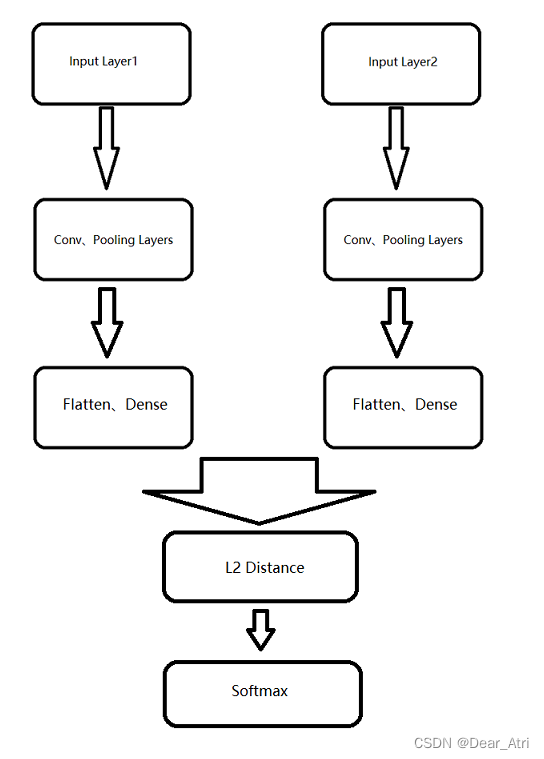
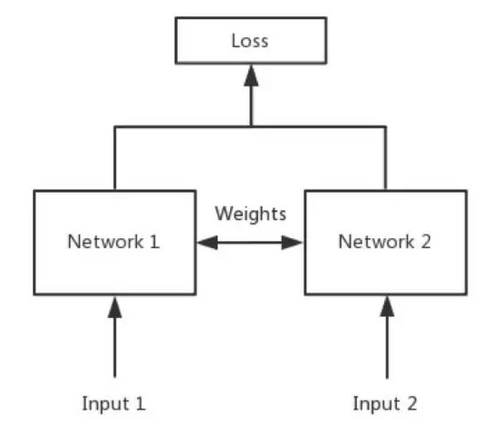
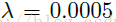最近在研究Siamese模型来进行文本相似度的计算,今天就做一期代码详解,每一行的代码都会做出相应的解释,对于初学LSTM的人来说读懂代码是非常有必要的,Siamese模型就是将两个句子(训练数据)通过embeding层(word2vec)分别输入到LSTM进行运算,并共享参数,利用损失函数不断的进行正向传播和反向传播来优化参数,最终达到成为一个比较优秀的模型
原理就不在细说了,这里主要是把代码解释一下
(1)数据处理部分
首先是数据预处理部分:这里主要分为“读取数据“,“调整数据格式”和“对于batch 的设置”
读取数据
将数据通过pickle工具读取出来,因为pickle序列化和反序列化的工具,可以持久化储存数据格式,将数据读取出来后,分成句子和标签,匹配句子中的每一个单词对应的wor2dvec(词向量)最后返回数据和标签
def load_set(embed, datapath, embed_dim):#使用pickle读取数据with open(datapath, 'rb') as f:mylist = pkl.load(f,encoding="utf-8")#初始化句子和标签s0 = []s1 = []labels = []#将句子一句一句的读取出来for each in mylist:#句子一s0x = each[0]#句子二s1x = each[1]#标签label = each[2]#将标签转化为float类型的score = float(label)#存入标签labels.append(score)#将句子中的每一个单词读取出来for i, ss in enumerate([s0x, s1x]):#将句子分成一个个的单词words = word_tokenize(ss)index = []for word in words:#如果单词存在词典中,将该词对应的词向量存入index中if word in dtr:index.append(embed[dtr[word]])#如果单词没有存在词典,而是在embed中,将对应的词向量存入index中elif word in embed.vocab:index.append(embed[word])#否则将该词屏蔽掉(设置为0)else:index.append(np.zeros(embed_dim, dtype=float))#i=0 表示的是s0的数据,将s0的embed存入if i == 0:s0.append(np.array(index, dtype=float))# 1=0 表示的是s1的数据,将s1的embed存入(embed表示的是对应的词向量)else:s1.append(np.array(index, dtype=float))#返回标签和数据return [s0, s1, labels]
调整数据格式
将数据取出来打散,这是为了提升模型的泛化能力,将数据格式统一,由于句子的长短不一,因此进行特殊化处理,保证是句子数据格式一样,设置最大长度的句子,如果句子的长度小于最大长度,末尾表示0,
# 从文件中读取数据集,并分为训练、验证和测试集合
def load_data(max_len, embed, datapath, embed_dim):#读取数据train_set = load_set(embed, datapath, embed_dim)#将数据分为句子1、句子2和标签train_set_x1, train_set_x2, train_set_y = train_set# n_samples表示句数据的个数n_samples = len(train_set_x1)# 打散数据集(permutation是最常用的打散数据集的方式,可以保障数据和标签不混乱)sidx = np.random.permutation(n_samples)train_set_x1 = [train_set_x1[s] for s in sidx]train_set_x2 = [train_set_x2[s] for s in sidx]train_set_y = [train_set_y[s] for s in sidx]# 打散划分好的训练和测试集train_set = [train_set_x1, train_set_x2, train_set_y]# 创建用于存放训练、测试和验证集的矩阵#max_len 表示句子长度# embed_dim表示的是词向量的维度# len(train_set[0])表示的是句子的个数new_train_set_x1 = np.zeros([len(train_set[0]), max_len, embed_dim], dtype=float)new_train_set_x2 = np.zeros([len(train_set[0]), max_len, embed_dim], dtype=float)new_train_set_y = np.zeros(len(train_set[0]), dtype=float)mask_train_x1 = np.zeros([len(train_set[0]), max_len])mask_train_x2 = np.zeros([len(train_set[0]), max_len])#匹配数据矩阵,大于最大长度的删掉,小于的补零def padding_and_generate_mask(x1, x2, y, new_x1, new_x2, new_y, new_mask_x1, new_mask_x2):for i, (x1, x2, y) in enumerate(zip(x1, x2, y)):# whether to remove sentences with length larger than maxlen#如果句子一小于最大长度if len(x1) <= max_len:#前面放数据后面补零new_x1[i, 0:len(x1)] = x1# 将句子的最后一个词赋值为1,表示句子的结尾new_mask_x1[i, len(x1) - 1] = 1#标签数据不变new_y[i] = yelse:#只保留前max-len的值 ::??new_x1[i, :, :] = (x1[0:max_len:embed_dim])#最后一个就是句子结尾new_mask_x1[i, max_len - 1] = 1#标签数据不用变new_y[i] = y#和x1表示的一样if len(x2) <= max_len:new_x2[i, 0:len(x2)] = x2new_mask_x2[i, len(x2) - 1] = 1 # 标记句子的结尾new_y[i] = yelse:new_x2[i, :, :] = (x2[0:max_len:embed_dim])new_mask_x2[i, max_len - 1] = 1new_y[i] = y#返回新的值new_set = [new_x1, new_x2, new_y, new_mask_x1, new_mask_x2]del new_x1, new_x2, new_yreturn new_set#将数据规格化train_set = padding_and_generate_mask(train_set[0], train_set[1], train_set[2], new_train_set_x1, new_train_set_x2,new_train_set_y, mask_train_x1, mask_train_x2)return train_set
batch 的设置
对batch的处理,也就是将数据拆分成batch个,由yiled形成一个batch大小的数据生成器。
def batch_iter(data, batch_size):# get dataset and label#获得数据以及标签x1, x2, y, mask_x1, mask_x2 = datax1 = np.array(x1)x2 = np.array(x2)y = np.array(y)data_size = len(x1)#batch的个数计算,也就是总数据/batch的大小num_batches_per_epoch = int((data_size - 1) / batch_size) + 1#每一个batch进行数据切分for batch_index in range(num_batches_per_epoch):#一开始切的数据位置start_index = batch_index * batch_size#结束位置end_index = min((batch_index + 1) * batch_size, data_size)#按照开始位置和结束位置进行数据和标签的切片return_x1 = x1[start_index:end_index]return_x2 = x2[start_index:end_index]return_y = y[start_index:end_index]return_mask_x1 = mask_x1[start_index:end_index]return_mask_x2 = mask_x2[start_index:end_index]yield [return_x1, return_x2, return_y, return_mask_x1, return_mask_x2](2)训练部分
参数的设置
参数使用flags设置的包括batch的大小,学习率等等
import numpy as np
import os
import time
from lstmRNN import LSTMRNN
import data_helper
from gensim.models import KeyedVectors
from scipy.stats import pearsonr
import tensorflow as tf
flags = tf.app.flags
FLAGS = flags.FLAGS
#参数的设置
flags.DEFINE_integer('batch_size', 32, 'the batch_size of the training procedure')
flags.DEFINE_float('lr', 0.0001, 'the learning rate')
flags.DEFINE_float('lr_decay', 0.95, 'the learning rate decay')
flags.DEFINE_integer('emdedding_dim', 300, 'embedding dim')
flags.DEFINE_integer('hidden_neural_size', 50, 'LSTM hidden neural size')
flags.DEFINE_integer('max_len', 73, 'max_len of training sentence')
flags.DEFINE_integer('valid_num', 100, 'epoch num of validation')
flags.DEFINE_integer('checkpoint_num', 1000, 'epoch num of checkpoint')
flags.DEFINE_float('init_scale', 0.1, 'init scale')flags.DEFINE_float('keep_prob', 0.5, 'dropout rate')
flags.DEFINE_integer('num_epoch', 360, 'num epoch')
flags.DEFINE_integer('max_decay_epoch', 100, 'num epoch')
flags.DEFINE_integer('max_grad_norm', 5, 'max_grad_norm')
flags.DEFINE_string('out_dir', os.path.abspath(os.path.join(os.path.curdir, "runs_new1")), 'output directory')
flags.DEFINE_integer('check_point_every', 20, 'checkpoint every num epoch ')#参数的设置
class Config(object):#读取参数hidden_neural_size = FLAGS.hidden_neural_sizeembed_dim = FLAGS.emdedding_dimkeep_prob = FLAGS.keep_problr = FLAGS.lrlr_decay = FLAGS.lr_decaybatch_size = FLAGS.batch_sizenum_step = FLAGS.max_lenmax_grad_norm = FLAGS.max_grad_normnum_epoch = FLAGS.num_epochmax_decay_epoch = FLAGS.max_decay_epochvalid_num = FLAGS.valid_numout_dir = FLAGS.out_dircheckpoint_every = FLAGS.check_point_every将数据切分成验证集和数据集
将训练数据切分成验证数据集,和训练数据集,也就是将训练集根据比例切出来一部分作为验证集
def cut_data(data, rate):#数据的获取x1, x2, y, mask_x1, mask_x2 = datan_samples = len(x1)# 打散数据集sidx = np.random.permutation(n_samples)#计算训练集和验证集的标签ntrain = int(np.round(n_samples * (1.0 - rate)))#对数据进行切片,分为训练集和验证集# 计算训练集数据train_x1 = [x1[s] for s in sidx[:ntrain]]train_x2 = [x2[s] for s in sidx[:ntrain]]train_y = [y[s] for s in sidx[:ntrain]]train_m1 = [mask_x1[s] for s in sidx[:ntrain]]train_m2 = [mask_x2[s] for s in sidx[:ntrain]]#计算验证集数据valid_x1 = [x1[s] for s in sidx[ntrain:]]valid_x2 = [x2[s] for s in sidx[ntrain:]]valid_y = [y[s] for s in sidx[ntrain:]]valid_m1 = [mask_x1[s] for s in sidx[ntrain:]]valid_m2 = [mask_x2[s] for s in sidx[ntrain:]]# 打散划分好的训练和测试集train_data = [train_x1, train_x2, train_y, train_m1, train_m2]valid_data = [valid_x1, valid_x2, valid_y, valid_m1, valid_m2]return train_data, valid_data验证集的训练方法
这个方法表示的是把验证集的数据和参数传递给模型,由模型来进行运算返回模型的验证集计算结果。
def evaluate(model, session, data, global_steps=None, summary_writer=None):#获取数据x1, x2, y, mask_x1, mask_x2 = data#传递参数以及数据fetches = [model.truecost, model.sim, model.target]feed_dict = {}feed_dict[model.input_data_s1] = x1feed_dict[model.input_data_s2] = x2feed_dict[model.target] = yfeed_dict[model.mask_s1] = mask_x1feed_dict[model.mask_s2] = mask_x2feed_dict[model.batch_size1] = len(x1)#更新batch_size的大小#model.assign_new_batch_size(session, len(x1))#获得结果cost, sim, target = session.run(fetches, feed_dict)#计算相似度pearson_r = pearsonr(sim, target)pearson_r = tf.reduce_mean(pearson_r, name='pearson_r')#将结果可视化dev_summary = tf.summary.scalar('dev_pearson_r', pearson_r)#更新dev_summary = session.run(dev_summary)if summary_writer:# 保存summary_writer.add_summary(dev_summary, global_steps)summary_writer.flush()return cost, pearson_r
每个epoch的训练
表示每个epoch的 首先传递训练数据和参数,传递完成后使用模型进行训练,返回训练结果并且每一百步都进行验证集的运算。
def run_epoch(model, session, data, global_steps, valid_model, valid_data, train_summary_writer,valid_summary_writer=None):#利用yield生成器将数据拆成batch使用for step, (s1, s2, y, mask_s1, mask_s2) in enumerate(data_helper.batch_iter(data, batch_size=FLAGS.batch_size)):#将数据传递过去feed_dict = {}feed_dict[model.input_data_s1] = s1feed_dict[model.input_data_s2] = s2feed_dict[model.target] = yfeed_dict[model.mask_s1] = mask_s1feed_dict[model.mask_s2] = mask_s2feed_dict[model.batch_size1] = len(s1)#更新batch_size#model.assign_new_batch_size(session, len(s1))fetches = [model.truecost, model.sim, model.target, model.train_op, model.summary]#运行并计算结果cost, sim, target, _, summary = session.run(fetches, feed_dict)# 计算相关度pearson_r = pearsonr(sim, target)#保存训练步数和训练方法train_summary_writer.add_summary(summary, global_steps)#刷新train_summary_writer.flush()#每一百步使用验证集验证一次if (global_steps % 100 == 0):valid_cost, valid_pearson_r = evaluate(valid_model, session, valid_data, global_steps,valid_summary_writer)#打印结果print("the",global_steps,"step train cost is:",cost," and the train pearson_r is ",pearson_r," and the valid cost is ",valid_cost," the valid pearson_r is ",valid_pearson_r)#步长加一global_steps += 1return global_steps
开始准备训练
开始训练,对模型进行初始化,传递模型所需要的参数,创建可视化信息和检查点,读入word2vec模型、训练数据和测试数据。最后调用epoch方法进行运算。
def train_step():
#传递参数config = Config()eval_config = Config()eval_config.keep_prob = 1.0# gpu_config=tf.ConfigProto()# gpu_config.gpu_options.allow_growth=True
#使用默认的图with tf.Graph().as_default(), tf.Session() as session:# 这个初始化不好,效果极差,参数的初始化initializer = tf.random_normal_initializer(0.0, 0.2, dtype=tf.float32)#使用variable_scope函数实现权重共享with tf.variable_scope("model", reuse=None, initializer=initializer):#传递参数调用LSTM模型model = LSTMRNN(config=config, sess=session, is_training=True)with tf.variable_scope("model", reuse=True, initializer=initializer):valid_model = LSTMRNN(config=eval_config, sess=session, is_training=False)test_model = LSTMRNN(config=eval_config, sess=session, is_training=False)#保存可视化信息add summarytrain_summary_dir = os.path.join(config.out_dir, "summaries", "train")train_summary_writer = tf.summary.FileWriter(train_summary_dir, session.graph)dev_summary_dir = os.path.join(eval_config.out_dir, "summaries", "dev")dev_summary_writer = tf.summary.FileWriter(dev_summary_dir, session.graph)# 增加检查点checkpoint_dir = os.path.abspath(os.path.join(config.out_dir, "checkpoints"))checkpoint_prefix = os.path.join(checkpoint_dir, "model")if not os.path.exists(checkpoint_dir):os.makedirs(checkpoint_dir)#存储所用的变量saver = tf.train.Saver(tf.global_variables())tf.global_variables_initializer().run()global_steps = 1begin_time = int(time.time())print("loading the dataset...")#加载数据#加载word2vec模型pretrained_word_model = KeyedVectors.load_word2vec_format('./GoogleNews-vectors-negative300.bin.gz',binary=True)#获取训练数据pre_train_data = data_helper.load_data(FLAGS.max_len, pretrained_word_model, datapath='./data/stsallrmf.p',embed_dim=FLAGS.emdedding_dim)# 获取训练数据data = data_helper.load_data(FLAGS.max_len, pretrained_word_model, datapath='./data/semtrain.p',embed_dim=FLAGS.emdedding_dim)# 获取测试数据test_data = data_helper.load_data(FLAGS.max_len, pretrained_word_model, datapath='./data/semtest.p',embed_dim=FLAGS.emdedding_dim)print("length of pre-train set:", len(pre_train_data[0]))print("length of train set:", len(data[0]))print("length of test set:", len(test_data[0]))print("begin pre-training")for i in range(70):print("the %d epoch pre-training..." % (i + 1))lr = model.assign_new_lr(session, config.lr)print("current learning rate is %f" % lr)# 11000+ data#将数据切分成测试集和验证集train_data, valid_data = cut_data(pre_train_data, 0.05)#运行模型global_steps = run_epoch(model, session, train_data, global_steps, valid_model, valid_data,train_summary_writer, dev_summary_writer)#保存检查点,预训练结束运行结束path = saver.save(session, checkpoint_prefix, global_steps)print("pre-train finish.")print("Saved pre-train model chechpoint to{}\n".format(path))print("begin training")#开始训练for i in range(config.num_epoch):print("the %d epoch training..." % (i + 1))# lr_decay = config.lr_decay ** max(i - config.max_decay_epoch, 0.0)#学习率lr = model.assign_new_lr(session, config.lr)print('current learning rate is %f' % lr)#切分数据train_data, valid_data = cut_data(data, 0.1)#运行模型global_steps = run_epoch(model, session, train_data, global_steps, valid_model, valid_data,train_summary_writer, dev_summary_writer)#存入检查点if i % config.checkpoint_every == 0:path = saver.save(session, checkpoint_prefix, global_steps)print("Saved model chechpoint to{}\n".format(path))#训练结束print("the train is finished")#训练时间end_time = int(time.time())print("training takes %d seconds already\n" % (end_time - begin_time))#测试数据test_cost, test_pearson_r = evaluate(test_model, session, test_data)print("the test data cost is %f" % test_cost)print("the test data pearson_r is %f" % test_pearson_r)# 测试完结束!!!print("program end!")(3)LSTM模型部分
LSTM部分分为初始化和模型的建立
初始化
初始化首先将接受传递的参数并进行对参数的声明,并设置模型的其他层,比如连接层是用来合成将输出形成句子向量然后将两个句子向量整合成一个向量,再计算其loss的值等,代码内部都有解释。
#参数初始化,将模型参数传递过来def __init__(self, config, sess, is_training=True):#对应参数传递self.keep_prob = config.keep_prob#self.batch_size = config.batch_sizenum_step = config.num_stepembed_dim = config.embed_dim#初始化句子1self.input_data_s1 = tf.placeholder(tf.float64, [None, num_step, embed_dim])self.batch_size1 = tf.placeholder(tf.int32, [])#初始化句子2self.input_data_s2 = tf.placeholder(tf.float64, [None, num_step, embed_dim])# 初始化标签self.target = tf.placeholder(tf.float64, [None])self.mask_s1 = tf.placeholder(tf.float64, [None, num_step])self.mask_s2 = tf.placeholder(tf.float64, [None, num_step])self.hidden_neural_size = config.hidden_neural_size#self.new_batch_size = tf.placeholder(tf.int32, shape=[], name="new_batch_size")#self._batch_size_update = tf.assign(self.batch_size, self.new_batch_size)# with tf.name_scope('embedding_layer'):# init_emb = tf.constant_initializer(table.g)# embedding = tf.get_variable("embedding", shape=table.g.shape, initializer=init_emb, dtype=tf.float32)# self.input_s1 = tf.nn.embedding_lookup(embedding, self.input_data_s1)# self.input_s2 = tf.nn.embedding_lookup(embedding, self.input_data_s2)# 使用dropout会影响效果# if self.keep_prob < 1:# self.input_s1 = tf.nn.dropout(self.input_s1, self.keep_prob)# self.input_s2 = tf.nn.dropout(self.input_s2, self.keep_prob)#执行完神经网络后的输出with tf.name_scope('lstm_output_layer'):#对于句子1self.cell_outputs1 = self.singleRNN(x=self.input_data_s1, batch=self.batch_size1 ,scope='side1', cell='lstm', reuse=None)#对于句子2self.cell_outputs2 = self.singleRNN(x=self.input_data_s2, batch=self.batch_size1,scope='side1', cell='lstm', reuse=True)with tf.name_scope('Sentence_Layer'):# 此处得到句子向量,通过调整mask,可以改变句子向量的组成方式# 由于mask是用于指示句子的结束位置,所以此处使用sum函数而不是mean函数self.sent1 = tf.reduce_sum(self.cell_outputs1 * self.mask_s1[:, :, None], axis=1)self.sent2 = tf.reduce_sum(self.cell_outputs2 * self.mask_s2[:, :, None], axis=1)with tf.name_scope('loss'):#将两个句子向量进行相减操作,diff表示两个词之间的距离diff = tf.abs(tf.subtract(self.sent1, self.sent2), name='err_l1')#两个词之间的距离相加为句子之间的差异diff = tf.reduce_sum(diff, axis=1)#对sim做一个非线性的转化,设置其值域self.sim = tf.clip_by_value(tf.exp(-1.0 * diff), 1e-7, 1.0 - 1e-7)#将相似度与标签进行相减,并对其求开方得出lossself.loss = tf.square(tf.subtract(self.sim, tf.clip_by_value((self.target - 1.0) / 4.0, 1e-7, 1.0 - 1e-7)))# with tf.name_scope('pearson_r'):# _, self.pearson_r = tf.contrib.metrics.streaming_pearson_correlation(self.sim * 4.0 + 1.0, self.target)# sess.run(tf.local_variables_initializer())#代价函数目的评判 一个模型的好坏with tf.name_scope('cost'):self.cost = tf.reduce_mean(self.loss)self.truecost = tf.reduce_mean(tf.square(tf.subtract(self.sim * 4.0 + 1.0, self.target)))#模型结果的可视化的可视化# add summarycost_summary = tf.summary.scalar('cost_summary', self.cost)# r_summary = tf.summary.scalar('r_summary', self.pearson_r)mse_summary = tf.summary.scalar('mse_summary', self.truecost)if not is_training:returnself.globle_step = tf.Variable(0, name="globle_step", trainable=False)self.lr = tf.Variable(0.0, trainable=False)#获得变量但不包括trainable=False的变量tvars = tf.trainable_variables()#计算梯度grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, tvars), config.max_grad_norm)grad_summaries = []for g, v in zip(grads, tvars):if g is not None:#生成一张直方图grad_hist_summary = tf.summary.histogram("{}/grad/hist".format(v.name), g)#显示标量信息sparsity_summary = tf.summary.scalar("{}/grad/sparsity".format(v.name), tf.nn.zero_fraction(g))grad_summaries.append(grad_hist_summary)grad_summaries.append(sparsity_summary)#缓存一下所有的图表self.grad_summaries_merged = tf.summary.merge(grad_summaries)self.summary = tf.summary.merge([cost_summary, mse_summary, self.grad_summaries_merged])#使用Adadelta算法进行优化optimizer = tf.train.AdadeltaOptimizer(learning_rate=0.0001, epsilon=1e-6)with tf.name_scope('train'):#更新节点梯度self.train_op = optimizer.apply_gradients(zip(grads, tvars))#更新学习率self.new_lr = tf.placeholder(tf.float32, shape=[], name="new_learning_rate")self._lr_update = tf.assign(self.lr, self.new_lr)神经网络层
主要是来进行对LSTM的一些操作,比如设置cell的参数,并将cell进行初始化。再调用lstm进行运算。最后输出运算结果。
import tensorflow as tfclass LSTMRNN(object):def singleRNN(self, x,batch, scope, cell='lstm', reuse=None):#如果是使用gru设置每个神经元if cell == 'gru':with tf.variable_scope('grucell' + scope, reuse=reuse, dtype=tf.float64):used_cell = tf.contrib.rnn.GRUCell(self.hidden_neural_size, reuse=tf.get_variable_scope().reuse)# 其他条件下就是用lstm设置每个神经元else:with tf.variable_scope('lstmcell' + scope, reuse=reuse, dtype=tf.float64):used_cell = tf.contrib.rnn.BasicLSTMCell(self.hidden_neural_size, forget_bias=1.0, state_is_tuple=True,reuse=tf.get_variable_scope().reuse)#神经元的初始化with tf.variable_scope('cell_init_state' + scope, reuse=reuse, dtype=tf.float64):self.cell_init_state = used_cell.zero_state(batch, dtype=tf.float64)#使用LSTM进行运算,并将结果保存到outs中with tf.name_scope('RNN_' + scope), tf.variable_scope('RNN_' + scope, dtype=tf.float64):outs, _ = tf.nn.dynamic_rnn(used_cell, x, initial_state=self.cell_init_state, time_major=False,dtype=tf.float64)return outs
运行train.py时把相应的数据和word2vec模型放入代码设置的对应位置就可以进行运算啦,至于结果还得请各位根据数据和任务进行调参或者增加自己的想法来定。
结果如图
运行后是这个样子的: