目录:
- 一、一元函数的可微性
- 二、偏导数
- 三、二元函数的可微性
- 四、 n n n 元函数的可微性
- 五、向量函数的导数
- 作者留言
研究生复试现场:
T:“这位同学,请你解释一下微分是什么。”
S:“啊,老师,微分的定义是~~~~”
T:“嗯,定义背得不错,不过你能说下自己对微分的理解吗?”
S:“这个,呃,这个… …”
T:“好了,回去等通知吧!”
那微分到底是什么意思呢? 一言以蔽之,曰"线性近似".
一、一元函数的可微性
设函数 f ( x ) \small f(x) f(x) 在 x 0 x_0 x0 的某邻域 U ( x 0 ) \small U(x_0) U(x0) 内有定义,若对 U ( x 0 ) \small U(x_0) U(x0) 中的任意一点 x = x 0 + Δ x x=x_0+\Delta x x=x0+Δx,函数增量 Δ f \Delta f Δf 都可以表示为 Δ f = f ( x 0 + Δ x ) − f ( x 0 ) = A Δ x + o ( Δ x ) \Delta f=f(x_0+\Delta x)-f(x_0)=A\Delta x+o(\Delta x) Δf=f(x0+Δx)−f(x0)=AΔx+o(Δx)其中 A \small A A 为常数,仅与 x 0 x_0 x0 有关,则称函数 f f f 在 x 0 x_0 x0 处可微.
另外,还可以求出 A = lim Δ x → 0 f ( x 0 + Δ x ) − f ( x 0 ) Δ x = f ′ ( x 0 ) \displaystyle A=\lim_{\Delta x \to0}\frac{f(x_0+\Delta x)-f(x_0)}{\Delta x}=f'(x_0) A=Δx→0limΔxf(x0+Δx)−f(x0)=f′(x0).
可以看到,可微是函数 局部性质 的一个刻画.
二、偏导数
设函数 f ( x ⃗ ) ( x ⃗ = ( x 1 , x 2 , ⋯ , x n ) ) f(\vec{x}) \,\,(\vec{x}=(x_1,x_2,\cdots,x_n)) f(x)(x=(x1,x2,⋯,xn)) 在点 P 0 = ( x 10 , x 20 , ⋯ , x n 0 ) \small P_0=(x_{10},x_{20},\cdots,x_{n0}) P0=(x10,x20,⋯,xn0) 处有定义. 将 x 1 x_1 x1 以外的其他变量当作常数,令 g ( x 1 ) = f ( x 1 , x 20 , ⋯ , x n 0 ) g(x_1)=f(x_{1},x_{20},\cdots,x_{n0}) g(x1)=f(x1,x20,⋯,xn0),则 g ( x 1 ) g(x_1) g(x1) 是关于 x 1 x_1 x1 的一元函数. 若 g ( x 1 ) g(x_1) g(x1) 在 x 10 x_{10} x10 处的导数 g ′ ( x 10 ) g'(x_{10}) g′(x10) 存在,则称其为函数 f f f 在点 P 0 \small P_0 P0 处关于 x 1 x_1 x1 的偏导数,记作 f x 1 ( P 0 ) or ∂ f ∂ x 1 ∣ P 0 f_{x_1}(P_0) \,\,\textmd{or}\,\, \frac{\partial f}{\partial x_1} \Big|_{P_0} fx1(P0)or∂x1∂f∣∣∣P0
三、二元函数的可微性
设函数 f ( x , y ) f(x,y) f(x,y) 在点 P 0 = ( x 0 , y 0 ) \small P_0=(x_0,y_0) P0=(x0,y0) 的某邻域 U ( P 0 ) \small U(P_0) U(P0) 内有定义,若对 U ( P 0 ) \small U(P_0) U(P0) 中的任意一点 P = ( x , y ) = ( x 0 + Δ x , y 0 + Δ y ) \small P=(x,y)=(x_0+\Delta x,y_0+\Delta y) P=(x,y)=(x0+Δx,y0+Δy),函数增量 Δ f \Delta f Δf 都可以表示为 Δ f = f ( x 0 + Δ x , y 0 + Δ y ) − f ( x 0 , y 0 ) = A Δ x + B Δ y + o ( ( Δ x ) 2 + ( Δ y ) 2 ) \begin{aligned}\Delta f&=f(x_0+\Delta x,y_0+\Delta y)-f(x_0,y_0)\\&=A\Delta x+ B\Delta y+o\big(\sqrt{(\Delta x)^2+(\Delta y)^2}\,\big)\end{aligned} Δf=f(x0+Δx,y0+Δy)−f(x0,y0)=AΔx+BΔy+o((Δx)2+(Δy)2)其中 A , B \small A,B A,B 为常数,仅与 P 0 \small P_0 P0 有关,则称函数 f f f 在 P 0 \small P_0 P0 处可微.
一元函数情形中,函数增量 Δ f \Delta f Δf 可以表示为 Δ f = f ( x 0 + Δ x ) − f ( x 0 ) = A Δ x + o ( Δ x ) \Delta f=f(x_0+\Delta x)-f(x_0)=A\Delta x+o(\Delta x) Δf=f(x0+Δx)−f(x0)=AΔx+o(Δx)并求得 A = f ′ ( x 0 ) A=f'(x_0) A=f′(x0).
