- 1.语料准备:包含 5.5 万首唐诗、26 万首宋诗、2.1 万首宋词和其他古典文集。诗人包括唐宋两朝近 1.4 万古诗人,和两宋时期 1.5 千古词人。数据来源于互联网。每行一首诗,标题在预处理的时候已经去掉了。
- 2.模型参数配置:预先定义模型参数和加载语料以及模型保存名称,通过类 Config 实现。
- 3.文本读取预处理:过滤掉低频字,构建词典与词典id的映射。
- 4.构建模型:
模型代码
input_tensor = Input(shape=(self.config.max_len, len(self.words)))lstm = LSTM(512, return_sequences=True)(input_tensor)dropout = Dropout(0.6)(lstm)lstm = LSTM(256)(dropout)dropout = Dropout(0.6)(lstm)dense = Dense(len(self.words), activation='softmax')(dropout)self.model = Model(inputs=input_tensor, outputs=dense)optimizer = Adam(lr=self.config.learning_rate)self.model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])- 第一行: 构造输入向量
- 第二行,构造了一个LSTM layer, hidden units size = 512
- 第三行,构造了一个dropout layer,dropout rate = 0.6
- 第四行,构造了一个LSTM layer,hidden units size = 256
- 第五行,构造了一个dropout layer,dropout rate = 0.6
- 第六行,构造了一个全连接层+softmax 作为 output layer
- 第七行,利用 inputs 和 outputs 构造Model
- 第八行,使用 Adam 优化器
- 第九行,compile model,指定了模型的损失函数类型为交叉熵损失,优化器以及评价指标
数据训练花很长时间,训练完成之后,原始的代码一共提供了4个进行predict 的API:
- predict_first:给定一个汉字,输出一首五言绝句
- predict_random:随机从全部的训练诗作当中抽出一首诗的首句,然后生成一首诗
- predict_gen:给定五个汉字作为首句,生成一首五言绝句
- predict_hide:给定四个汉字,输出以这个四个汉字开头的藏头诗
运行:
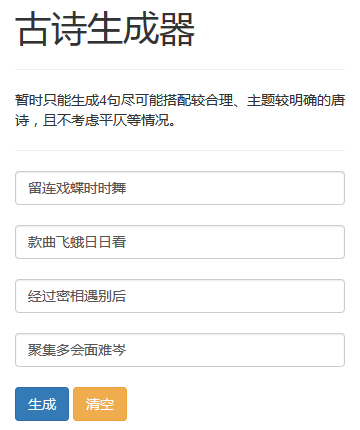
随机生成古诗如下
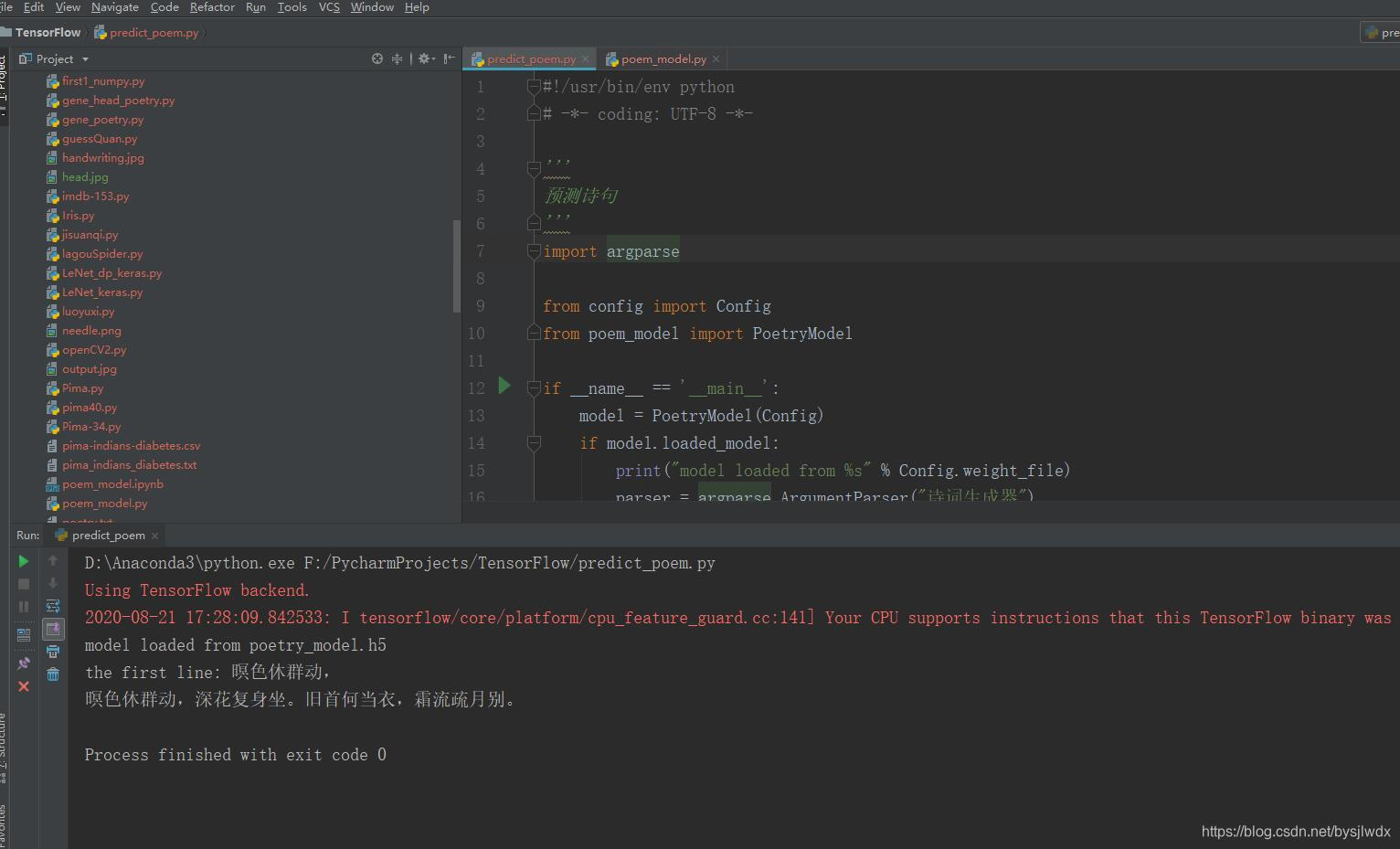
古诗生成
给定一个汉字
python predict_poem.py -pf 李
生成
李相时老玉,山终北合徒。游无归吾西,间人老无曙。
给定四个汉字
python predict_poem.py -ph 我爱李月
生成古诗
我鸣朝东秋,爱青无空归。李五亲日光,月鱼不时绿。
参考网址https://www.cnblogs.com/lyrichu/p/11257408.html