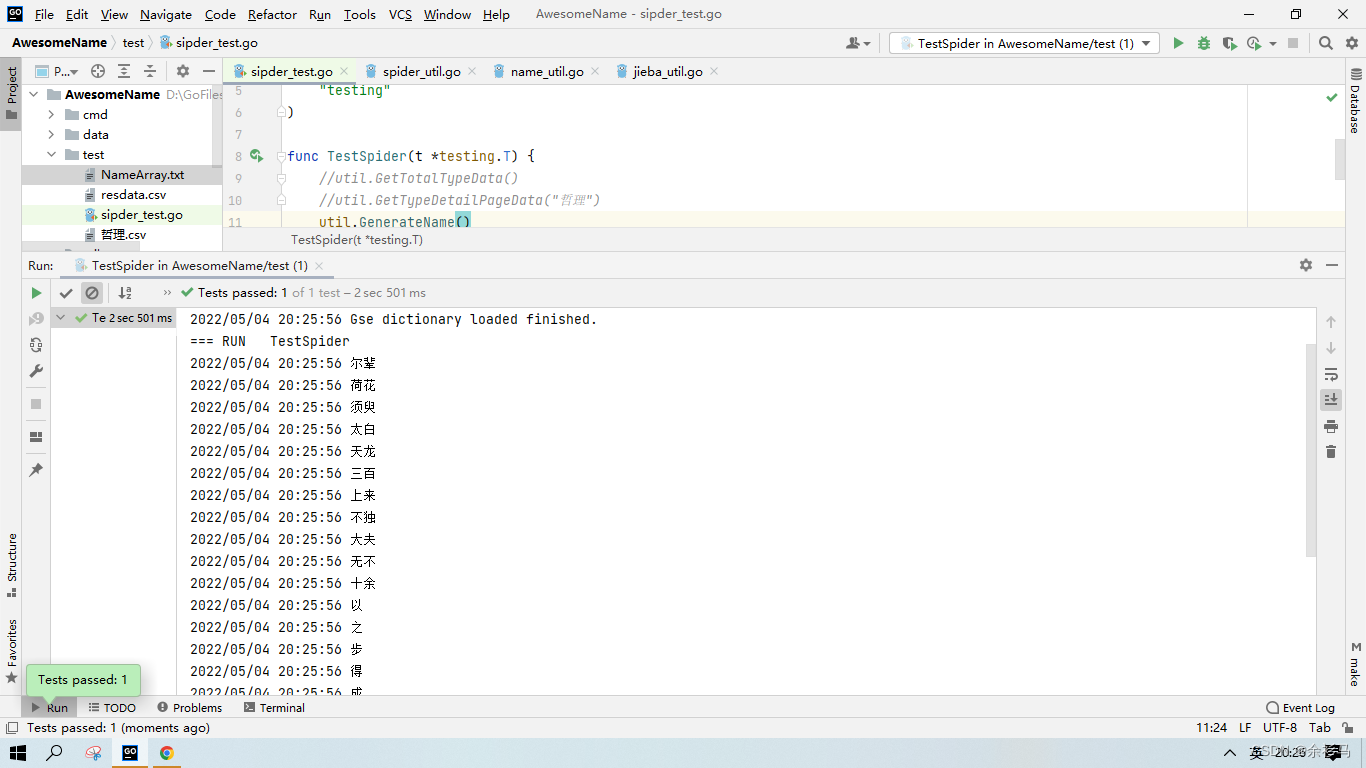
分词改进
func GetName(t string) {po := seg.Pos(t, true)//fmt.Println("pos: ", po)po = seg.TrimWithPos(po, "zg", "x", "v", "i", "c", "r", "l")//po = seg.TrimWithPos(po, "zg", "x", "v")//fmt.Println("trim pos: ", po)var cut []stringfor _, v := range po {if len(v.Text) > 6 {//log.Println(v.Text, v.Pos)} else {log.Println(v.Text, v.Pos)cut = append(cut, v.Text)}}//cut := seg.Cut(t)//cut := seg.CutSearch(t, true)//cut = seg.Trim(cut)//fmt.Println("cut all: ", cut)saveAsFile("NameArray.txt", cut)}使用 TrimWithPos 剔除一些特殊的词语,尽量保留名词,效果如下: