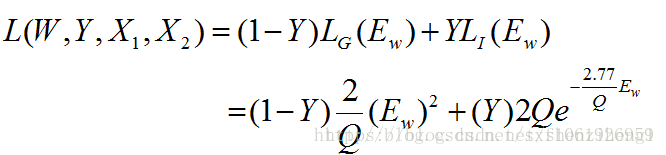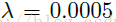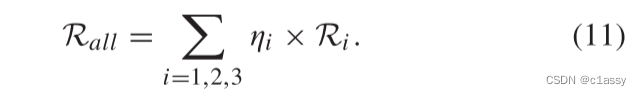SiameseFC
- 前言
- 论文来源
- 参考文章
- 论文原理解读
- 首先要知道什么是SOT?(Siamese要做什么)
- SiameseFC要解决什么问题?
- SiameseFC用了什么方法解决?
- SiameseFC网络效果如何?
- SiameseFC基本框架结构
- SiameseFC网络结构
- SiameseFC基本流程
- SiamFC完整的跟踪过程
- 论文的思考与优化
- SiameseFC的优点:
- SiameseFC的不足:(Siamese一直有鲁棒性不好的问题)
- 论文代码解读
- 训练阶段:
- 1.backbones.py分析
- 2.heads.py分析
- 3.train.py分析
- 4.transforms.py分析
- 5.ops.py分析(train相关部分)
- 6.datasets.py
- 7.siamfc.py分析(重点:train相关部分)
- tracking部分:
- siamfc.py(tracking部分)
- 论文翻译+解读
- Abstract
- 1 Introduction
- 2 Deep Similarity Learning for Tracking
- 2.1 Fully-Convolutional Siamese Architecture
- 2.2 Training with Large Search Images
- 2.3 ImageNet Video for Tracking
- 2.4 Practical Considerations
- 3 Related Work
- 4 Experiments
- 4.1 Implementation Details
- 4.2 Evaluation
- 4.3 The OTB-13 Benchmark
- 4.4 The VOT Benchmarks
- 4.5 Dataset Size
- 5 Conclusion
前言
论文来源
论文:Fully-Convolutional Siamese Networks for Object Tracking
项目官方地址(包括论文下载地址、源码地址等):这里
参考文章
论文阅读:SiameseFC
精读深度学习论文(31) SiameseFC
【SOT】siameseFC论文和代码解析
浅谈SiameseFC的优点与不足
siamfc-pytorch代码讲解(一):backbone&head
SiamFC完整的跟踪过程
其余的文章参考较少,在文中时会给出参考文章。
论文原理解读
首先要知道什么是SOT?(Siamese要做什么)
SOT的思想是,在视频中的某一帧中框出你需要跟踪目标的bounding box,在后续的视频帧中,无需你再检测出物体的bounding box进行匹配,而是通过某种相似度的计算,寻找需要跟踪的对象在后续帧的位置,如下动图所示(图中使用的是本章所讲siameseFC的升级版siameseMask),常见的经典的方法有KCF[2]等。
SiameseFC要解决什么问题?
而目前基于深度学习的方法,要不就是采用 shallow methods(如:correlation filters)利用网络的中间表示作为 feature;要不就是执行 SGD 算法来微调多层网络结构。但是,利用 shallow 的方法并不能充分发挥 end-to-end 训练的优势,采用 SGD 的方法来微调也无法达到实时的要求。
将DL用于tracking中,有两点制约其发展:
1、训练数据的稀缺。由于跟踪目标事先未知,只能通过最初的框选定,无法预先准备大量训练数据。
2、实时的约束。对于跟踪问题来说,基于DL的做法虽然能有效提升模型的丰富度,能够很好的提升跟踪的效果,但是在时效性这一方面却做的很差,因为DL复杂的模型往往需要很大的计算量,尤其是当使用的DL模型在跟踪的时候需要对模型进行更新的话,需要在线SGD调整网络参数,限制了速度,可能使用GPU都没法达到实时。
SiameseFC分别针对这两点,利用ILSVRC15 数据库中用于目标检测的视频来训练模型(离线训练),在跟踪时,不更新模型(也就没有fine-tuning),保证速度够快。成为了使用了CNN进行跟踪,同时又具有很高的效率的跟踪算法。并因其速度很快,效果很好,成为之后很多算法(例如CFNet、DCFNet)的baseline。
SiameseFC用了什么方法解决?
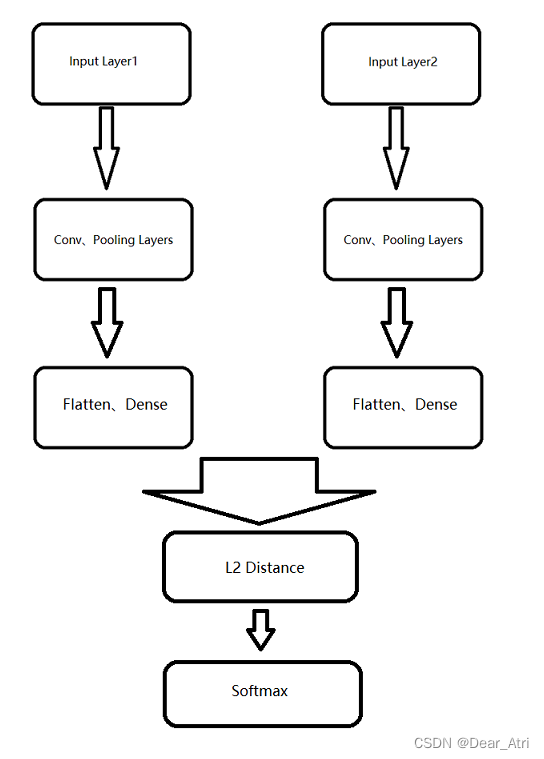
使用孪生网络(Siamese Net)结构来进行相似度比较,对比模版图片(在训练前应该指定好)和需比较的目标图片之间的相似度。
SiameseFC网络效果如何?
速度是SiameseFC的最大优势。
可以用于追踪任意物体(不需要预先训练)。
在当时某几个benchmark上达到了最优。
SiameseFC基本框架结构
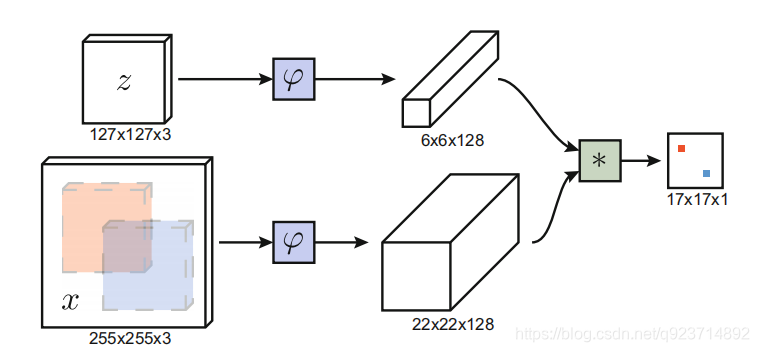
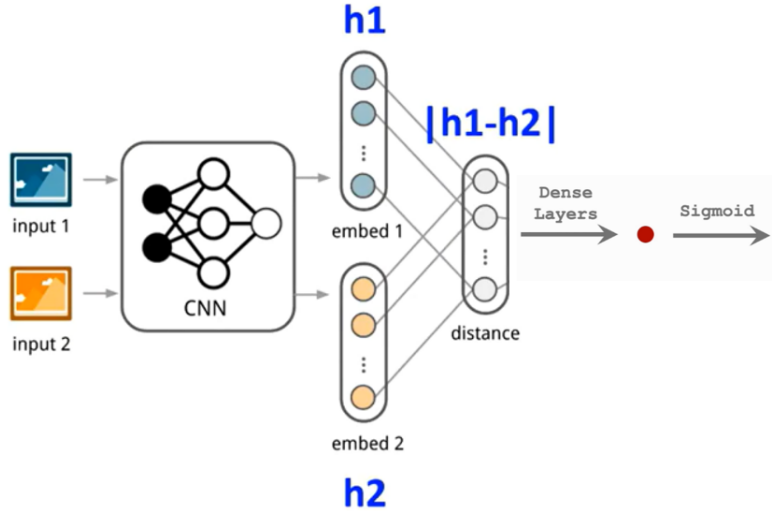
图中z代表的是模板图像,算法中使用的是第一帧的groundtruth;x代表的是search region,代表在后面的待跟踪帧中的候选框搜索区域;ϕ代表的是一种特征映射操作,将原始图像映射到特定的特征空间,文中采用的是CNN中的卷积层和pooling层;66128代表z经过ϕ后得到的特征,是一个128通道66大小feature,同理,2222128是x经过ϕ后的特征;后面的代表卷积操作,让2222128的feature被66128的卷积核卷积,得到一个17*17的score map,代表着search region中各个位置与模板相似度值。score越大,相似度越大,越有可能是同一个物体。
总体来说,卷积网络将search image作为整体输入,直接计算两个输入图像的feature map的相似度匹配,节省了计算。计算得到相似度最高的位置,并反向计算出目标在原图中的位置。
算法本身是比较搜索区域与目标模板的相似度,最后得到搜索区域的score map。其实从原理上来说,这种方法和相关性滤波的方法很相似。其在搜索区域中逐个的对目标模板进行匹配,将这种逐个平移匹配计算相似度的方法看成是一种卷积,然后在卷积结果中找到相似度值最大的点,作为新的目标的中心。
上述互相关运算的步骤,像极了我们手里拿着一张目标的照片(模板图像),然后把这个照片按在需要寻找目标的图片上(搜索图像)进行移动,然后求重叠部分的相似度,从而找到这个目标,只不过为了计算机计算的方便,使用AlexNet对图像数据进行了编码/特征提取。
上图所画的ϕ其实是CNN中的一部分,并且两个ϕ的网络结构是一样的,这是一种典型的孪生神经网络,并且在整个模型中只有conv层和pooling层,因此这也是一种典型的全卷积(fully-convolutional)神经网络。
如果上面没看懂,下面给出另一种我觉得也很棒的解释:
孪生结构网络是卷积神经网络中的一种特殊结构。其结构如上图所示,它由两个结构相同的子网络构成,网络的输入是两张像,其中一张称为模板图像,通常选取的是序列第一帧,另外一张称为搜索图像,选取的是后续帧,每一个子网络负责处理一张图像,通过子网络的前向计算,可以提取图像的特征,最后将两者特征通过相似性度量函数,最终计算得到一个17×17×1的热力图,代表着搜索图像中各个位置与模板图像的相似度值。并根据以下函数计算相似度(卷积函数):
其中z是模板图像,x是搜索图像,
φ代表的是一种特征映射操作,将原始图像映射成特定的空间特征,这里采用的是卷积神经网络里的卷积层和池化层,f是相似性度量函数,这里代表的是卷积函数。模板图像虽然使用的是视频序列的第一帧,但是它是经过裁剪而来的,以待跟踪目标为中心,把原图像裁剪成127×127的尺寸。
也是经过裁剪而来的,它是以网络上一次输出的目标位置的中心点作为裁剪的中心,裁剪成固定的255×255的尺寸。
在这里就相当于充当一个待跟踪目标的外观模型,与后续图像帧里面的对象进行配对,热力图最里面分值最高的那个点则认为是与待跟踪对象外观模型最相似,就认为它是后续帧里的待跟踪对象。
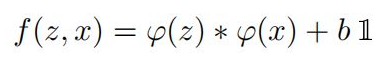
SiameseFC网络结构
用模板的CNN特征与搜索图像的特征进行卷积,得到整个图像的相似图。网络结构如下:(有的博客中说整个网络结构类似与AlexNet,但是没有最后的全连接层,只有前面的卷积层和pooling层。 )
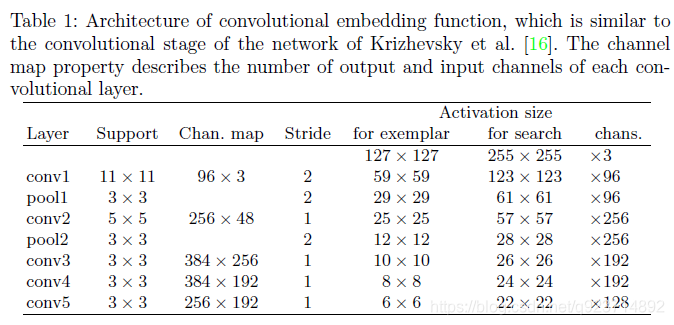
整个网络结构入上表,其中pooling层采用的是max-pooling,每个卷积层后面都有一个ReLU非线性激活层,但是第五层没有。另外,在训练的时候,每个ReLU层前都使用了batch normalization,用于降低过拟合的风险。
SiameseFC基本流程
一,获取输入数据:
SiameseFC需要的输入数据有模版图片z和候选图片x。
- 模版图片z的构建:
- 构建模版图片时,知道当前帧的bbox。
- 训练时,所有图片的bbox都是已知的。
- 预测时,第一帧bbox已知的,且预测是顺序预测,因此,预测过程中,预测帧前一帧的bbox是已知的。
- 总体过程:
- 以bbox的中心为中心,构建一个面积为127*127的区域,如果超出范围则通过平均值进行pad。
- 将该区域resize为127*127。(上一步中的长宽可能不是127)
- 构建127127区域的方式如下:其中A=127127,h和w代表bbox的长宽:
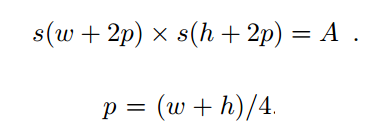
- 构建模版图片时,知道当前帧的bbox。
- 候选图片x的构建:
- 构建时已知其上一帧bbox的信息。
- 总体过程:
- 以上一帧bbox的中心为中心,构建一个面积为255*255的区域,如果超出范围则通过平均值进行pad。
- 将该区域resize为255*255。(上一步中的长宽可能不是255)
- 构建255*255区域与构建模版图片z时采用相同的缩放比例。
二,通过分数矩阵获取追踪结果
总体过程:
- 首先,对分数矩阵进行线性变换,变换到原始图片的大小。
- 如图中,将图片1717分数矩阵转换为255255。
- 然后,结合位置信息,获取最终得分信息。
- 最后,选择得分最高的位置作为中心,获取最新的bbox。
- bbox的长宽跟之前一帧的长宽一致。
三,通过分数矩阵进行训练
-
使用交叉熵作为损失函数。对于score map中每个点,损失函数如下:
- 其中,其中v是score map中每个点真实值,y∈{+1,−1}是这个点所对应的标签。
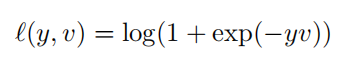
- 其中,其中v是score map中每个点真实值,y∈{+1,−1}是这个点所对应的标签。
-
总体损失函数如下:
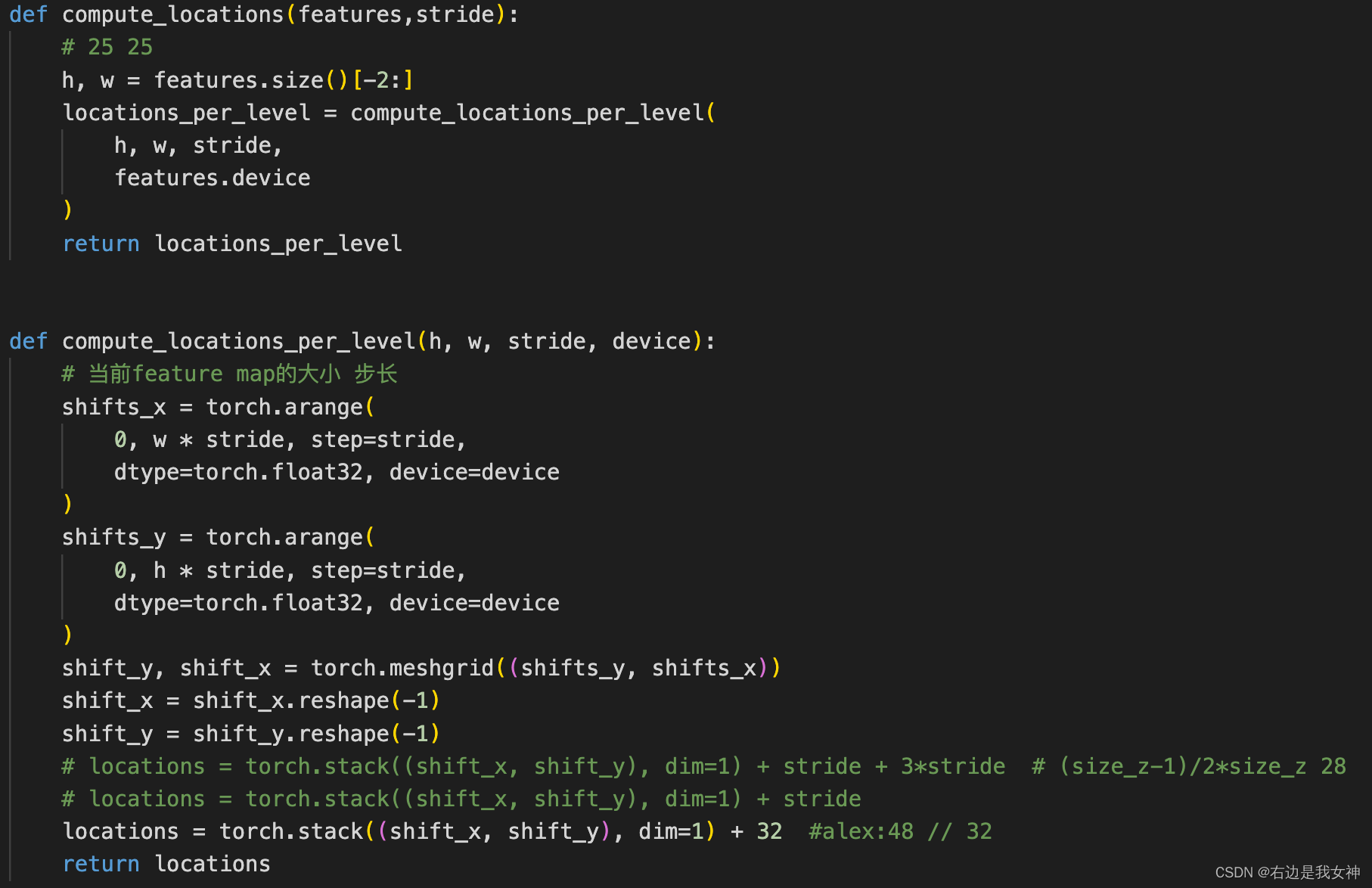
6×6和22×22的feature map“卷积”得到17×17的score map。对于每个score map,计算其loss为每个卷积得到的6*6小图的loss的均值。即:
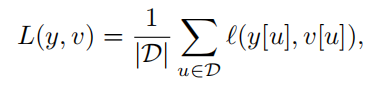
这里的u∈D代表score map中的位置。 卷积网络的参数由SGD方法最小化上图损失函数得到。这里采用的是卷积神经网络里的卷积层和池化层,f是相似性度量函数,这里代表的是卷积函数。 -
构建标签y
比较预测bbox中心点与 ground truth 的bbox中心点之间的距离。
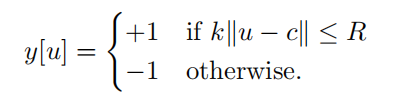
-
计算相似度(卷积函数)
根据以下函数计算相似度(卷积函数):
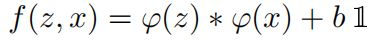
其中z是模板图像,x是搜索图像, φ代表的是一种特征映射操作,将原始图像映射成特定的空间特征
四, 多尺寸处理
思路:
- 模版图片z保持不变。
- 对搜索图片x进行尺寸变换,同样提取255*255的区域,计算相似度,获取相似度最大点的坐标。
- 对于最终bbox进行等比例变换(比例就是对搜索图片x进行变换的比例)。
五,训练的一些细节
- 训练采用的框架是MatConvNet
- 训练采用的优化算法就是batch SGD,batch大小是8
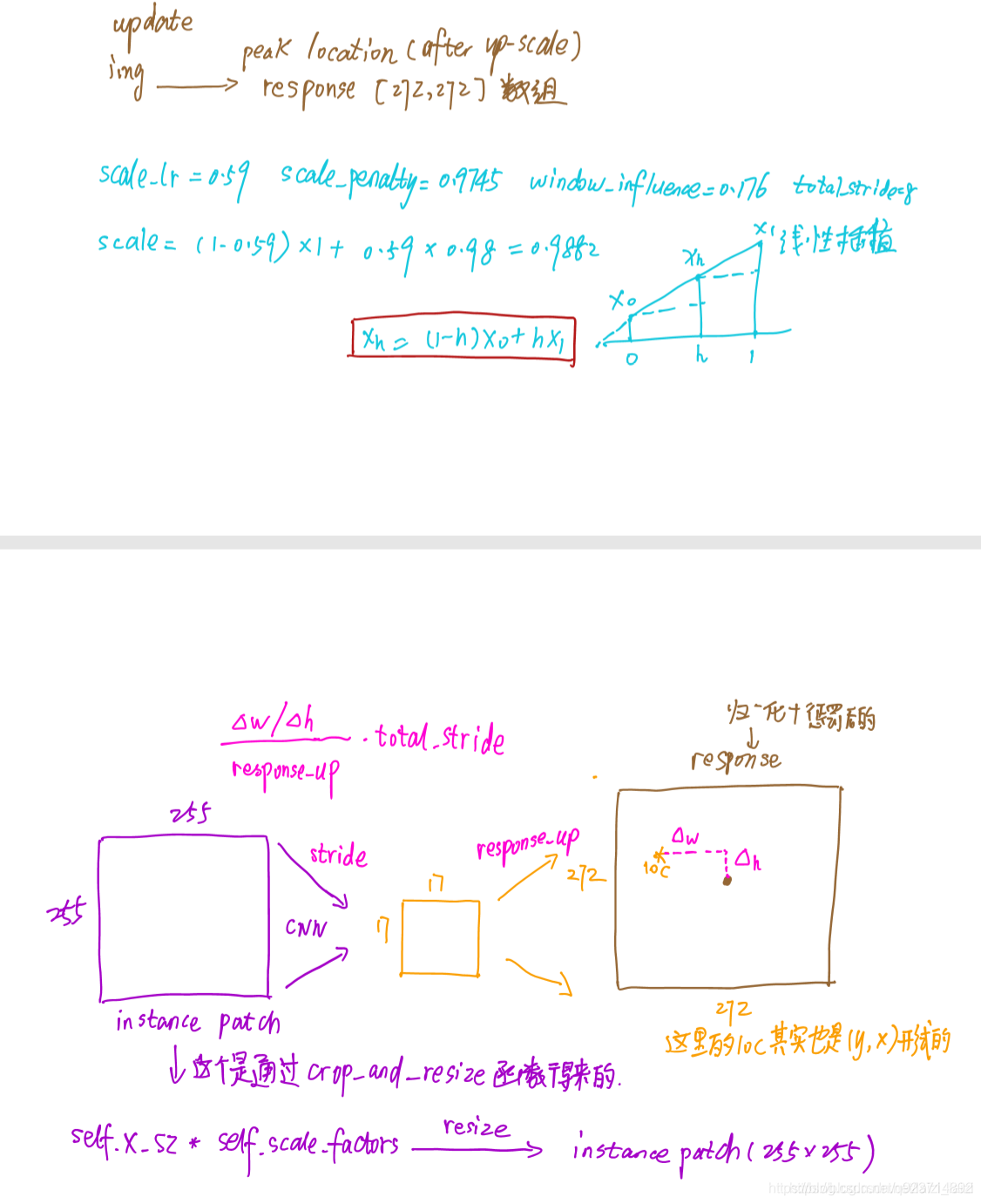
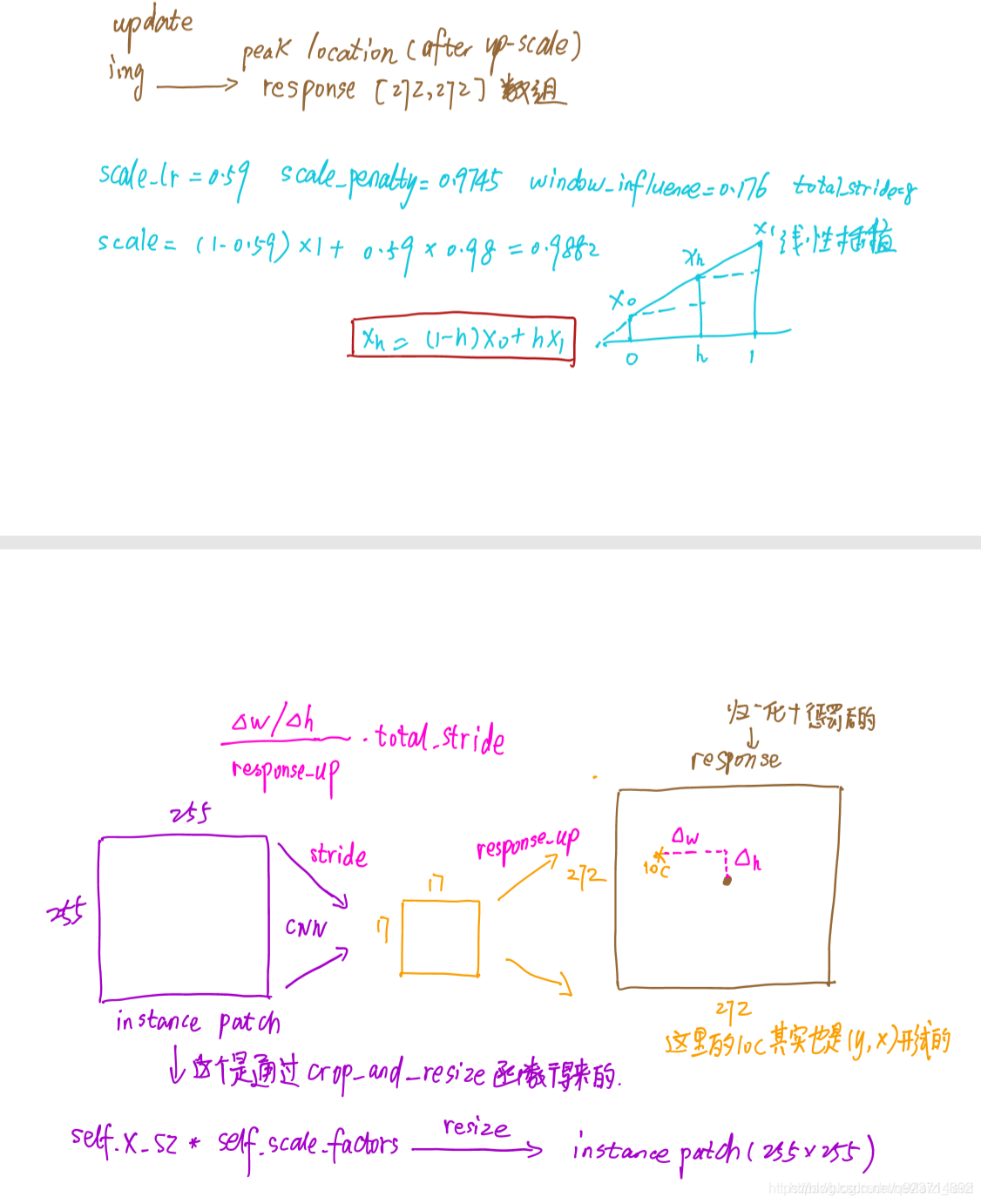
- 跟踪时直接对score map进行线性插值,将1717的score map扩大为272272,这样原来score map中响应值最大的点映射回272*272目标位置。
- 对训练的数据库中数据进行一些处理
- 扔掉一些类别: snake,train,whale,lizard 等,因为这些物体经常仅仅出现身体的某一部分,且常在图像边缘出现;
- 排除太大 或者 太小的物体;
- 排除离边界很近的物体。
SiamFC完整的跟踪过程
参考:SiamFC完整的跟踪过程
-
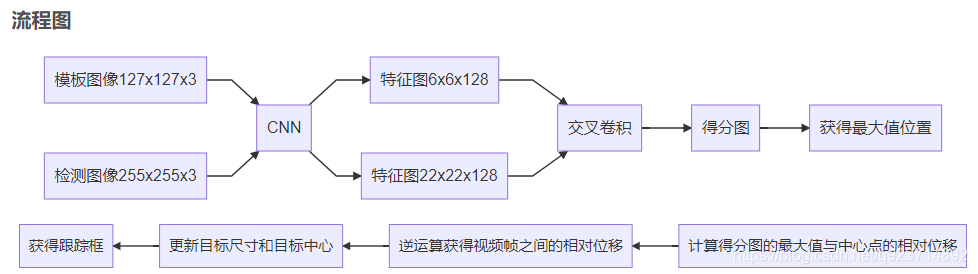
准备两路输入图像:模板图像和检测图像。
-
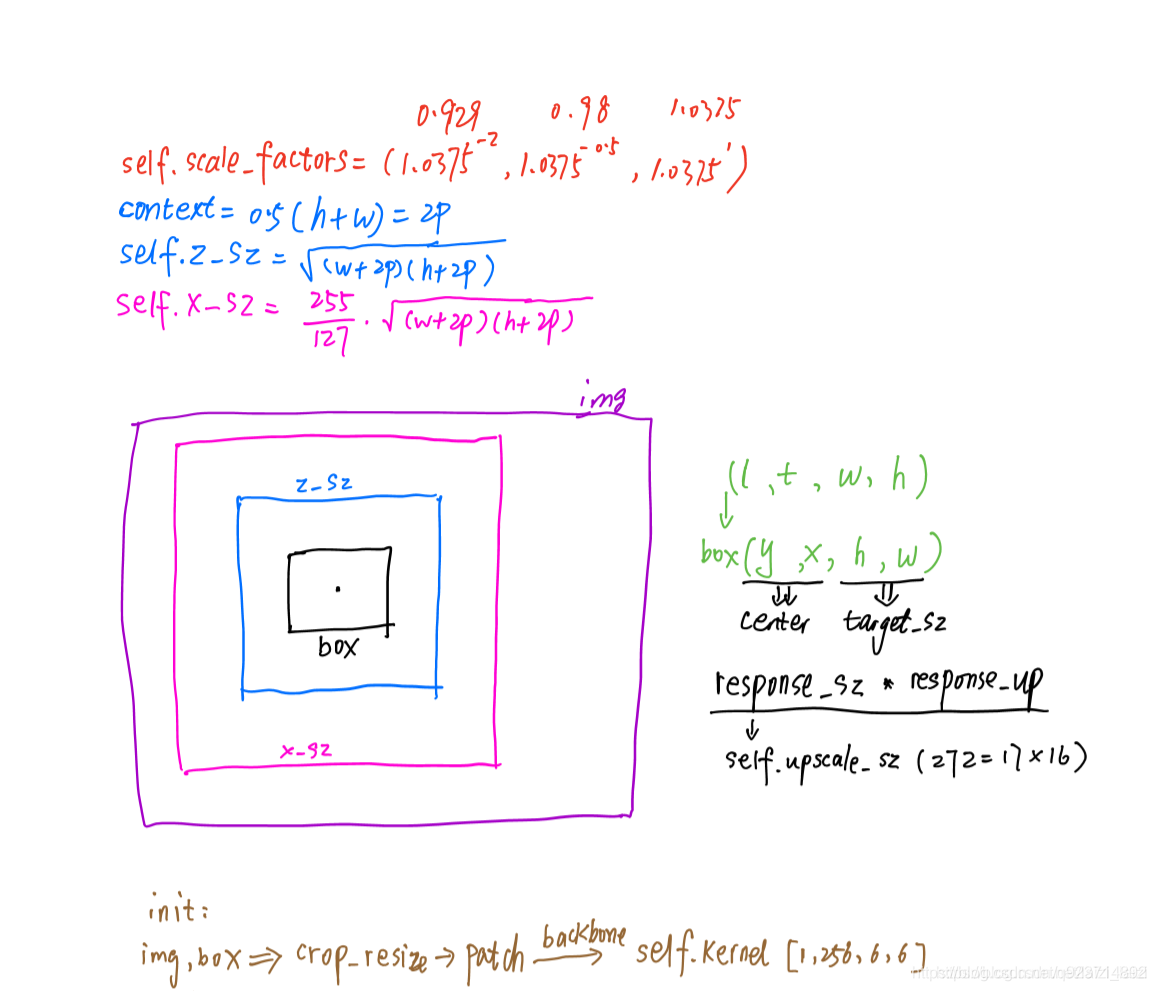
设置模板图像和检测图像的边长,分别用z_sz和x_sz表示。
-
设置content,前后文信息

即
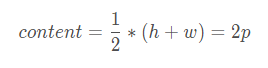
-
设置z_sz = sqrt(Az)

即
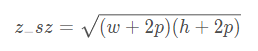
-
设置x_sz=sqrt(Ax)
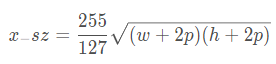
-
-
对模板图像而言:在第一帧以z_sz为边长,以目标中心为中心点,截取图像补丁(如果超出第一帧的尺寸,用均值填充)。之后将其resize为127x127x3.成为模板图像
-
对检测图像而言:在第二帧及以后,分别以x_sz*1.0375^{[-2,-0.5,1]}为边长,以前一帧目标中心为中心点,截取图像补丁(如果超出第一帧的尺寸,用均值填充)。之后将三个图像补丁都resize为255x255x3.成为检测图像
-
-
将模板图像和检测图像输入CNN网络中,分别得到6x6x128和22x22x128的特征图。
-
最后使用交叉相关,将模板图像的特征图当做卷积核,对检测图像的特征进行滑窗检测,最后得到3x1x17x17的得分图(三个尺度)。交叉函数如下所示:
f(x,z)=φ(z)∗φ(x)+bi -
使用双三次线性插值生成277x277的图像: 3x277x277.
-
获得三个得分图中最大值的位置(x,y)。
-
获得最大值位置与上一帧目标中心的相对位移。
-
因为之前是crop,再resize得到检测图像,之后CNN(包含交叉卷积)得到得分图,最后上采样得到[3,277,277]。所以将第(6)步得到的相对位移进行逆运算,最终获得视频帧之间的相对位移。
-
根据相对位移更新目标的中心点。
-
获得目标尺寸变换的比例(最大值所在的尺度(三个尺度中的一个)):
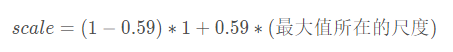
- 更新目标尺寸:target_sz*scale
- 更新x_sz:x_sz*scale
- 更新z_sz:z_sz*scale
-
画出跟踪框。
这是我详细debug的记录:里面也有对其的一些理解:

论文的思考与优化
SiameseFC的优点:
1、实时性(>24帧/s):
SiamFC-3s FPS : 86帧/s
SiamFC-5s FPS : 58帧/s
该网络把跟踪任务转换成一个模板匹配的问题而不是一个常见的二分类问题,整个跟踪过程中不需要更新模板,使得算法的速度大幅度提高。这也是深度学习领域神经网络在目标跟踪一直以来难以到达的一个关键点,直到孪生网络应用于目标跟踪使得在跟踪精度较高的条件下还达到了实时性,在深度学习领域不愧为重大的突破,继此网络后,基于此网络为基本框架的目标跟踪算法层出不尽并且精度、速度能达到一个兼顾,占据深度学习应用在目标跟踪中的主流方向。
2、小范围晃动
对于小范围晃动,背景信息变化不大使得模板匹配的结果较好

3、运动模糊

4、短时局部遮挡
模板匹配对短暂性局部遮挡处理较好

SiameseFC的不足:(Siamese一直有鲁棒性不好的问题)
SiameseFC是一个模板匹配的任务,在跟踪过程中并不更新目标模板和网络权值,这造成如下问题:
(1)当目标发生较大的形变时,会造成目标候选框与目标模板出现较大差异,从而导致跟踪失败。网络权值不更新导致要使用同一套网络结构和网络参数适应所有的跟踪场景,这是很难做到的。
(2)对于没有处于复杂背景下的跟踪来说,该算法能基本平衡实时性与准确性要求,但是跟踪目标一旦发生遮挡、快速运动、相似外观,搜索图像的大小可能就覆盖不了目标,通过最后的相似性度量函数得出来的结果就是错误的,随着跟踪过程中发生的错误累加,导致跟踪不可恢复,所以孪生结构网络的跟踪性能在背景复杂的情况下会下降。



失败原因:
-
目标特征不够具体、突出、全面 (AlexNet提取特征不够细致)
-
没能利用好空间信息、运动信息 (运动模型不够合理)
-
搜索域方法的局限性 (多尺度增加计算量,无法适应尺度变化)
-
匹配与分类的本质差别 (分类对背景前景区分较好)
解决思路:
-
加入在线更新的策略(增加目标信息,牺牲速度或者增强特征的提取)
-
需要对首帧标注图像做处理(抑制背景信息,增加前景和背景的区分度)
SiamFC选用第一帧作为模板并不予更新,因此首帧目标信息为关键信息,而SiamFC模型中,最后采用相似度学习,如果不能降模板图像中背景信息的干扰,则必然会对结果造成影响。 因此应当对标注图像进行进一步的目标提取,并对背景信息进行抑制。 -
利用空间信息,估计运动模型
在存在较多相似目标的场景中,可能特征匹配难以准确地判断哪个才是真正的目标。而人在这种场景下追踪目标的策略往往是根据
(1)目标的空间信息,例如一队人中的第几个,或者目标周围有哪些参照物。这一点可以通过对目标旁边的背景进行建模实现。
(2)根据目标的运动轨迹进行预测,因为目标的变化(无论是位置还是外观)在序列中往往是连续可微的。
论文代码解读
这里主要参考:siamfc-pytorch代码讲解(三):demo&track
更简洁的请参考:【SOT】siameseFC论文和代码解析讲的也很棒~
训练阶段:
1.backbones.py分析
功能分析:
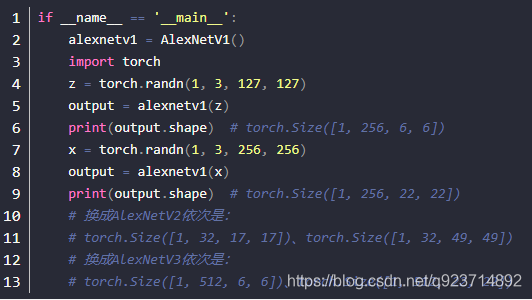
这个module主要实现了3个AlexNet版本作为backbone,开头的__all__ = [‘AlexNetV1’, ‘AlexNetV2’, ‘AlexNetV3’]主要是为了让别的module导入这个backbones.py的东西时,只能导入__all__后面的部分。
后面就是三个类AlexNetV1、AlexNetV2、AlexNetV3,他们都集成了类_AlexNet,所以他们都是使用同样的forward函数,依次通过五个卷积层,每个卷积层使用nn.Sequential()堆叠,只是他们各自的total_stride和具体每层卷积层实现稍有不同(当然跟原本的AlexNet还是有些差别的,比如通道数上):
AlexNetV1和AlexNetV2:
共同点:conv2、conv4、conv5这几层都用了groups=2的分组卷积,这跟原来的AlexNet会更接近一点
不同点:conv2中的MaxPool2d的stride不一样大,conv5层的输出通道数不一样
AlexNetV1和AlexNetV3:前两层的MaxPool2d是一样的,但是中间层的卷积层输入输出通道都不一样,最后的输出通道也不一样,AlexNetV3最后输出经过了BN
AlexNetV2和AlexNetV3:conv2中的MaxPool2d的stride不一样,AlexNetV2最后输出通道数小很多。
其实感觉即使有这些区别,但是这并不是很重要,这一部分也是整体当中容易理解的,所以不必太去纠结为什么不一样,最后作者用的是AlexNetV1,论文中是这样的结构,其实也就是AlexNetV1:

代码分析
1.def __init__(self, num_features, *args, **kwargs):中*args和**kwargs到底是什么
参考Python中*args、**args到底是什么、有啥区别、怎么用
*args的用法:当传入的参数个数未知,且不需要知道参数名称时。
**args的用法:当传入的参数个数未知,但需要知道参数的名称时(立马想到了字典,即键值对)
也就是说**args在输入的时候一般是键值对,而*args任意。
注意:这里的args不是必须的,也就是说可以换成kwargs等等,但是星号是必须的。
2.BatchNorm2d函数分析:
参考:BatchNorm2d原理、作用及其pytorch中BatchNorm2d函数的参数讲解
例如BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- num_features:一般输入参数为batch_sizenum_featuresheight*width,即为其中特征的数量,即为输入BN层的通道数;
- eps:分母中添加的一个值,目的是为了计算的稳定性,默认为:1e-5,避免分母为0;
- momentum:一个用于运行过程中均值和方差的一个估计参数(我的理解是一个稳定系数,类似于SGD中的momentum的系数);
- affine:当设为true时,会给定可以学习的系数矩阵gamma和beta



3.nn.ReLU(inplace=True)代码分析
参考:PyTorch------nn.ReLU(inplace = True)详解
inplace = False 时,不会修改输入对象的值,而是返回一个新创建的对象,所以打印出对象存储地址不同,类似于C语言的值传递
inplace = True 时,会修改输入对象的值,所以打印出对象存储地址相同,类似于C语言的址传递
即当inplace = True 时,在原地改变值而不是赋予新值。
4.output stride = 4解析:
output stride为该矩阵经过多次卷积pooling操作后,尺寸缩小的值(这个还保留疑问)
5.__all__ = ['AlexNetV1', 'AlexNetV2', 'AlexNetV3']中__all__解析
参考:python中【all】的用法
__all__是一个字符串list,用来定义模块中对于from XXX import 时要对外导出的符号,即要暴露的接口,但它只对import *起作用,对from XXX import XXX不起作用。
控制 from xxx import * 的行为
6.nn.Conv2d(384, 32, 3, 1, groups=2))这个groups=2
这个groups=2,是将卷积分为两组:
2.heads.py分析
from __future__ import absolute_importimport torch.nn as nn
import torch.nn.functional as F__all__ = ['SiamFC']class SiamFC(nn.Module):def __init__(self, out_scale=0.001):super(SiamFC, self).__init__()self.out_scale = out_scaledef forward(self, z, x):return self._fast_xcorr(z, x) * self.out_scaledef _fast_xcorr(self, z, x):# fast cross correlation# x size 8,256,20,20# z size 8,256,6,6nz = z.size(0) #size(0)即取第一个shape值#nz = 8nx, c, h, w = x.size()#nx = 8,c = 256,h = 20,w = 20x = x.view(-1, nz * c, h, w)#x.shape = [1,2048,20,20]out = F.conv2d(x, z, groups=nz)# out.shape = [1,8,15,15]#输入是4维,输出也是4维,高层补1# print(out.size())out = out.view(nx, -1, out.size(-2), out.size(-1))# out.shape = [8,1,15,15]return out功能分析:
为什么这里会有个out_scale,根据作者说是因为, z zz和x xx互相关之后的值太大,经过sigmoid函数之后会使值处于梯度饱和的那块,梯度太小,乘以out_scale就是为了避免这个。
重点:nn.conv2d和nn.function2d解析
_fast_xcorr函数中最关键的部分就是F.conv2d函数了,可以通过官网查询到用法:
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) → Tensor
input – input tensor of shape (\text{minibatch} , \text{in_channels} , iH , iW)(minibatch,in_channels,iH,iW)
weight – filters of shape (\text{out_channels} , \frac{\text{in_channels}}{\text{groups}} , kH , kW)(out_channels, groups in_channels ,kH,kW)
bias – optional bias tensor of shape (\text{out_channels})(out_channels). Default: None
stride – the stride of the convolving kernel. Can be a single number or a tuple (sH, sW). Default: 1
padding –implicit paddings on both sides of the input. Can be a string {‘valid’, ‘same’}, single number or a tuple (padH, padW). Default: 0 padding=‘valid’ is the same as no padding. padding=‘same’ pads the input so the output has the shape as the input. However, this mode doesn’t support any stride values other than 1.
这里nn.Con2d要与nn.function.conv2d区分开:
参考:pytorch中nn.Conv2d和nn.function.conv2d的区别
- nn.Conv2d
torch.nn.Conv2d(in_channels,out_channels,kernel_size,stride=1,padding=0,dilation=1,groups=1,bias=True,padding_mode=‘zeros’)
in_channels-----输入通道数
out_channels-------输出通道数
kernel_size--------卷积核大小
stride-------------步长
padding---------是否对输入数据填充0 - nn.function.conv2d
torch.nn.functional.conv2d(input,weight,bias=None,stride=1,padding=0,dilation=1,groups=1)
input-------输入tensor大小(minibatch,in_channels,iH, iW)
weight------权重大小(out_channels, in_channels/groups, kH, kW)
注意:权重参数中,第一个卷积核的输出通道数,第二个是输入通道数
这里针对nn.function.conv2d讨论
例如:torch.nn.functional.conv2d(self, input, weight, bias=None, stride=1, padding=0, dilation=1, groups=2)
input:
minibatch:batch中的样例个数
in_channels:每个样例数据的通道数
iH:每个样例的高(行数)
iW:每个样例的宽(列数)
weight(就是filter):
out_channels:卷积核的个数
in_channels/groups:每个卷积核的通道数
kH:每个卷积核的高(行数)
kW:每个卷积核的宽(列数)
groups作用:对input中的每个样例数据,将通道分为groups等份,即每个样例数据被分成了groups个大小为(in_channel/groups, iH, iW)的子数据。对于这每个子数据来说,卷积核的大小为(in_channel/groups, kH, kW)。这一整个样例数据的计算结果为各个子数据的卷积结果拼接所得。
举例:
import torch.nn.functional as F
inputs = torch.arange(1, 21).reshape(1, 2, 2, 5)
filters = torch.arange(1, 7).reshape(2, 1, 1, 3)
print(inputs)
print(filters)
res = F.conv2d(input=inputs, weight=filters, stride=(1, 1), groups=2)
print(res)
输出如下:
tensor([[[[ 1, 2, 3, 4, 5],[ 6, 7, 8, 9, 10]],[[11, 12, 13, 14, 15],[16, 17, 18, 19, 20]]]])tensor([[[[1, 2, 3]]],[[[4, 5, 6]]]])tensor([[[[ 14, 20, 26],[ 44, 50, 56]],[[182, 197, 212],[257, 272, 287]]]])
样例数据:
[ [ [ 1, 2, 3, 4, 5],[ 6, 7, 8, 9, 10] ],[ [11, 12, 13, 14, 15],[16, 17, 18, 19, 20] ] ]
被分成:
[ [ [ 1, 2, 3, 4, 5], [ [ [11, 12, 13, 14, 15],[ 6, 7, 8, 9, 10] ] ] 和 [16, 17, 18, 19, 20] ] ]
卷积核:
[ [ [ [ 1, 2, 3 ] ] ],[ [ [ 4, 5, 6 ] ] ] ]
被分成:
[ [ [1, 2, 3] ] ] 和 [ [4, 5, 6] ] ]
结果中:
[ [ 14, 20, 26],[ 44, 50, 56] ]
是
[ [ [ 1, 2, 3, 4, 5],[ 6, 7, 8, 9, 10] ] ] 和 [ [ [ 1, 2, 3 ] ] ] 卷积所得。
3.train.py分析
作者使用了GOT-10k这个工具箱,train.py代码非常少
具体可以参考官方文档:Downloads - GOT-10k
4.transforms.py分析
顺着代码流看到调用了siamfc.py中类TrackerSiamFC的train_over方法,在这个类里面就是进行数据增强,构造和加载,然后进行训练,这里先讨论transforms:
SiamFCTransforms是transforms.py里面的一个类,主要是对输入的groung truth的z, x, bbox_z, bbox_x进行一系列变换,构成孪生网络的输入,这其中就包括了:
RandomStretch:主要是随机的resize图片的大小,其中要注意cv2.resize()的一点用法,可以参考这篇博客:cv2.resize()的一点小坑
CenterCrop:从img中间抠一块(size, size)大小的patch,如果不够大,以图片均值进行pad之后再crop
RandomCrop:用法类似CenterCrop,只不过从随机的位置抠,没有pad的考虑
Compose:就是把一系列的transforms串起来
ToTensor: 就是字面意思,把np.ndarray转化成torch tensor类型
代码分析:
torch.from_numpy(img).float().permute((2, 0, 1))中permute(2,0,1)分析
参考:Pytorch之permute函数
permute(dims):将tensor的维度换位。
>>> x = torch.randn(2, 3, 5)
>>> x.size()
torch.Size([2, 3, 5])
>>> x.permute(2, 0, 1).size()
torch.Size([5, 2, 3])
if isinstance(size, numbers.Number):中isinstance分析
参考Python isinstance() 函数
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
在这里,isinstance是判断size是否为正常数。np.random.choice
参考:理解python中的random.choice()
random模块在python中起到的是生成随机数的作用,random模块中choice()可以从序列中获取一个随机元素,并返回一个(列表,元组或字符串中的)随机项。- 图像处理: 五种插值法
参考:图像处理: 五种 插值法
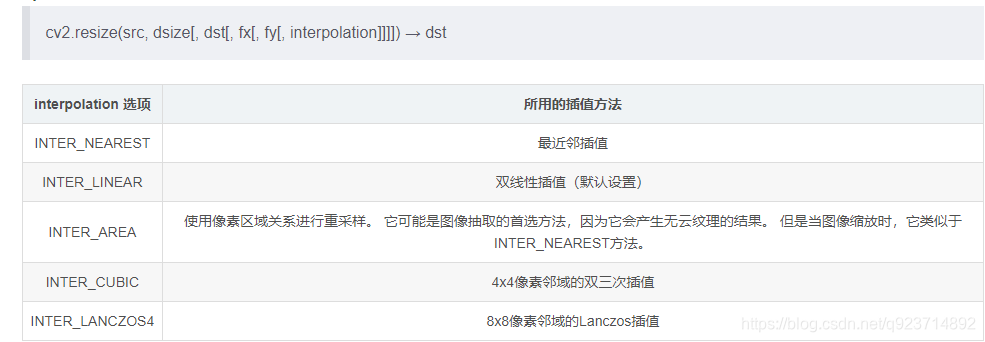
下面具体讲里面的_crop函数:
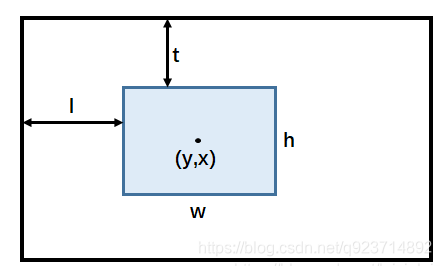
因为GOT-10k里面对于目标的bbox是以ltwh(即left, top, weight, height)形式给出的,上述代码一开始就先把输入的box变成center based,坐标形式变为[y, x, h, w],结合下面这幅图就非常好理解: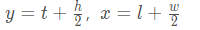
5.ops.py分析(train相关部分)
crop_and_resize

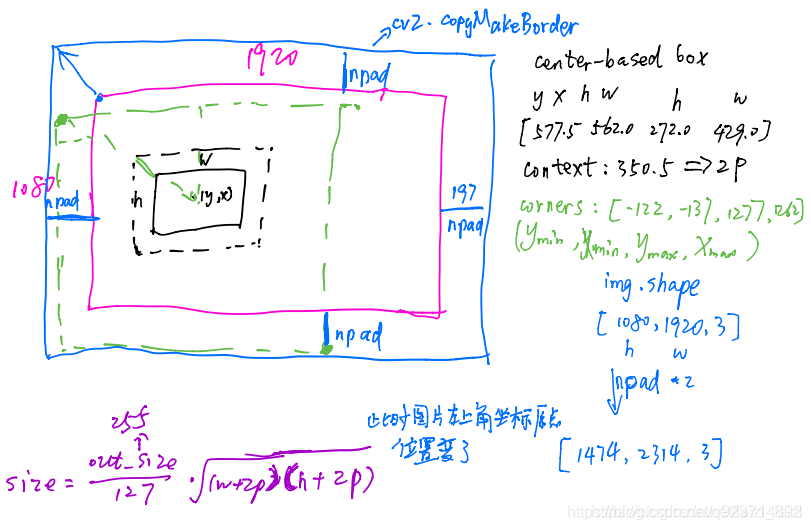
代码分析:
img = cv2.copyMakeBorder(img, npad, npad, npad,npad,border_type,value=border_value)
参考:OpenCV-Python: cv2.copyMakeBorder()函数详解

6.datasets.py
现在继续回到train_over方法,里面构造dataset的时候用了Pair类,所以从代码角度具体来看一下,因为继承了Dataset类,所以要overwrite __getitem__和__len__方法:
getitem:分析代码,这个方法就是通过index索引返回item = (z, x, box_z, box_x),然后经过transforms返回一对pair(z, x),就需要像论文里面说的:The images are extracted from two frames of a video that both contain the object and are at most T frames apart 。
_filter:通过该函数筛选符合条件的有效索引val_indices,这里不详细分析,因为我也不知道为什么会有这样的filter condition。
_sample_pair:如果有效索引大于2个的话,就从中随机挑选两个索引,这里取的间隔不超过T=100
len:这里定义的长度就是被索引到的视频序列帧数×每个序列提供的对数
7.siamfc.py分析(重点:train相关部分)
train_step
现在来到siamfc.py里面最后一个关键的地方,数据准备好了,经过变换和加载进来就可以训练了,下面代码是常规操作,具体在train_step里面实现了训练和反向传播:
而train_step里面难度又是在于理解_create_labels,具体的一些tensor的shape可以看我的注释,我好奇就把他打印出来了,看来本来__getitem__返回一对pair(z, x),经过dataloader的加载,还是z堆叠一起,x堆叠一起,并不是(z, x)绑定堆叠一起
而且criterion使用的BalancedLoss,是调用F.binary_cross_entropy_with_logits,进行一个element-wise的交叉熵计算,所以创建出来的labels的shape其实就是和responses的shape是一样的:
创建标签,论文里是这么说的:
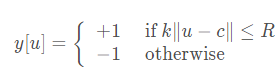
因为我们的exemplar image z zz 和search image x xx都是以目标为中心的,所以labels的中心为1,中心以外为0。
对于np.tile、np.meshgrid、np.where函数的使用:
参考:np.tile、np.meshgrid、np.where学习总结
最后出来的一个batch下某一个通道下的label就是下面这样的:

还有train_over部分,就是保存模型,没什么说的。
tracking部分:
现在就来看一下类TrackerSiamFC下的track方法。这个函数的作用就是传入video sequence和first frame中的ground truth bbox,然后通过模型,得到后续帧的目标位置,可以看到主要有两个函数实现:init和update,这也是继承Tracker需要重写的两个方法:
siamfc.py(tracking部分)
init(self, img, box):
init:就是传入第一帧的标签和图片,初始化一些参数,计算一些之后搜索区域的中心等等

update:
update:就是传入后续帧,然后根据SiamFC网络返回目标的box坐标,之后就是根据这些坐标来show,起到一个demo的效果。

补充一些函数:
1.getatter():
参考:Python getatter() 通过方法名字符串调用方法
getattr()这个方法最主要的作用是实现反射机制。也就是说可以通过字符串获取方法实例。
获取函数/属性/从模块获取类
2.enumerate()
参考:python中enumerate()函数的用法
enumerate(sequence, start=0),返回一个枚举对象。sequence必须是序列或迭代器iterator,或者支持迭代的对象。enumerate()返回对象的每个元素都是一个元组,每个元组包括两个值,一个是计数,一个是sequence的值,计数是从start开始的,start默认为0。
论文翻译+解读
Abstract