那么在二元函数中 A , B \small A,B A,B又是什么呢?直觉性较强的读者应该能够猜到 A = f x ( x 0 , y 0 ) , B = f y ( x 0 , y 0 ) A=f_x(x_0,y_0), B=f_y(x_0,y_0) A=fx(x0,y0),B=fy(x0,y0)(不然我为什么要先介绍偏导数呢?嘿嘿 )
下面来证明这个直觉是对的.
1. 1.\,\, 1.证明 o ( ( Δ x ) 2 + ( Δ y ) 2 ) = α Δ x + β Δ y o\big(\sqrt{(\Delta x)^2+(\Delta y)^2}\,\big)=\alpha\Delta x+\beta\Delta y o((Δx)2+(Δy)2)=αΔx+βΔy,其中 α , β \alpha,\beta α,β 是 ( Δ x , Δ y ) (\Delta x,\Delta y) (Δx,Δy) 的函数且满足 lim ( Δ x , Δ y ) → ( 0 , 0 ) α = lim ( Δ x , Δ y ) → ( 0 , 0 ) β = 0 \lim_{(\Delta x,\Delta y)\to(0,0)}\alpha=\lim_{(\Delta x,\Delta y)\to(0,0)}\beta=0 (Δx,Δy)→(0,0)limα=(Δx,Δy)→(0,0)limβ=0证明:
( 1 ) ⇐ : (1) \Leftarrow: (1)⇐: 证 α Δ x + β Δ y = o ( ( Δ x ) 2 + ( Δ y ) 2 ) \alpha\Delta x+\beta\Delta y=o\big(\sqrt{(\Delta x)^2+(\Delta y)^2}\,\big) αΔx+βΔy=o((Δx)2+(Δy)2) ∣ α Δ x + β Δ y ( Δ x ) 2 + ( Δ y ) 2 ∣ = ∣ α Δ x ( Δ x ) 2 + ( Δ y ) 2 + β Δ y ( Δ x ) 2 + ( Δ y ) 2 ∣ ≤ ∣ α ∣ ∣ Δ x ( Δ x ) 2 + ( Δ y ) 2 ∣ + ∣ β ∣ ∣ Δ y ( Δ x ) 2 + ( Δ y ) 2 ∣ ≤ ∣ α ∣ + ∣ β ∣ \begin{aligned} \Big| \frac{\alpha\Delta x+\beta\Delta y}{\sqrt{(\Delta x)^2+(\Delta y)^2}}\Big|&=\Big| \alpha\frac{\Delta x}{\sqrt{(\Delta x)^2+(\Delta y)^2}}+\beta\frac{\Delta y}{\sqrt{(\Delta x)^2+(\Delta y)^2}}\Big| \\& \leq \vert \alpha\vert\Big|\frac{\Delta x}{\sqrt{(\Delta x)^2+(\Delta y)^2}}\Big|+\vert \beta\vert\Big|\frac{\Delta y}{\sqrt{(\Delta x)^2+(\Delta y)^2}}\Big| \\& \leq\vert \alpha \vert+\vert \beta \vert \end{aligned} ∣∣∣(Δx)2+(Δy)2αΔx+βΔy∣∣∣=∣∣∣α(Δx)2+(Δy)2Δx+β(Δx)2+(Δy)2Δy∣∣∣≤∣α∣∣∣∣(Δx)2+(Δy)2Δx∣∣∣+∣β∣∣∣∣(Δx)2+(Δy)2Δy∣∣∣≤∣α∣+∣β∣两边取极限,得 lim ( Δ x , Δ y ) → ( 0 , 0 ) α Δ x + β Δ y ( Δ x ) 2 + ( Δ y ) 2 = 0 \lim_{(\Delta x,\Delta y)\to(0,0)} \frac{\alpha\Delta x+\beta\Delta y}{\sqrt{(\Delta x)^2+(\Delta y)^2}}=0 (Δx,Δy)→(0,0)lim(Δx)2+(Δy)2αΔx+βΔy=0因此, α Δ x + β Δ y = o ( ( Δ x ) 2 + ( Δ y ) 2 ) \alpha\Delta x+\beta\Delta y=o\big(\sqrt{(\Delta x)^2+(\Delta y)^2}\,\big) αΔx+βΔy=o((Δx)2+(Δy)2).
( 2 ) ⇒ : (2) \Rightarrow: (2)⇒: 证 o ( ( Δ x ) 2 + ( Δ y ) 2 ) = α Δ x + β Δ y o\big(\sqrt{(\Delta x)^2+(\Delta y)^2}\,\big)=\alpha\Delta x+\beta\Delta y o((Δx)2+(Δy)2)=αΔx+βΔy,其中 lim ( Δ x , Δ y ) → ( 0 , 0 ) α = lim ( Δ x , Δ y ) → ( 0 , 0 ) β = 0 \lim_{(\Delta x,\Delta y)\to(0,0)}\alpha=\lim_{(\Delta x,\Delta y)\to(0,0)}\beta=0 (Δx,Δy)→(0,0)limα=(Δx,Δy)→(0,0)limβ=0 由定义易知, o ( ( Δ x ) 2 + ( Δ y ) 2 ) = ε ( Δ x ) 2 + ( Δ y ) 2 o\big(\sqrt{(\Delta x)^2+(\Delta y)^2}\,\big)=\varepsilon\sqrt{(\Delta x)^2+(\Delta y)^2} o((Δx)2+(Δy)2)=ε(Δx)2+(Δy)2,其中 ε \varepsilon ε 是 ( Δ x , Δ y ) (\Delta x,\Delta y) (Δx,Δy) 的函数且满足 lim ( Δ x , Δ y ) → ( 0 , 0 ) ε = 0 \displaystyle \lim_{(\Delta x,\Delta y)\to(0,0)}\varepsilon=0 (Δx,Δy)→(0,0)limε=0. ε ( Δ x ) 2 + ( Δ y ) 2 = ε ( Δ x ) 2 + ( Δ y ) 2 ( Δ x ) 2 + ( Δ y ) 2 = ε Δ x ( Δ x ) 2 + ( Δ y ) 2 Δ x + ε Δ y ( Δ x ) 2 + ( Δ y ) 2 Δ y \begin{aligned}&\,\,\varepsilon\sqrt{(\Delta x)^2+(\Delta y)^2}\\=&\,\,\varepsilon\frac{(\Delta x)^2+(\Delta y)^2}{\sqrt{(\Delta x)^2+(\Delta y)^2}}\\=&\,\frac{\varepsilon\Delta x}{\sqrt{(\Delta x)^2+(\Delta y)^2}}\Delta x+\frac{\varepsilon\Delta y}{\sqrt{(\Delta x)^2+(\Delta y)^2}}\Delta y \end{aligned} ==ε(Δx)2+(Δy)2ε(Δx)2+(Δy)2(Δx)2+(Δy)2(Δx)2+(Δy)2εΔxΔx+(Δx)2+(Δy)2εΔyΔy令 α = ε Δ x ( Δ x ) 2 + ( Δ y ) 2 , β = ε Δ y ( Δ x ) 2 + ( Δ y ) 2 \displaystyle \alpha=\frac{\varepsilon\Delta x}{\sqrt{(\Delta x)^2+(\Delta y)^2}},\,\beta=\frac{\varepsilon\Delta y}{\sqrt{(\Delta x)^2+(\Delta y)^2}} α=(Δx)2+(Δy)2εΔx,β=(Δx)2+(Δy)2εΔy,则 ε ( Δ x ) 2 + ( Δ y ) 2 = α Δ x + β Δ y \varepsilon\sqrt{(\Delta x)^2+(\Delta y)^2}=\alpha\Delta x+\beta\Delta y ε(Δx)2+(Δy)2=αΔx+βΔy ∣ α ∣ = ∣ ε ∣ ∣ Δ x ( Δ x ) 2 + ( Δ y ) 2 ∣ ≤ ∣ ε ∣ \vert\alpha\vert=\vert \varepsilon\vert \Big| \frac{\Delta x}{\sqrt{(\Delta x)^2+(\Delta y)^2}}\Big| \leq \vert \varepsilon\vert ∣α∣=∣ε∣∣∣∣(Δx)2+(Δy)2Δx∣∣∣≤∣ε∣两边取极限,得 lim ( Δ x , Δ y ) → ( 0 , 0 ) α = 0 \displaystyle \lim_{(\Delta x,\Delta y)\to(0,0)}\alpha=0 (Δx,Δy)→(0,0)limα=0. 同理可证 lim ( Δ x , Δ y ) → ( 0 , 0 ) β = 0 \displaystyle \lim_{(\Delta x,\Delta y)\to(0,0)}\beta=0 (Δx,Δy)→(0,0)limβ=0.
因此, o ( ( Δ x ) 2 + ( Δ y ) 2 ) = α Δ x + β Δ y o\big(\sqrt{(\Delta x)^2+(\Delta y)^2}\,\big)=\alpha\Delta x+\beta\Delta y o((Δx)2+(Δy)2)=αΔx+βΔy.
2. 2.\,\, 2.由上述结论,函数增量 Δ f \Delta f Δf 可以表示为
Δ f = A Δ x + B Δ y + o ( ( Δ x ) 2 + ( Δ y ) 2 ) = A Δ x + B Δ y + α Δ x + β Δ y \begin{aligned}\Delta f&=A\Delta x+B\Delta y+o\big(\sqrt{(\Delta x)^2+(\Delta y)^2}\,\big)\\&=A\Delta x+B\Delta y+\alpha\Delta x+\beta\Delta y\end{aligned} Δf=AΔx+BΔy+o((Δx)2+(Δy)2)=AΔx+BΔy+αΔx+βΔy其中 lim ( Δ x , Δ y ) → ( 0 , 0 ) α = lim ( Δ x , Δ y ) → ( 0 , 0 ) β = 0 \displaystyle \lim_{(\Delta x,\Delta y)\to(0,0)}\alpha=\lim_{(\Delta x,\Delta y)\to(0,0)}\beta=0 (Δx,Δy)→(0,0)limα=(Δx,Δy)→(0,0)limβ=0.
取 Δ y = 0 \Delta y=0 Δy=0,则 Δ f = A Δ x + α Δ x = A Δ x + o ( Δ x ) \Delta f=A\Delta x+\alpha\Delta x=A\Delta x+o(\Delta x) Δf=AΔx+αΔx=AΔx+o(Δx).
由一元函数可微性及偏导数定义,可得 A = f x ( x 0 , y 0 ) A=f_x(x_0,y_0) A=fx(x0,y0). 同理 B = f y ( x 0 , y 0 ) B=f_y(x_0,y_0) B=fy(x0,y0).
于是 Δ f = f x ( x 0 , y 0 ) Δ x + f y ( x 0 , y 0 ) Δ y + o ( ( Δ x ) 2 + ( Δ y ) 2 ) = c ⃗ Δ x ⃗ + o ( ∥ Δ x ⃗ ∥ ) \begin{aligned}\Delta f&=f_x(x_0,y_0)\Delta x+f_y(x_0,y_0)\Delta y+o\big(\sqrt{(\Delta x)^2+(\Delta y)^2}\,\big)\\&=\vec{c}\,\Delta \vec{x}+o(\Vert \Delta \vec{x}\Vert)\end{aligned} Δf=fx(x0,y0)Δx+fy(x0,y0)Δy+o((Δx)2+(Δy)2)=cΔx+o(∥Δx∥)其中, c ⃗ = ( f x ( x 0 , y 0 ) , f y ( x 0 , y 0 ) ) , Δ x ⃗ = ( Δ x , Δ y ) T , ∥ Δ x ⃗ ∥ = ( Δ x ) 2 + ( Δ y ) 2 \vec{c}=(f_x(x_0,y_0),f_y(x_0,y_0)),\Delta \vec{x}=(\Delta x,\Delta y)^T,\Vert \Delta \vec{x}\Vert=\sqrt{(\Delta x)^2+(\Delta y)^2} c=(fx(x0,y0),fy(x0,y0)),Δx=(Δx,Δy)T,∥Δx∥=(Δx)2+(Δy)2.
四、 n n n 元函数的可微性
新酒装旧壶
设 n n n 元函数 f ( x ⃗ ) ( x ⃗ = ( x 1 , x 2 , ⋯ , x n ) T ) f(\vec{x})\,(\vec{x}=(x_1,x_2,\cdots,x_n)^T) f(x)(x=(x1,x2,⋯,xn)T) 在点 x ⃗ 0 = ( x 10 , x 20 , ⋯ , x n 0 ) T \vec{x}_0=(x_{10},x_{20},\cdots,x_{n0})^T x0=(x10,x20,⋯,xn0)T 的某邻域 U ( x ⃗ 0 ) \small U(\vec{x}_0) U(x0) 内有定义,若对 U ( x ⃗ 0 ) \small U(\vec{x}_0) U(x0) 中的任意一点 x ⃗ = x ⃗ 0 + Δ x ⃗ ( Δ x ⃗ = ( Δ x 1 , Δ x 2 , ⋯ , Δ x n ) T ) \vec{x}=\vec{x}_0+\Delta \vec{x}\,\, (\Delta \vec{x}=(\Delta x_1,\Delta x_2,\cdots,\Delta x_n)^T) x=x0+Δx(Δx=(Δx1,Δx2,⋯,Δxn)T),函数增量 Δ f \Delta f Δf 都可以表示为 Δ f = f ( x ⃗ 0 + Δ x ⃗ ) − f ( x ⃗ 0 ) = c 1 Δ x 1 + c 2 Δ x 2 + ⋯ + c n Δ x n + o ( ∥ Δ x ⃗ ∥ ) \begin{aligned}\Delta f&=f(\vec{x}_0+\Delta \vec{x})-f(\vec{x}_0)\\&=c_1\Delta x_1+ c_2\Delta x_2+\cdots+c_n\Delta x_n+o(\Vert\Delta \vec{x}\Vert)\end{aligned} Δf=f(x0+Δx)−f(x0)=c1Δx1+c2Δx2+⋯+cnΔxn+o(∥Δx∥)其中 c 1 , c 2 , ⋯ , c n c_1,c_2,\cdots,c_n c1,c2,⋯,cn 为常数,仅与 x ⃗ 0 \vec{x}_0 x0 有关,则称函数 f f f 在 x ⃗ 0 \vec{x}_0 x0 处可微.
同理可证, o ( ∥ Δ x ⃗ ∥ ) = ε 1 Δ x 1 + ε 2 Δ x 2 + ⋯ + ε n Δ x n o(\Vert\Delta \vec{x}\Vert)=\varepsilon_1\Delta x_1+\varepsilon_2\Delta x_2+\cdots+\varepsilon_n\Delta x_n o(∥Δx∥)=ε1Δx1+ε2Δx2+⋯+εnΔxn,其中 lim Δ x ⃗ → 0 ⃗ ε i = 0 \displaystyle \lim_{\Delta \vec{x}\to\vec{0}}\varepsilon_i=0 Δx→0limεi=0.
同理亦可证, c i = f x i ( x ⃗ 0 ) c_i=f_{x_i}(\vec{x}_0 ) ci=fxi(x0).
令 c = ( c 1 , c 2 , ⋯ , c n ) = ( f x 1 ( x ⃗ 0 ) , f x 2 ( x ⃗ 0 ) , ⋯ , f x n ( x ⃗ 0 ) ) c=(c_1,c_2,\cdots,c_n)=(f_{x_1}(\vec{x}_0 ),f_{x_2}(\vec{x}_0 ),\cdots,f_{x_n}(\vec{x}_0 )) c=(c1,c2,⋯,cn)=(fx1(x0),fx2(x0),⋯,fxn(x0)),
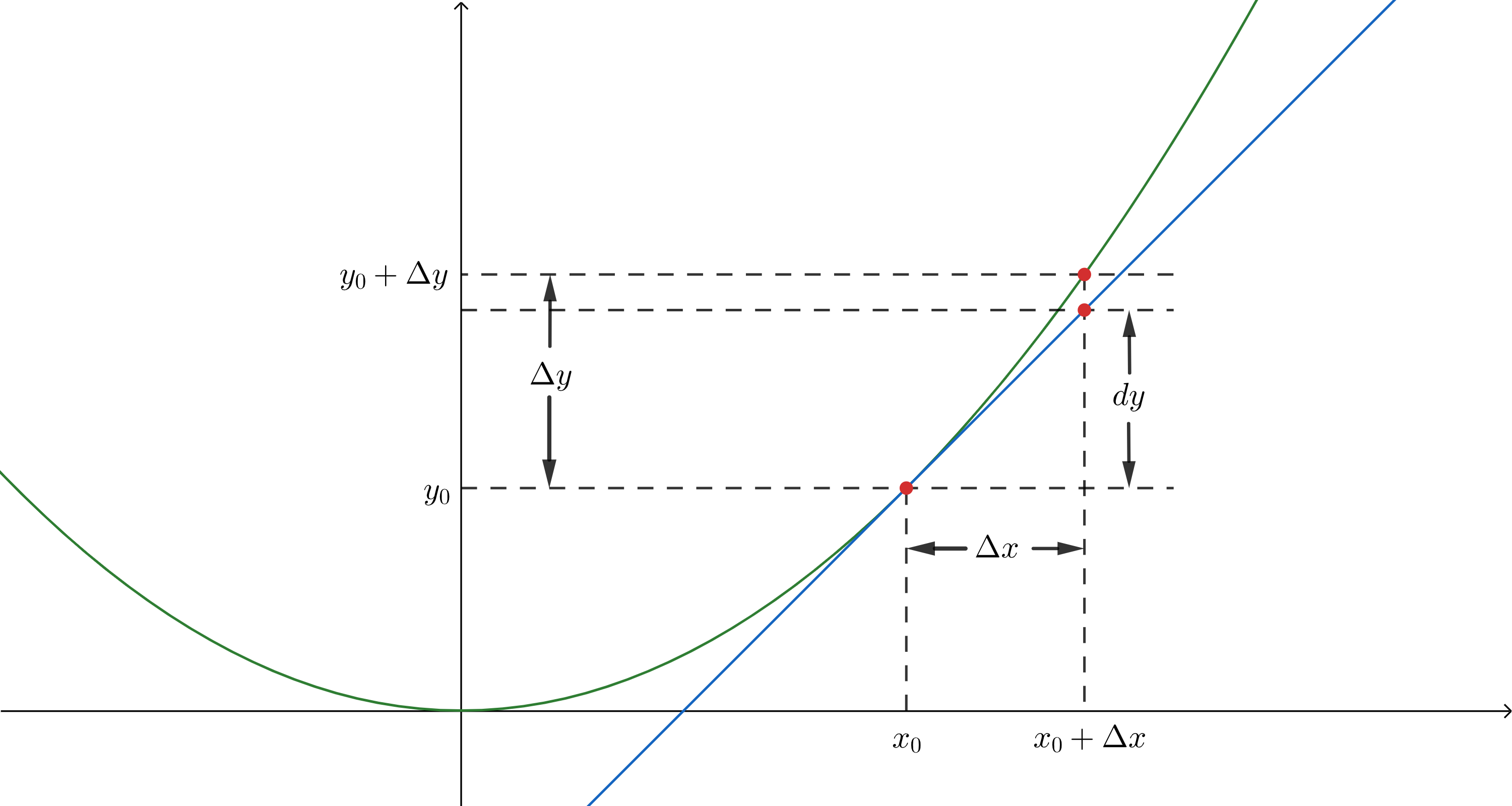
则 Δ f = c Δ x ⃗ + o ( ∥ Δ x ⃗ ∥ ) \Delta f=c\,\Delta \vec{x}+o(\Vert\Delta \vec{x}\Vert) Δf=cΔx+o(∥Δx∥),其中 d y = c Δ x ⃗ dy=c\,\Delta \vec{x} dy=cΔx 称为全微分.
由此推知 n n n 元函数的导数为 f ′ ( x ⃗ ) = ( f x 1 ( x ⃗ ) , f x 2 ( x ⃗ ) , ⋯ , f x n ( x ⃗ ) ) = ( ∂ f ∂ x 1 , ∂ f ∂ x 2 , ⋯ , ∂ f ∂ x n ) f'(\vec{x})=(f_{x_1}(\vec{x}),f_{x_2}(\vec{x}),\cdots,f_{x_n}(\vec{x}))=(\frac{\partial f}{\partial x_1},\frac{\partial f}{\partial x_2},\cdots,\frac{\partial f}{\partial x_n}) f′(x)=(fx1(x),fx2(x),⋯,fxn(x))=(∂x1∂f,∂x2∂f,⋯,∂xn∂f)咦?这不就是梯度吗?或者说是梯度的转置
那,微分怎么就是线性近似了呢?
不急不急,先来看下 n n n 维空间中的超平面,定义为 { x ⃗ ∣ c ⃗ x ⃗ = d , c ⃗ ( c ⃗ ≠ 0 ⃗ ) \lbrace \vec{x}\,| \,\vec{c}\,\vec{x}=d,\vec{c}\,(\vec{c}\neq \vec{0}) {x∣cx=d,c(c=0) 为"平面"的法向量(行向量), d d d 为常数 } ⊂ R n \small \rbrace\subset R^n }⊂Rn.
n = 2 n=2 n=2 时,是平面 R 2 \small R^2 R2 中的一条直线;
n = 3 n=3 n=3 时,是三维空间 R 3 \small R^3 R3 中的一个平面;
n > 3 n>3 n>3 时,便是 R n \small R^n Rn 中的超平面.
有了微分,我们便可以据此给出 x ⃗ 0 \vec{x}_0 x0 附近 x ⃗ \vec{x} x 处函数的估计值,即 f ^ ( x ⃗ ) = f ( x ⃗ 0 ) + d y = f ( x ⃗ 0 ) + f ′ ( x ⃗ 0 ) ( x ⃗ − x ⃗ 0 ) \hat{f}(\vec{x})=f(\vec{x}_0)+dy=f(\vec{x}_0)+f'(\vec{x}_0)(\vec{x}-\vec{x}_0) f^(x)=f(x0)+dy=f(x0)+f′(x0)(x−x0).
令 c ⃗ = ( f ′ ( x ⃗ 0 ) , − 1 ) \vec{c}=(f'(\vec{x}_0),-1) c=(f′(x0),−1),令 x ⃗ n e w = ( x ⃗ T , f ^ ( x ⃗ ) ) T , x ⃗ o l d = ( x ⃗ 0 T , f ( x ⃗ 0 ) ) T \vec{x}_{new}=(\vec{x}^T,\hat{f}(\vec{x}))^T,\vec{x}_{old}=(\vec{x}_0^T,f(\vec{x}_0))^T xnew=(xT,f^(x))T,xold=(x0T,f(x0))T,
则 c ⃗ x ⃗ n e w = c ⃗ x ⃗ o l d = d 0 \,\vec{c}\,\vec{x}_{new}=\vec{c}\,\vec{x}_{old}=d_0 cxnew=cxold=d0.
因此,近似点 x ⃗ n e w \vec{x}_{new} xnew 与已知点 x ⃗ o l d \vec{x}_{old} xold 位于同一超平面上,这便是线性近似.
一元函数,近似点位于切线上;
二元函数,近似点位于切平面上;
n n n 元函数,近似点位于 R n + 1 R^{n+1} Rn+1 中的“切超平面”上.

五、向量函数的导数
(这部分可以跳过,不影响对“微分”的理解,写出来是为了保证文章的完整性)
换汤不换药
什么是向量函数?简单来讲,就是函数"值"不再是数(实数或复数),而是向量. 具体定义如下:
设 X ⊂ R n , Y ⊂ R m \small X\subset R^n,\,Y\subset R^m X⊂Rn,Y⊂Rm,若对任意的 x ⃗ ∈ X \vec{x}\in X x∈X,都存在唯一的 y ⃗ ∈ Y \vec{y}\in Y y∈Y 与之对应,则将此映射称为向量函数,记作 f : X → Y x ↦ y \begin{aligned}f:\,X&\to Y\\ x&\mapsto y\end{aligned} f:Xx→Y↦y
嘶,向量到向量的映射,啊,这让人怎么想象?
让我来给您解释一下:记 f ( x ⃗ ) = ( f 1 ( x ⃗ ) , f 2 ( x ⃗ ) , ⋯ , f m ( x ⃗ ) ) T f(\vec{x})=(f_1(\vec{x}),f_2(\vec{x}),\cdots,f_m(\vec{x}))^T f(x)=(f1(x),f2(x),⋯,fm(x))T,则 f i ( x ⃗ ) f_i(\vec{x}) fi(x) 为 n n n 元函数. 于是,向量函数便可以理解为 m m m 个 n n n 元函数拼成的东东.
emm, n n\, n元函数的导数是个向量,那向量函数的导数该是什么?
数学直觉动起来,没错,答案就是——矩阵,下面来验证这一猜想.
先来回顾下多元函数(可微时)函数增量的表达式
Δ f i = f i ( x ⃗ 0 + Δ x ⃗ ) − f i ( x ⃗ 0 ) = c i Δ x ⃗ + o ( ∥ Δ x ⃗ ∥ ) \Delta f_i=f_i(\vec{x}_0+\Delta \vec{x})-f_i(\vec{x}_0)=c_{i}\Delta \vec{x}+o(\Vert\Delta \vec{x}\Vert) Δfi=fi(x0+Δx)−fi(x0)=ciΔx+o(∥Δx∥)其中 c i = f i ′ ( x ⃗ 0 ) c_i=f'_i(\vec{x}_0) ci=fi′(x0). 把这些 Δ f i \Delta f_i Δfi 拼起来, Δ f = ( Δ f 1 Δ f 2 ⋮ Δ f m ) = ( c 1 c 2 ⋮ c m ) Δ x ⃗ + o ⃗ ( ∥ Δ x ⃗ ∥ ) = A Δ x ⃗ + o ⃗ ( ∥ Δ x ⃗ ∥ ) \Delta f=\begin{pmatrix}\Delta f_1 \\ \Delta f_2 \\ \vdots \\ \Delta f_m\\\end{pmatrix}=\begin{pmatrix}c_1 \\ c_2 \\ \vdots \\c_m\\\end{pmatrix}\Delta \vec{x}+\vec{o}(\Vert\Delta \vec{x}\Vert)=A\Delta \vec{x}+\vec{o}(\Vert\Delta \vec{x}\Vert) Δf=⎝⎜⎜⎜⎛Δf1Δf2⋮Δfm⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛c1c2⋮cm⎠⎟⎟⎟⎞Δx+o(∥Δx∥)=AΔx+o(∥Δx∥)其中 A = ( c 1 c 2 ⋮ c m ) = ( f 1 ′ ( x ⃗ 0 ) f 2 ′ ( x ⃗ 0 ) ⋮ f m ′ ( x ⃗ 0 ) ) = ( ∂ f 1 ∂ x 1 ∂ f 1 ∂ x 2 ⋯ ∂ f 1 ∂ x n ∂ f 2 ∂ x 1 ∂ f 2 ∂ x 2 ⋯ ∂ f 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ f m ∂ x 1 ∂ f m ∂ x 2 ⋯ ∂ f m ∂ x n ) A=\begin{pmatrix}c_1\\c_2\\\vdots\\c_m\end{pmatrix}= \begin{pmatrix}f'_1(\vec{x}_0)\\f'_2(\vec{x}_0)\\\vdots\\f'_m(\vec{x}_0)\end{pmatrix}= \begin{pmatrix} \frac{\partial f_1}{\partial x_1} & \frac{\partial f_1}{\partial x_2} & \cdots & \frac{\partial f_1}{\partial x_n}\\ \frac{\partial f_2}{\partial x_1} & \frac{\partial f_2}{\partial x_2} & \cdots & \frac{\partial f_2}{\partial x_n}\\ \vdots & \vdots & \ddots & \vdots\\ \frac{\partial f_m}{\partial x_1} & \frac{\partial f_m}{\partial x_2} & \cdots & \frac{\partial f_m}{\partial x_n}\\ \end{pmatrix} A=⎝⎜⎜⎜⎛c1c2⋮cm⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛f1′(x0)f2′(x0)⋮fm′(x0)⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎜⎛∂x1∂f1∂x1∂f2⋮∂x1∂fm∂x2∂f1∂x2∂f2⋮∂x2∂fm⋯⋯⋱⋯∂xn∂f1∂xn∂f2⋮∂xn∂fm⎠⎟⎟⎟⎟⎞ A \small A A 就是向量函数 f f f 的导数,有时也被称为 f f f 的 J a c o b i \small Jacobi Jacobi 矩阵,记作 J f ( x ⃗ 0 ) \small J_f(\vec{x}_0) Jf(x0).
巧的是,这样得到的导数同样满足求导的链式法则.
补充两个例子
1. f ( x ) = A x 1. \,f(x)=Ax 1.f(x)=Ax, A A A 为 m × n m\times n m×n 阶矩阵.
f ( x ) = ( a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a m 1 a m 2 ⋯ a m n ) ( x 1 x 2 ⋮ x n ) = ( a 11 x 1 + a 12 x 2 + ⋯ + a 1 n x n a 21 x 1 + a 22 x 2 + ⋯ + a 2 n x n ⋮ a m 1 x 1 + a m 2 x 2 + ⋯ + a m n x n ) = ( f 1 f 2 ⋮ f n ) f(x)= \begin{pmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \end{pmatrix}\begin{pmatrix}x_1\\x_2\\\vdots\\x_n\end{pmatrix}= \begin{pmatrix} a_{11}x_1 + a_{12}x_2 + \cdots + a_{1n}x_n\\ a_{21}x_1 + a_{22}x_2 + \cdots + a_{2n}x_n\\ \vdots\\ a_{m1}x_1 + a_{m2}x_2 + \cdots + a_{mn}x_n\end{pmatrix}= \begin{pmatrix}f_1\\f_2\\\vdots\\f_n\end{pmatrix} f(x)=⎝⎜⎜⎜⎛a11a21⋮am1a12a22⋮am2⋯⋯⋱⋯a1na2n⋮amn⎠⎟⎟⎟⎞⎝⎜⎜⎜⎛x1x2⋮xn⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛a11x1+a12x2+⋯+a1nxna21x1+a22x2+⋯+a2nxn⋮am1x1+am2x2+⋯+amnxn⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛f1f2⋮fn⎠⎟⎟⎟⎞
则
f ′ ( x ) = ( ∂ f 1 ∂ x 1 ∂ f 1 ∂ x 2 ⋯ ∂ f 1 ∂ x n ∂ f 2 ∂ x 1 ∂ f 2 ∂ x 2 ⋯ ∂ f 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ f m ∂ x 1 ∂ f m ∂ x 2 ⋯ ∂ f m ∂ x n ) = ( a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a m 1 a m 2 ⋯ a m n ) = A f'(x)= \begin{pmatrix} \frac{\partial f_1}{\partial x_1} & \frac{\partial f_1}{\partial x_2} & \cdots & \frac{\partial f_1}{\partial x_n}\\ \frac{\partial f_2}{\partial x_1} & \frac{\partial f_2}{\partial x_2} & \cdots & \frac{\partial f_2}{\partial x_n}\\ \vdots & \vdots & \ddots & \vdots\\ \frac{\partial f_m}{\partial x_1} & \frac{\partial f_m}{\partial x_2} & \cdots & \frac{\partial f_m}{\partial x_n}\\ \end{pmatrix}= \begin{pmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \end{pmatrix}=A f′(x)=⎝⎜⎜⎜⎜⎛∂x1∂f1∂x1∂f2⋮∂x1∂fm∂x2∂f1∂x2∂f2⋮∂x2∂fm⋯⋯⋱⋯∂xn∂f1∂xn∂f2⋮∂xn∂fm⎠⎟⎟⎟⎟⎞=⎝⎜⎜⎜⎛a11a21⋮am1a12a22⋮am2⋯⋯⋱⋯a1na2n⋮amn⎠⎟⎟⎟⎞=A
2. f ( x ) = x T A x 2. \,f(x)=x^TAx 2.f(x)=xTAx, A A A 为 n n n 阶方阵.
