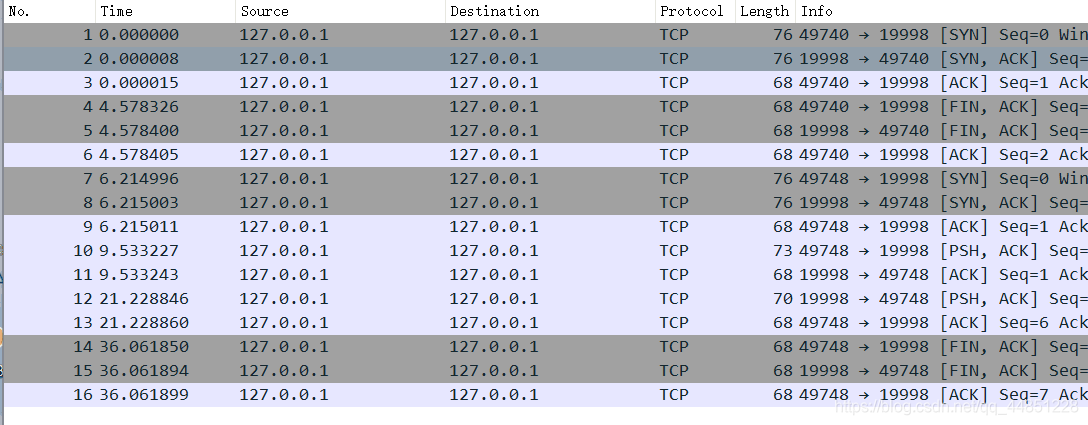
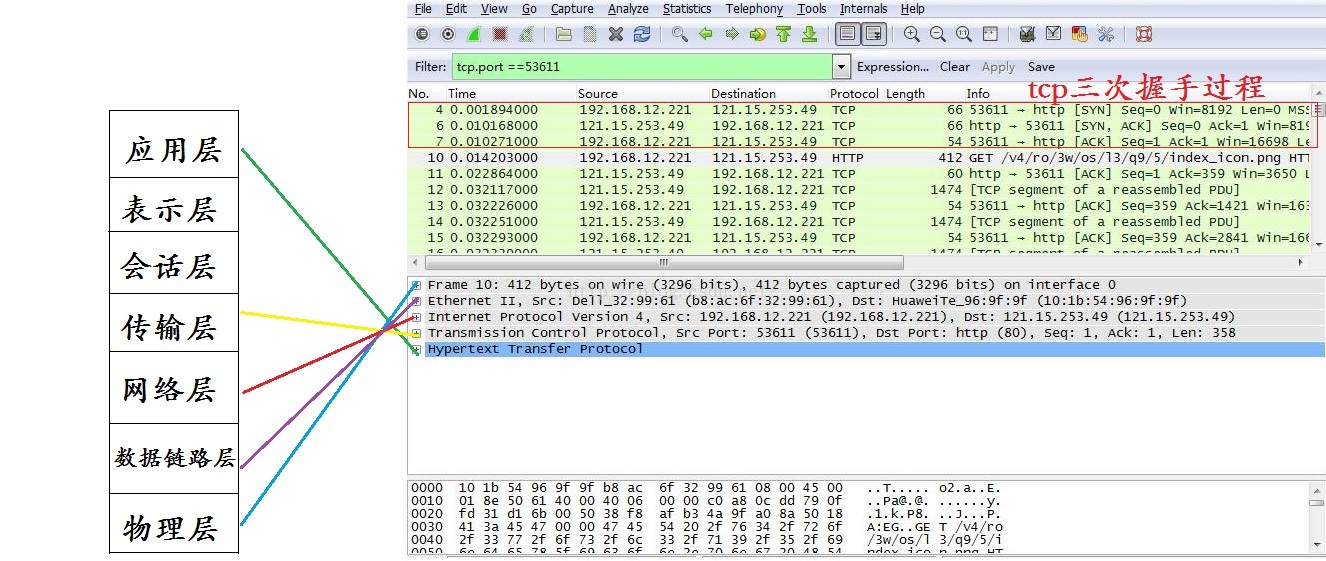
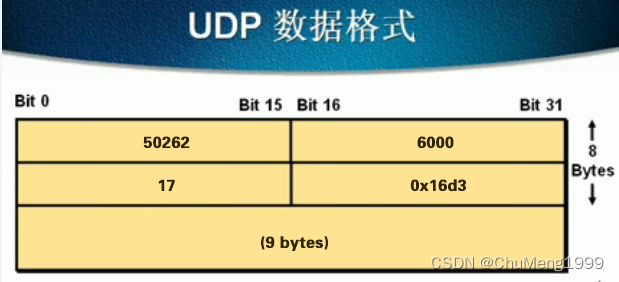