1 Introduction

2 Deep Similarity Learning for Tracking
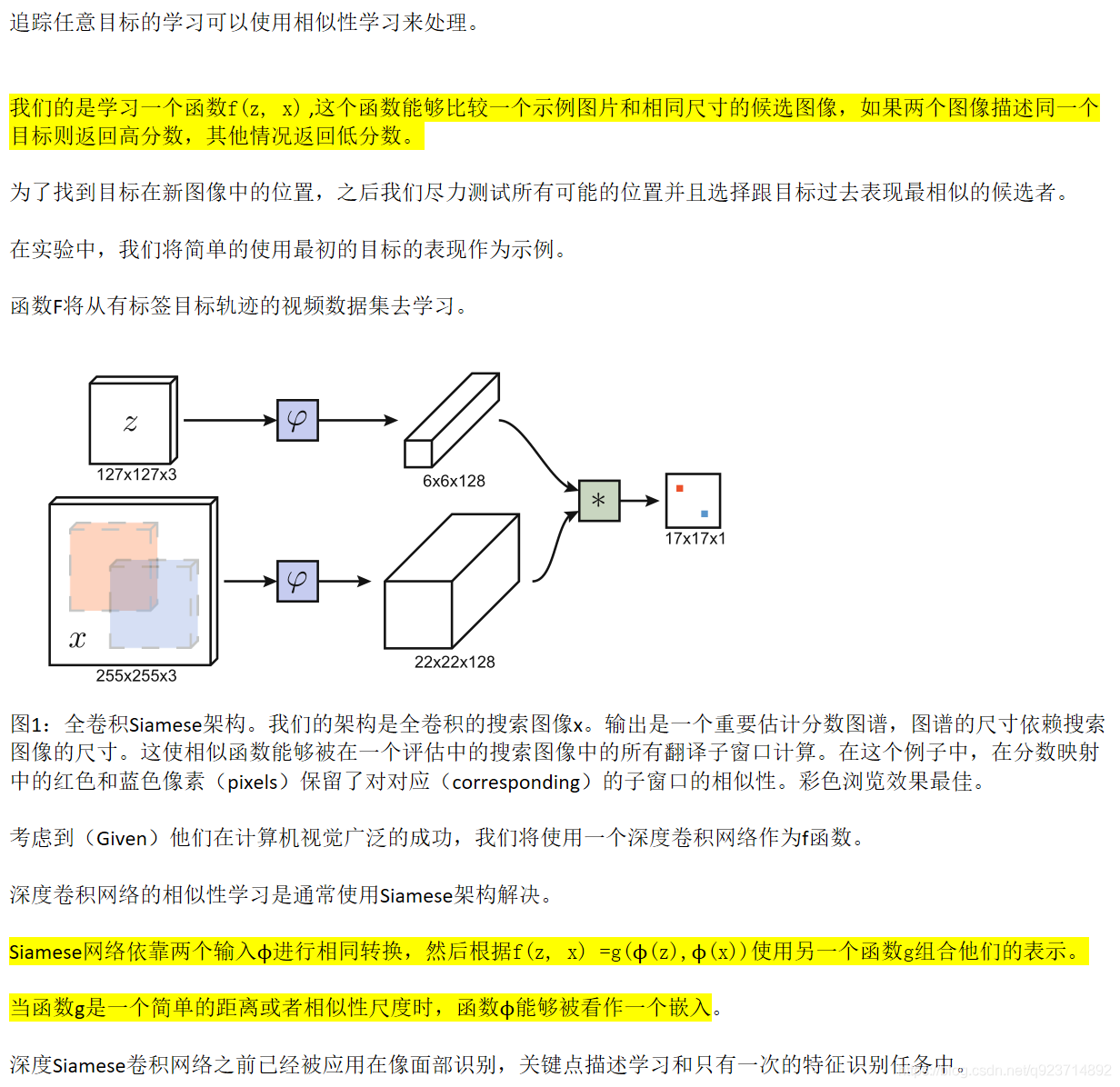
全卷积在我另一篇文章有一个简单的分析:FCN全卷积网络随笔
2.1 Fully-Convolutional Siamese Architecture

这里讲解一下:
The position of the maximum score relative to the centre of the score map, multiplied by the stride of the network, gives the displacemen of the target from frame to frame.
我们假设有三个帧,第二帧的中心截取是按照第一帧的目标位置来截取的,如果要进行第三帧的中心截取,那我们需要按照第二帧对于第一帧的相对位移,来获取第三帧的截取位置–也就是帧与帧之间的位移.网络步长是指缩小的倍数.再经过一系列的卷积层之后,图像缩小了一定的倍数,这个倍数就是网络步长.当我们得到第二帧的map中目标点位置时,要与网络步长相乘,就能知道第二帧目标相对第一帧的目标位移,第三帧就通过这个位移来进行中心截取.
2.2 Training with Large Search Images

2.3 ImageNet Video for Tracking

2.4 Practical Considerations

这里来讲解一下这个公式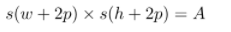
实际上,s是缩小的倍数,(h,w)是指长宽,而p是指边框厚度,其结果A就是面积

3 Related Work

4 Experiments
4.1 Implementation Details

双三插值的理解请看这个:插值(五)Bicubic interpolation(双三次插值)
4.2 Evaluation

4.3 The OTB-13 Benchmark
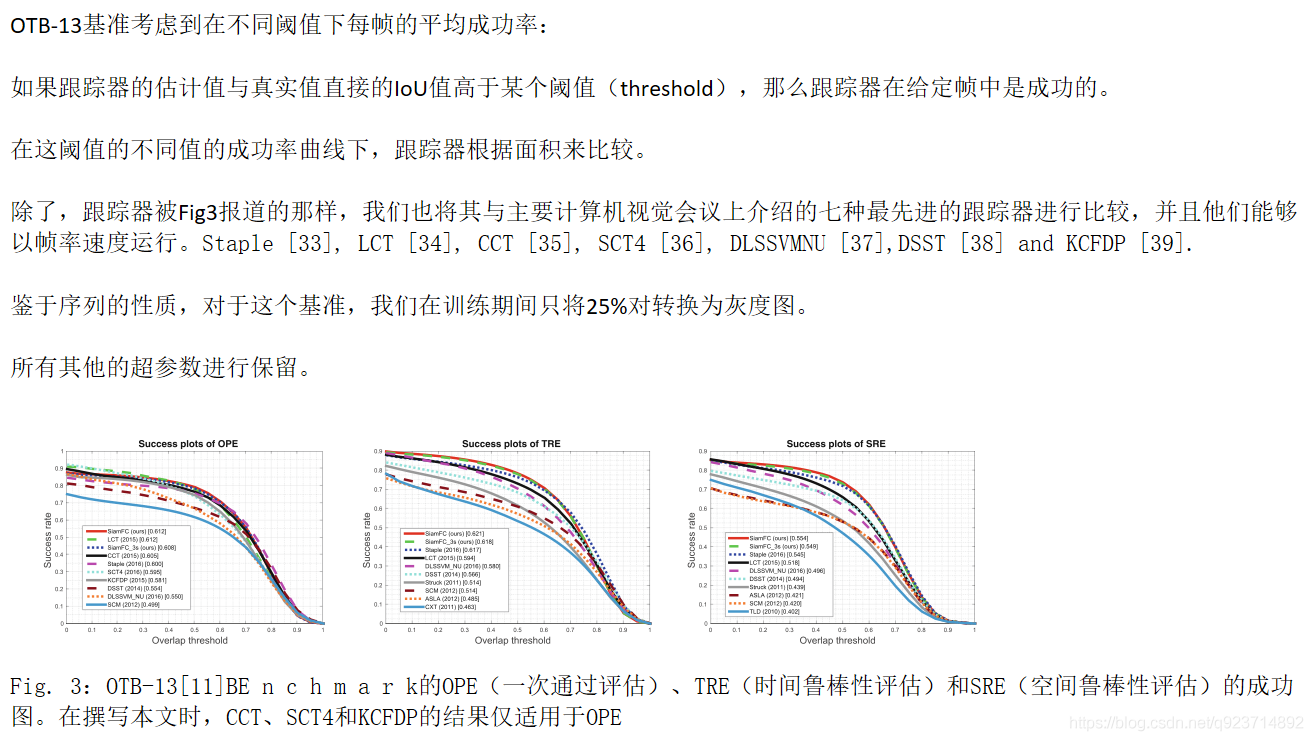
4.4 The VOT Benchmarks

4.5 Dataset Size

5 Conclusion