本节介绍了机器学习中三个重要原则,包括奥卡姆剃刀原理,样本偏差,数据窥探;并对16课程所学知识进行了总结。
系列文章
机器学习基石01:机器学习简介
机器学习基石02:感知器算法(Perceptron Algorithm)
机器学习基石03:机器学习的类型(Types of ML)
机器学习基石04:机器学习的可行性(Feasibility of ML)
机器学习基石05:训练与测试(Training versus Testing)
机器学习基石06:泛化理论(Theory of Generalization)
机器学习基石07:VC维(The VC Dimension)
机器学习基石08:噪声和误差(Noise and Error)
机器学习基石09:线性回归(Linear Regression)
机器学习基石10:逻辑回归(Logistic Regression)
机器学习基石11:线性模型分类(Linear Models for Classification)
机器学习基石12:非线性变换(Nonlinear Transformation)
机器学习基石13:过拟合风险(Hazard of Overfitting)
机器学习基石14:正则化(Regularization)
机器学习基石15:交叉验证(Cross Validation)
机器学习基石16:三个重要原则(Three Learning Principles)
文章目录
- 系列文章
- 16. Three Learning Principles
- 16.1 Occam's Razor
- 16.2 Sampling Bias
- 16.3 Data Snooping
- 16.4 Power of Three
- 三个应用领域
- 三个约束理论
- 三个线性模型
- 三个关键工具
- 三个重要原则
- 三项未来工作
16. Three Learning Principles
16.1 Occam’s Razor
entia non sunt multiplicanda praeter necessitatem(entities must not be multiplied beyond necessity) – William of Occam (1287-1347)
这边是奥卡姆剃刀原理(Occam’s razor)的出处。一句话总结:“如无必要,勿增实体。”
机器学习中 奥卡姆剃刀原理 的意思是 应尽可能选择简单的模型进行设计。
看一个模型选择例子:

左边的模型虽然可能有分错的情况,但模型简单,满足需求;右边的模型虽然都分类正确,但过于复杂。依据奥卡姆剃刀原理,选择左边的模型作为设计的模型。考虑以下两个问题:
- 简单模型中的“简单”是如何界定的?
- 为什么简单模型比复杂模型要好?(奥卡姆剃刀原理为什么在机器学习中适用?)
先看第一个问题:简单模型中的“简单”是如何界定的?

由上图可知,“简单”有两个方面:
- 对于单个假设函数 h h h 来说,参数越少意味着越简单。如上图中左边的分类超平面只用圆心和半径就能表达,因此参数很少,这就是“简单”的,而右边的超平面则过于复杂,包含很多高次项,参数量很多,因此并不“简单”;
- 对于假设空间 H H H 来说,有效假设的数量越少意味着越简单。
二者是密切相关的,一个假设空间 H H H 中的假设函数 h h h 的数量 ∣ H ∣ = 2 l |H| = 2^l ∣H∣=2l;如果假设空间 H H H 中的模型复杂度 Ω ( H ) \Omega(H) Ω(H) 很小,则假设函数的模型复杂度 Ω ( h ) \Omega(h) Ω(h) 也会很小。
接下来,看第二个问题:为什么简单模型比复杂模型要好?
假设一个数据集的规律性很差,如样本的标记都是随便标记的,此种情况,很少有甚至没有假设函数能使得该样本的 E i n ≈ 0 E_{in} \approx 0 Ein≈0 。如果一个数据集能被某个模型分开,则该数据集的规律性不会特别差。在使用简单模型将数据大致分开时,则可以确定该数据集是具有某种规律性的;如果用复杂模型将某数据集分开,则无法确定是数据集具有规律性还是模型足够复杂将数据集分开。因此,在实际应用中,应该尽量先选择简单模型,例如最简单的线性模型。
习题1:

16.2 Sampling Bias
用一个例子说明:1948年美国总统大选的两位热门候选人是Truman和Dewey。一家报纸通过电话采访,统计人们把选票投给了Truman还是Dewey。经过大量的电话统计显示,投给Dewey的票数要比投个Truman的票数多,所以这家报纸就在选举结果还没公布之前,信誓旦旦地发表了“Dewey Defeats Truman”的报纸头版,但结果却是Truman赢得了大选的胜利。
为什么会出现跟电话统计完全相反的结果呢?因为当时电话比较贵,有电话的家庭比较少,而有电话的人大多都支持Dewey,没有电话的人大多都支持Truman。也就是说样本选择偏向于有钱人那边,不具有广泛的代表性,才造成Dewey支持率更多的假象。
这个例子表明,抽样的样本会影响到结果,用一句话表示:如果抽样有偏差,则学习的结果也会产生偏差。这种情形称为 抽样偏差(Sampling Bias)。从技术上来说,就是训练数据和验证数据要服从同一个分布,最好都是独立同分布的,这样训练得到的模型才具有代表性。
习题2:

16.3 Data Snooping
之前提到过,在选择模型时,应该尽量避免数据偷窥(Data Snooping),因为这样会人为地倾向于某种模型,而不是根据数据进行随机选择。所以应该自由选取,最好不要偷窥原始数据。在使用数据的任何过程中,都算是间接地偷窥了数据,然后在进行模型的选择或者决策的时候,就会增加模型复杂度(model complexity),也就是引入了污染。下面举例说明。
假如有8年的货币交易数据,希望通过这些数据来预测货币的走势。前6年数据作为训练数据,后2年数据作为测试数据训练模型。输入20天的数据,预测第21天的货比交易情况。
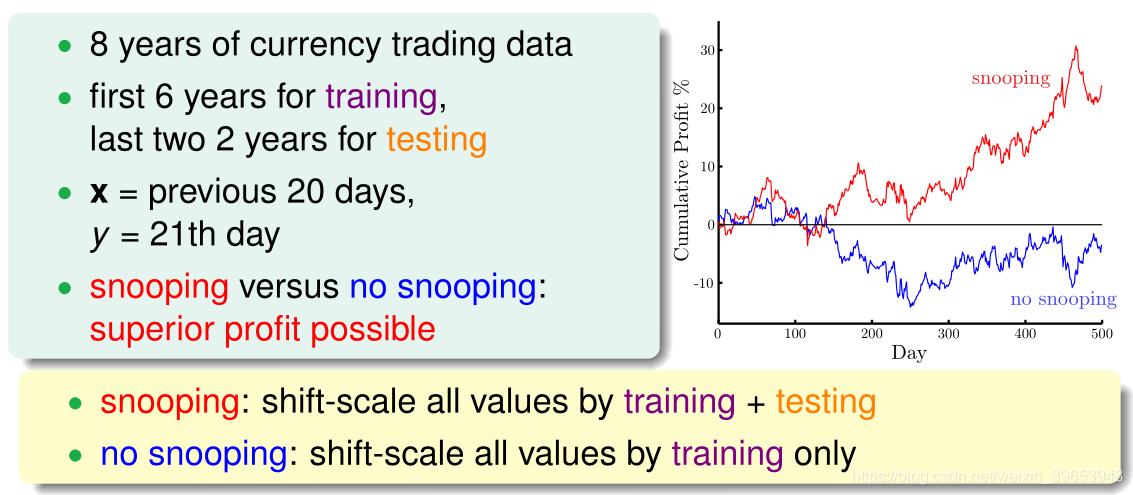
上图中,红线表示使用8年的数据建立模型预测后两年的收益情况;蓝线表示使用前6年的数据建立模型预测后两年的收益情况。
由图中曲线可知,使用8年数据进行训练的模型对后2年的预测的收益更大,似乎效果更好。但是这是一种自欺欺人的做法,因为训练的时候已经使用了后2年的数据,用这样的模型再来预测后2年的走势是不科学的。这种做法属于间接偷窥数据。
在机器学习过程中,避免“偷窥数据”非常重要,但完全避免很困难。实际操作中,有一些方法可以辅助避免偷窥数据。
- “看不见”数据。在选择模型的时候,尽量用经验和知识做选择,而不是通过数据选择。先选模型,再看数据。
- 保持怀疑。时刻保持对别人的论文或者研究成果保持警惕与怀疑,要通过自己的研究与测试来进行模型选择,这样才能得到比较正确的结论。

习题3:
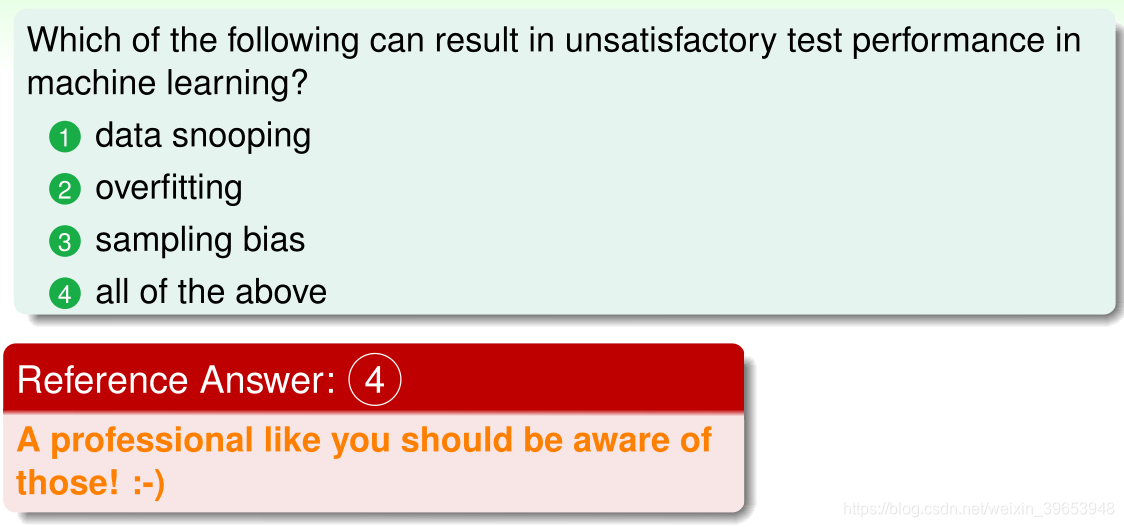
16.4 Power of Three
本部分是对机器学习基石系列课程(16节课程,每节4小节)的总结,课程介绍的内容都与数字“3”有关,小节题目因此得名。
本课程介绍了机器学习的如下内容:
三个应用领域