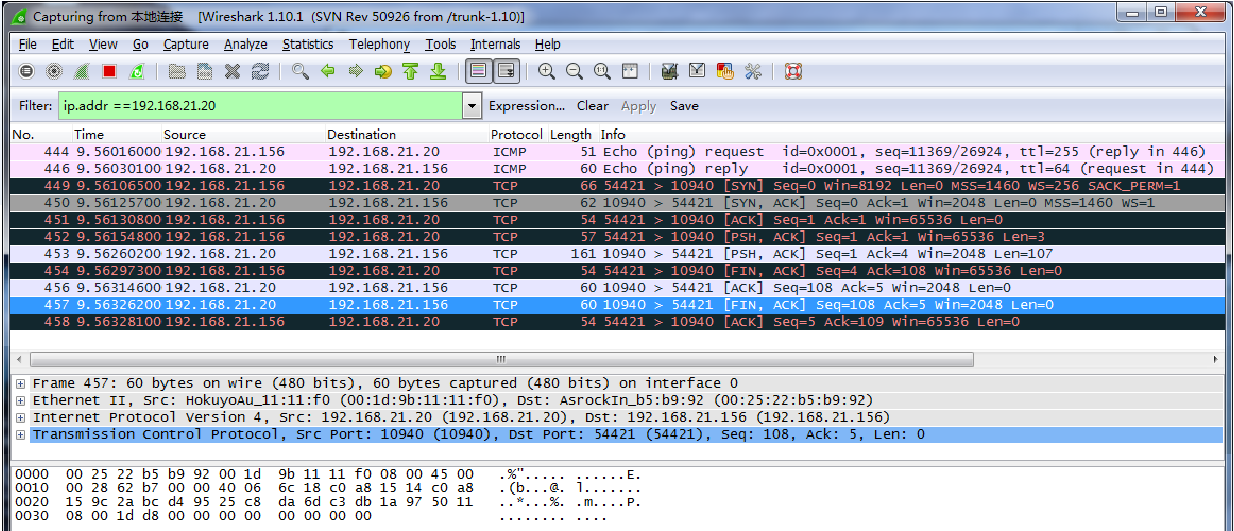
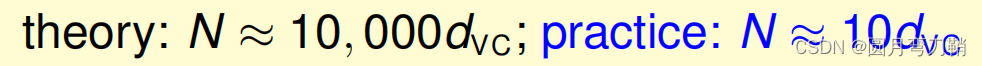参考资料:

除了redstone的笔记较好之外,还有豆瓣的https://www.douban.com/doulist/3381853/的笔记也比较好
--------------------------------------
1. 什么时候机器可以学习?
2. 为什么要要使用机器学习?
3. 机器怎么可以学习到东西?
4. 机器学习如何还能做的更好?
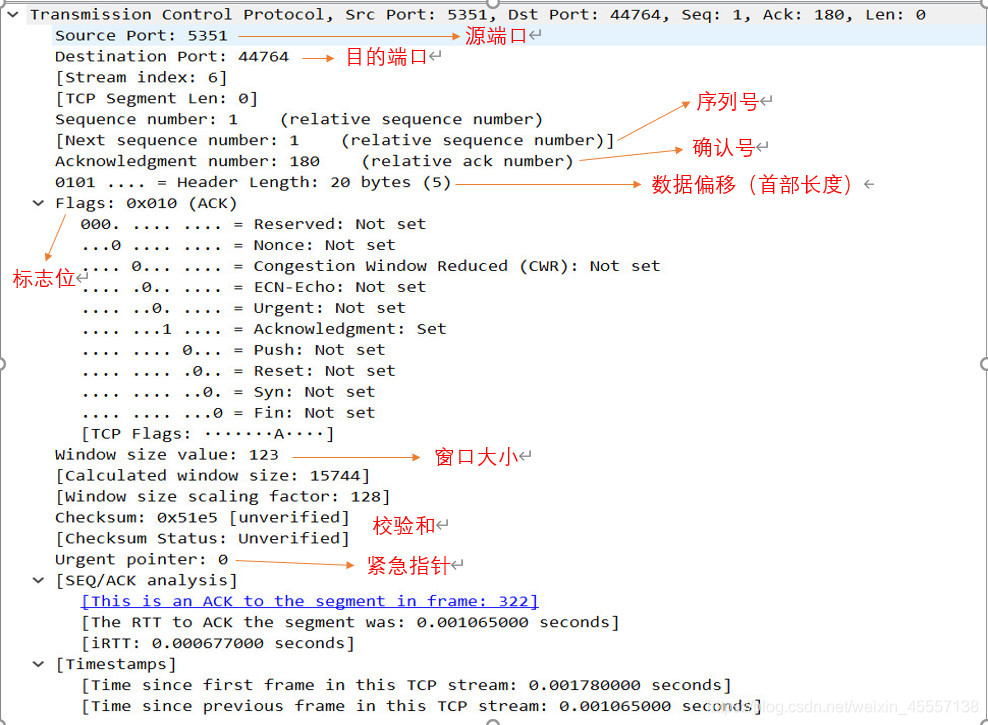
Lecture 1 The Learning Problem
豆瓣笔记:https://www.douban.com/note/319636155/
redstone笔记:https://redstonewill.com/65/
——————————————————————————
Lecture1 学习问题:
1. Courese Introduction 课程介绍
2. 什么是机器学习?
(1) 人类从观察→学习→skill;机器从数据→ML→skill (skill就是performance measure)机器学习的技能就是提高了性能指标,如预测准确性
(2) 为什么要使用机器学习呢?
如识别一棵树——设计可编程的规则去识别一棵树太复杂了,太难了。 3岁小孩是靠观察去认识一棵树的。所以机器也可以从数据中去学习认识一棵树。所以机器学习可以帮助建立复杂的系统。如在火星上做导航、语音识别、视觉识别、证券等高频交易、千人千面个性化推荐。
(3)机器学习的三个关键,判断是否能进行机器学习的三要素
a. 事务本身存在某种潜在规律,必须存在一个pattern模式可以学习。且有一个目标可以达到,如评价指标。
b. 这个pattern难以用简单的编程和设计规则来准确定义
c. 存在关于该pattern的足够数据
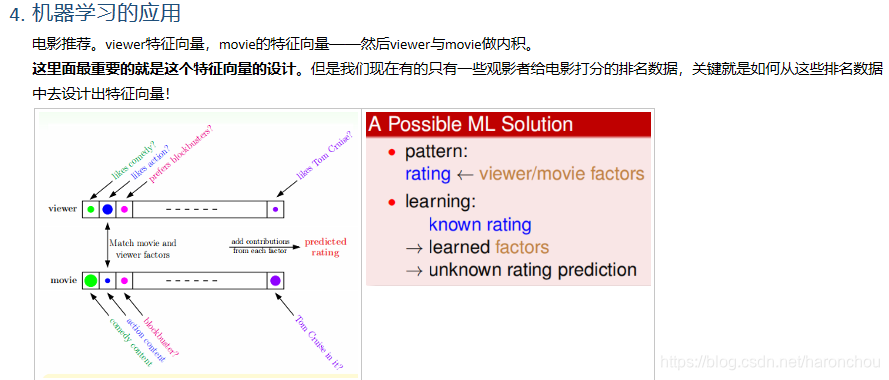
3. 机器学习的应用
举例:costomer向量与movie向量;关键:如何设计出特征向量!因为只要两个向量相关求和,就能知道。但是已知数据是排名,如何从数据中去设计出特征向量——特征工程,是最重要的!
4. 机器学习的组成部分
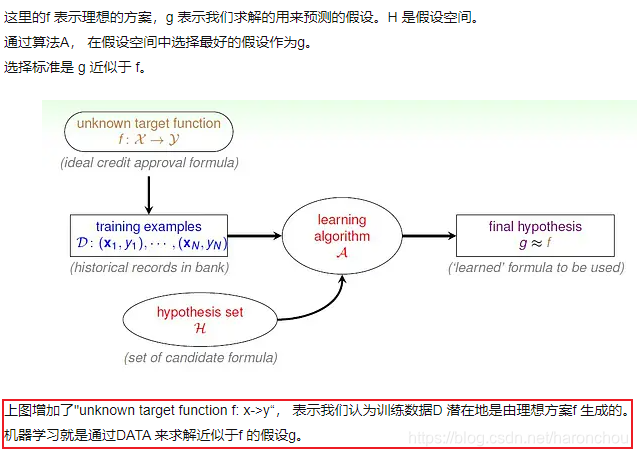
x, y, f, data, h, g.
机器学习两个输入:从理想目标函数f产生的训练数据D,假设集H。然后学习算法A在H中选择一个最好的g,g是近似于f的。
5. 机器学习与其他领域
——————————————————————————————






Lecture2 Learning to Answer Yes/No 机器学习如何做是非题?
豆瓣笔记:https://www.douban.com/note/319669984/
1. 感知机假设集:x features,w权重。h(x)=sign(wx),线性分类器
2. PLA算法:初始化w=0→找到一个分错的数据→调整w的权重:w=w+yi*xi→循环前两步,直到没有任何分类错误,迭代停止。
PLA算法一定能停止吗?一定能迭代终止吗?一定能收敛吗?一定能收敛到最优值吗?
3. PLA能否正常终止?分两种情况:数据线性可分 vs 数据线性不可分
(1)线性可分时:评价指标 内积 越大,wf和wt越接近。同时还要去除|wf|和|wt|的影响。发现其下限与迭代次数T有关,且有上限。所以随着迭代次数T的增大,内积越来越接近上限。即越来越达到收敛。所以PLA是可以迭代停止的
(2)数据线性不可分:Pocket Algorithm
迭代次数有限(提前设定);随机寻找分错的数据(而不是遍历循环);只有新得到的w比之前的wg要好,才更新权重。



T是迭代T次,所以T的迭代次数是有限的,因为有上限1.
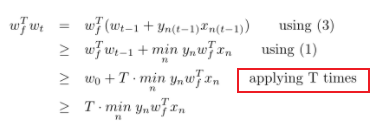




Lecture3 机器学习的种类
豆瓣笔记:https://www.douban.com/note/319684224/



Lecture4 机器学习学习的可行性分析
豆瓣笔记:https://www.douban.com/note/319700228/
1. 学习是可能的吗? NFL:不可能。因为不存在唯一解——必须要做出合理的假设才能有一个解。
2. PAC概率统计 N样本很大时,采样才能是PAC的。概率近似相等。h(x)与f(x)假设函数与目标函数才能是PAC的。霍夫丁不等式
3. PAC与学习的联系 N很大时,Ein≈Eout。才是PAC的,才能保证泛化能力。要让Eout很小,在PAC的前提下,让Ein小就可以了。所以PAC+Ein小=Eout小,保证泛化能力+训练误差较小。
4. 与实际学习的联系
Bad sample:很差的训练数据——将使得训练误差和泛化误差差别很大。
训练数据质量太差时,偏向于Ein=0的数据就会很多。这样就导致满足Ein的很多,但是Ein和Eout因为数据的原因差别很大,Bad Data的情况就很多。所以Bad Data的存在,在大量的假设h下,情况会更糟糕。
因此,我们希望我们面对的假设空间h,训练数据对于其中的任何假设h都不是Bad Data。
根据下面的公式:当M有限,N足够大时。我们能确保Bad Data的概率较小。Bad Data的概率PD(BAD D)一定要小。就需要控制M和N。
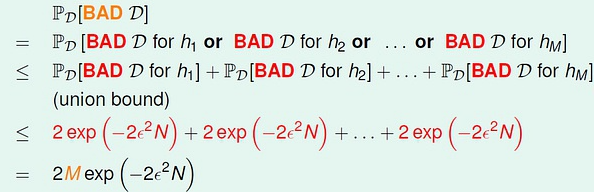
所以,当假设空间有限时(大小为M)时, 当N 足够大,发生BAD sample 的概率非常小。此时学习是有效的。
当假设空间无穷大时(例如感知机空间),我们下一次继续讨论。(提示:不同假设遇到BAD sample 的情况会有重叠)



Lecture5 Training vs Testing
豆瓣笔记:https://www.douban.com/note/323455696/ 
——————————————————
以下两条保证机器学习的可行性:H有限 + 训练数据N足够大——霍夫丁不等式,才不会出现Bad Data。
(1)M的大小至关重要。用一个有限的值mH(H)来代替M。因为假设之间有重叠,所以UnionBound估计过高。
(2)成长函数:mH(H)及其Break Point。样本量达到多少时,有mH(H)<2^N。
(3)用成长函数mH(H)可以代替M,下节课详细介绍。
---------------------------------------



Lecture6 Theory of Generalization 归纳理论
参考资料:https://zhuanlan.zhihu.com/p/59113933
豆瓣笔记:https://www.douban.com/note/323562697/
红色石头:https://redstonewill.com/217/
1. Break Point 突破点的限制
2. 边界函数 Bounding Function:Basic cases B(N,k) 等突破点为k时的最大mH(N)是多少。
3. 推导VC界:https://www.zhihu.com/question/38607822/answer/157787203
4. 只要Break Point存在(mH(H)的上限是k的多项式,所以M是有限的,N是足够大的),机器学习就是可行的。
VC bound:mH(N)。VC界是保证机器学习可行性的关键

Lecture7 VC维理论
https://www.douban.com/note/323572623/
https://redstonewill.com/222/
1. VC维的定义:假设空间H有突破点k,且N足够大,那么算法就有很好的泛化能力
2. VC维:假设集H能够shatter的最多inputs的种类数,即最大完全正确分类的能力。
3. VC维:VC维 == break point - 1
4. 一个假设集的dvc VC维确定了,就能满足机器学习的第一个条件 Eout=Ein,与算法、样本数据分布和目标函数都没有关系
5. 感知机的VC维:dvc == d + 1;
6. VC维的物理意义:反映了H的强大程度,VC维越大,H越强。可以打散更多的点,覆盖更多的样本分布情况。VC维与假设参数w的自由变量数目大约相等。dvc=d+1. d就是空间的自由度,也就是w的自由度。就是特征的维度。

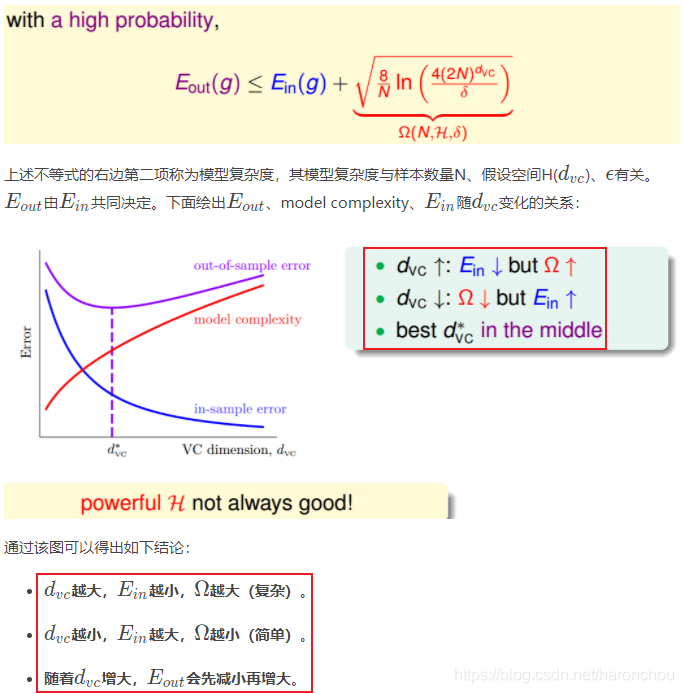
这就是对泛化能力最基本的保证:只要确定了假设集H的VC维。与算法、样本数据分布和目标函数都没有关系。


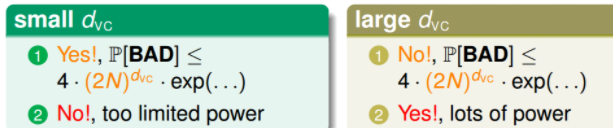
VC维太小,可以保证BadData概率降低;但是选择又太少,不容易实现第二点,即训练误差较小。
VC维太大,增加了Bad Data的概率;但是选择较多,容易得到训练误差较小的模型。
模型复杂度的惩罚:与样本数量、假设空间的VC维度和e都有关。