f ( x ) = a 11 x 1 x 1 + a 12 x 1 x 2 + ⋯ + a 1 n x 1 x n + a 21 x 2 x 1 + a 22 x 2 x 2 + ⋯ + a 2 n x 2 x n + ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ + a n 1 x n x 1 + a n 2 x n x 2 + ⋯ + a n n x n x n \begin{aligned} f(x)&=a_{11}x_1x_1+a_{12}x_1x_2+\cdots+a_{1n}x_1x_n\\ &+a_{21}x_2x_1+a_{22}x_2x_2+\cdots+a_{2n}x_2x_n\\ &+\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\\ &+a_{n1}x_nx_1+a_{n2}x_nx_2+\cdots+a_{nn}x_nx_n \end{aligned} f(x)=a11x1x1+a12x1x2+⋯+a1nx1xn+a21x2x1+a22x2x2+⋯+a2nx2xn+⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯+an1xnx1+an2xnx2+⋯+annxnxn则
∂ f ∂ x 1 = 2 a 11 x 1 + a 12 x 2 + ⋯ + a 1 n x n + a 21 x 2 + a 31 x 3 + ⋯ + a n 1 x n = ( a 11 + a 11 ) x 1 + ( a 12 + a 21 ) x 2 + ⋯ + ( a 1 n + a n 1 ) x n = ( a 11 + a 11 a 12 + a 21 ⋯ a 1 n + a n 1 ) ( x 1 x 2 ⋮ x n ) \begin{aligned} \frac{\partial f}{\partial x_1}&=2a_{11}x_1+a_{12}x_2+\cdots+a_{1n}x_n +a_{21}x_2+a_{31}x_3+\cdots+a_{n1}x_n\\&=(a_{11}+a_{11})x_1+(a_{12}+a_{21})x_2+\cdots+(a_{1n}+a_{n1})x_n\\&= \begin{pmatrix} a_{11}+a_{11} & a_{12}+a_{21} & \cdots & a_{1n}+a_{n1} \end{pmatrix}\begin{pmatrix}x_1\\x_2\\\vdots\\x_n\end{pmatrix} \end{aligned} ∂x1∂f=2a11x1+a12x2+⋯+a1nxn+a21x2+a31x3+⋯+an1xn=(a11+a11)x1+(a12+a21)x2+⋯+(a1n+an1)xn=(a11+a11a12+a21⋯a1n+an1)⎝⎜⎜⎜⎛x1x2⋮xn⎠⎟⎟⎟⎞则
∇ f = ( ∂ f ∂ x 1 ∂ f ∂ x 2 ⋮ ∂ f ∂ x n ) = ( a 11 + a 11 a 12 + a 21 ⋯ a 1 n + a n 1 a 21 + a 12 a 22 + a 22 ⋯ a 2 n + a n 2 ⋮ ⋮ ⋱ ⋮ a n 1 + a 1 n a n 2 + a 2 n ⋯ a n n + a n n ) ( x 1 x 2 ⋮ x n ) = ( A + A T ) x \nabla f= \begin{pmatrix}\frac{\partial f}{\partial x_1} \\ \frac{\partial f}{\partial x_2} \\ \vdots \\ \frac{\partial f}{\partial x_n}\end{pmatrix}= \begin{pmatrix} a_{11}+a_{11} & a_{12}+a_{21} & \cdots & a_{1n}+a_{n1}\\ a_{21}+a_{12} & a_{22}+a_{22} & \cdots & a_{2n}+a_{n2}\\ \vdots & \vdots & \ddots & \vdots\\ a_{n1}+a_{1n} & a_{n2}+a_{2n} & \cdots & a_{nn}+a_{nn} \end{pmatrix}\begin{pmatrix}x_1\\x_2\\\vdots\\x_n\end{pmatrix}=(A+A^T)x ∇f=⎝⎜⎜⎜⎜⎛∂x1∂f∂x2∂f⋮∂xn∂f⎠⎟⎟⎟⎟⎞=⎝⎜⎜⎜⎛a11+a11a21+a12⋮an1+a1na12+a21a22+a22⋮an2+a2n⋯⋯⋱⋯a1n+an1a2n+an2⋮ann+ann⎠⎟⎟⎟⎞⎝⎜⎜⎜⎛x1x2⋮xn⎠⎟⎟⎟⎞=(A+AT)x 特别地,若 A = A T \small A=A^T A=AT,则 ∇ f = 2 A x \small \nabla f=2Ax ∇f=2Ax.
作者留言
线性近似其实是"一次多项式"近似,那更高次数的多项式近似是什么?
答案是泰勒展开,欲知后事如何,请看下回分解.
参考文献:
1.华东师范大学数学系.数学分析(下册)[M].第四版.北京:高等教育出版社,2010.
Plus: 如有错误、可以改进的地方、或任何想说的,请在评论区留言!