- 数据挖掘(Data Mining)
- 人工智能(Artificial Intelligence)
- 数理统计(Statistics)
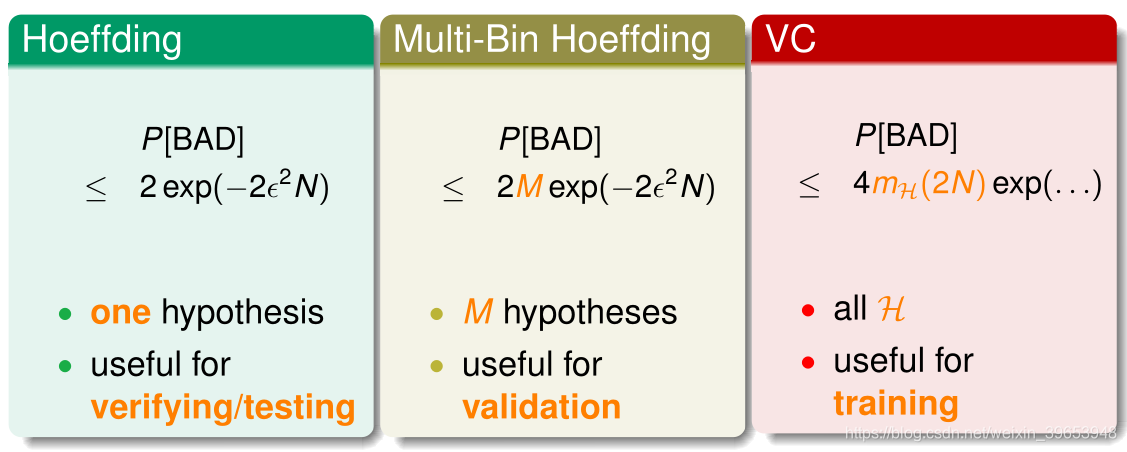
三个约束理论
- 霍夫丁不等式(Hoeffding)
- 多箱霍夫丁不等式(Multi-Bin Hoeffding)
- VC 限制理论
三个线性模型
- 线性感知器算法/pocket算法(PLA/pocket )
- 线性回归(linear regression)
- 逻辑回归(logistic regression)

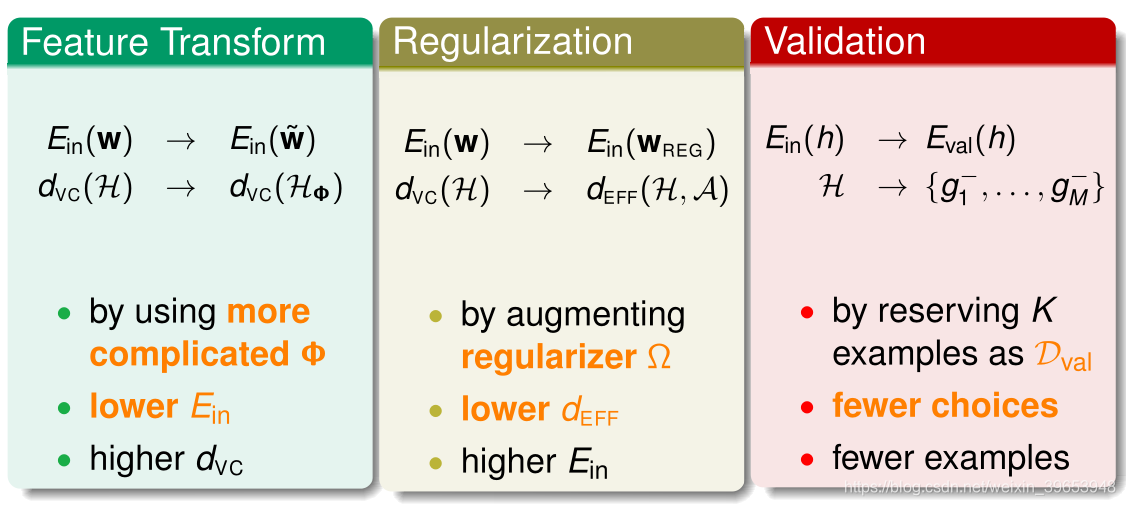
三个关键工具
- 特征变换(Feature Transform)
- 正则化项(Regularization)
- 交叉验证(Cross Validation)
三个重要原则
- 奥卡姆剃刀原理(Occam’s Razer)
- 样本偏差(Sampling Bias)
- 数据偷窥(Data Snooping)

三项未来工作

林轩田老师的机器学习基石课程笔记至此整理完结。
接下来会继续学习整理林老师的机器学习技法课程相关笔记。
参考:
https://www.cnblogs.com/ymingjingr/p/4306666.html
https://github.com/RedstoneWill/HsuanTienLin_MachineLearning