一共实现三个功能:
1. 续写五言诗
2. 续写七言诗
3. 写五言藏头诗
之前用这个做Intro to Computer Science的期末项目折腾太久,不想赘述,内容介绍及实现方法可参考期末presentation的slides:
https://docs.google.com/presentation/d/1DFy3VwAETeqK0QFsokeBpDwyVkMavOjpckQKpc6XPTI/edit#slide=id.gb037c6e317_2_312
训练数据来源:
https://github.com/BraveY/AI-with-code/tree/master/Automatic-poem-writing
五言诗数据预处理(七言类似,不再贴代码):
import os
import numpy as np
import numpy as npfrom copy import deepcopyall_data = np.load("tang.npz", allow_pickle=True)
dataset = all_data["data"]
word2ix = all_data["word2ix"].item()
ix2word = all_data["ix2word"].item()
print(len(word2ix))
print(dataset.shape)
l = dataset.tolist()
poems = [[None for i in range(125)] for j in range(57580)]
for i in range(57580):for j in range(125):poems[i][j] = ix2word[l[i][j]]data = list()
for i in range(57580):s = 0e = 0for ele in poems[i]:if ele == '<START>':s += 1if ele == '<EOP>':e += 1if s == 1 and e == 1:st = poems[i].index('<START>')ed = poems[i].index('<EOP>')if (ed - st - 1) % 6 == 0 and poems[i][st + 6] == ',' and (ed - st - 1) == 48:# 五言诗,每诗4句line = poems[i][st + 1:ed]for j in range(0, len(line), 24):cur = line[j:j + 24]if cur[5] == ',' and cur[11] == '。' and cur[17] == ',' and cur[23] == '。':data.append(cur)# for ele in data:
# print(ele)
print(len(data))
t = list()
for i, line in enumerate(data):print(i, line)words = line[0:5] + line[6:11] + line[12:17] + line[18:23]nums = [word2ix[words[i]] for i in range(len(words))]t.append(nums)t = np.array(t)
print(t.shape)t = t[77:]labels = deepcopy(t)
for i in range(29696):for j in range(20):if j < 19:labels[i][j] = labels[i][j+1]else:labels[i][j] = 0
np.save("train_x.npy", t)
np.save("train_y.npy", labels)
五言诗训练(七言类似,不再贴代码):
# -*- coding: utf-8 -*-
"""54.ipynbAutomatically generated by Colaboratory.Original file is located athttps://colab.research.google.com/drive/1ZdPq71-40K5tGK__OPcUe84mfopWwJP-
"""import numpy as np
import matplotlib.pyplot as pltimport torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as Ffrom copy import deepcopyVOCAB_SIZE = 8293all_data = np.load("/content/drive/My Drive/Deep Learning/LSTM - Chinese Poem Writer/tang.npz", allow_pickle=True)
word2ix = all_data["word2ix"].item()
ix2word = all_data["ix2word"].item()class Model(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim):super(Model, self).__init__()self.hidden_dim = hidden_dimself.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, self.hidden_dim, num_layers=3)self.out = nn.Linear(self.hidden_dim, vocab_size)def forward(self, input, hidden=None):seq_len, batch_size = input.shapeif hidden is None:h_0 = torch.zeros(3, batch_size, self.hidden_dim).cuda()c_0 = torch.zeros(3, batch_size, self.hidden_dim).cuda()else:h_0, c_0 = hiddenembed = self.embedding(input)# embed_size = (seq_len, batch_size, embedding_dim)output, hidden = self.lstm(embed, (h_0, c_0))# output_size = (seq_len, batch_size, hidden_dim)output = output.reshape(seq_len * batch_size, -1)# output_size = (seq_len * batch_size, hidden_dim)output = self.out(output)# output_size = (seq_len * batch_size, vocab_size)return output, hiddentrain_x = np.load("/content/drive/My Drive/Deep Learning/LSTM - Chinese Poem Writer/train_x_54.npy")
train_y = np.load("/content/drive/My Drive/Deep Learning/LSTM - Chinese Poem Writer/train_y_54.npy")id = 253print(train_x.shape)
print(train_y.shape)
print(train_x[id])
print(train_y[id])
a = [None for i in range(20)]
b = [None for j in range(20)]
for j in range(20):a[j] = ix2word[train_x[id][j]]b[j] = ix2word[train_y[id][j]]
b[19] = 'Null'
print(a)
print(b)class PoemWriter():def __init__(self):self.model = Model(VOCAB_SIZE, 64, 128)self.lr = 1e-3self.epochs = 0self.seq_len = 20self.batch_size = 128self.opt = optim.Adam(self.model.parameters(), lr=self.lr)def train(self, epochs):self.epochs = epochsself.model = self.model.cuda()criterion = nn.CrossEntropyLoss()all_losses = []for epoch in range(self.epochs):print("Epoch:", epoch + 1)total_loss = 0for i in range(0, train_x.shape[0], self.batch_size):# print(i, i + self.batch_size)cur_x = torch.from_numpy(train_x[i:i + self.batch_size])cur_y = torch.from_numpy(train_y[i:i + self.batch_size])cur_x = torch.transpose(cur_x, 0, 1).long()cur_y = torch.transpose(cur_y, 0, 1).long()cur_y = cur_y.reshape(self.seq_len * self.batch_size, -1).squeeze(1)cur_x, cur_y = cur_x.cuda(), cur_y.cuda()pred, _ = self.model.forward(cur_x)loss = criterion(pred, cur_y)self.opt.zero_grad()loss.backward()self.opt.step()total_loss += loss.item()print("Loss:", total_loss)all_losses.append(total_loss)self.model = self.model.cpu()plt.plot(all_losses, 'r')def write(self, string="空山新雨后"):inp = []for c in string:inp.append(word2ix[c])inp = torch.from_numpy(np.array(inp)).unsqueeze(1).long()# print(inp.shape, inp)tmp = torch.zeros(15, 1).long()inp = torch.cat([inp, tmp], dim=0)inp = inp.cuda()self.model = self.model.cuda()for tim in range(15):pred, _ = self.model.forward(inp)pred = torch.argmax(pred, dim=1)inp[tim + 5] = pred[tim + 4]ans = list()for i in range(20):ans.append(ix2word[inp[i].item()])out = ""for i in range(20):out += ans[i]if i == 4 or i == 14:out += ','if i == 9 or i == 19:out += '。'print(out)torch.cuda.get_device_name()Waner = PoemWriter()Waner.train(1000)Waner.write()torch.save(Waner.model, '/content/drive/My Drive/Deep Learning/LSTM - Chinese Poem Writer/model_54.pkl')while True:st = input()if st == "-1":breakWaner.write(st)
最终模型:
import numpy as np
import matplotlib.pyplot as pltimport torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as Ffrom copy import deepcopyVOCAB_SIZE = 8293all_data = np.load("tang.npz", allow_pickle=True)
word2ix = all_data["word2ix"].item()
ix2word = all_data["ix2word"].item()class Model(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim):super(Model, self).__init__()self.hidden_dim = hidden_dimself.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, self.hidden_dim, num_layers=3)self.out = nn.Linear(self.hidden_dim, vocab_size)def forward(self, input, hidden=None):seq_len, batch_size = input.shapeif hidden is None:h_0 = torch.zeros(3, batch_size, self.hidden_dim).cuda()c_0 = torch.zeros(3, batch_size, self.hidden_dim).cuda()else:h_0, c_0 = hiddenembed = self.embedding(input)# embed_size = (seq_len, batch_size, embedding_dim)output, hidden = self.lstm(embed, (h_0, c_0))# output_size = (seq_len, batch_size, hidden_dim)output = output.reshape(seq_len * batch_size, -1)# output_size = (seq_len * batch_size, hidden_dim)output = self.out(output)# output_size = (seq_len * batch_size, vocab_size)return output, hiddenclass Writer():def __init__(self):self.model_74 = torch.load('model_74.pkl')self.model_54 = torch.load('model_54.pkl')# self.lr = 1e-3self.epochs = 0self.seq_len = 28self.batch_size = 128# self.opt = optim.Adam(self.model.parameters(), lr=self.lr)def write_74(self, string="锦瑟无端五十弦"):inp = []for c in string:inp.append(word2ix[c])inp = torch.from_numpy(np.array(inp)).unsqueeze(1).long()# print(inp.shape, inp)tmp = torch.zeros(21, 1).long()inp = torch.cat([inp, tmp], dim=0)inp = inp.cuda()self.model_74 = self.model_74.cuda()for tim in range(21):pred, _ = self.model_74.forward(inp)pred = torch.argmax(pred, dim=1)inp[tim + 7] = pred[tim + 6]ans = list()for i in range(28):ans.append(ix2word[inp[i].item()])out = ""for i in range(28):out += ans[i]if i == 6 or i == 20:out += ','if i == 13 or i == 27:out += '。'return outdef write_54(self, string="空山新雨后"):inp = []for c in string:inp.append(word2ix[c])inp = torch.from_numpy(np.array(inp)).unsqueeze(1).long()# print(inp.shape, inp)tmp = torch.zeros(15, 1).long()inp = torch.cat([inp, tmp], dim=0)inp = inp.cuda()self.model_54 = self.model_54.cuda()for tim in range(15):pred, _ = self.model_54.forward(inp)pred = torch.argmax(pred, dim=1)inp[tim + 5] = pred[tim + 4]ans = list()for i in range(20):ans.append(ix2word[inp[i].item()])out = ""for i in range(20):out += ans[i]if i == 4 or i == 14:out += ','if i == 9 or i == 19:out += '。'return outdef acrostic(self, string="为尔心悦"):inp = torch.zeros(20, 1).long()inp = inp.cuda()self.model_54 = self.model_54.cuda()for i in range(20):if i == 0 or i == 5 or i == 10 or i == 15:inp[i] = word2ix[string[i // 5]]else:inp[i] = pred[i - 1]pred, _ = self.model_54.forward(inp)pred = torch.argmax(pred, dim=1)ans = list()for i in range(20):ans.append(ix2word[inp[i].item()])out = ""for i in range(20):out += ans[i]if i == 4 or i == 14:out += ','if i == 9 or i == 19:out += '。'return outdef task(self, string):l = len(string)try:if l == 4:return self.acrostic(string)elif l == 5:return self.write_54(string)elif l == 7:return self.write_74(string)except:return "I don't know how to write one...QAQ"'''
a = torch.ones(5)
a[1] = 4
print(a)
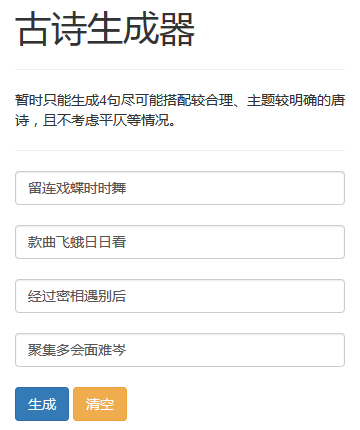
'''测试样例:

虽然韵脚未专门处理,大多不太对,但是能学到一些意象并营造一定意境,如果用更好的word embedding可能会有更好的performance(目前的embedding为pytorch随机生成)。