内网穿透的作用包括跨网段访问一个局域网中的一台主机。
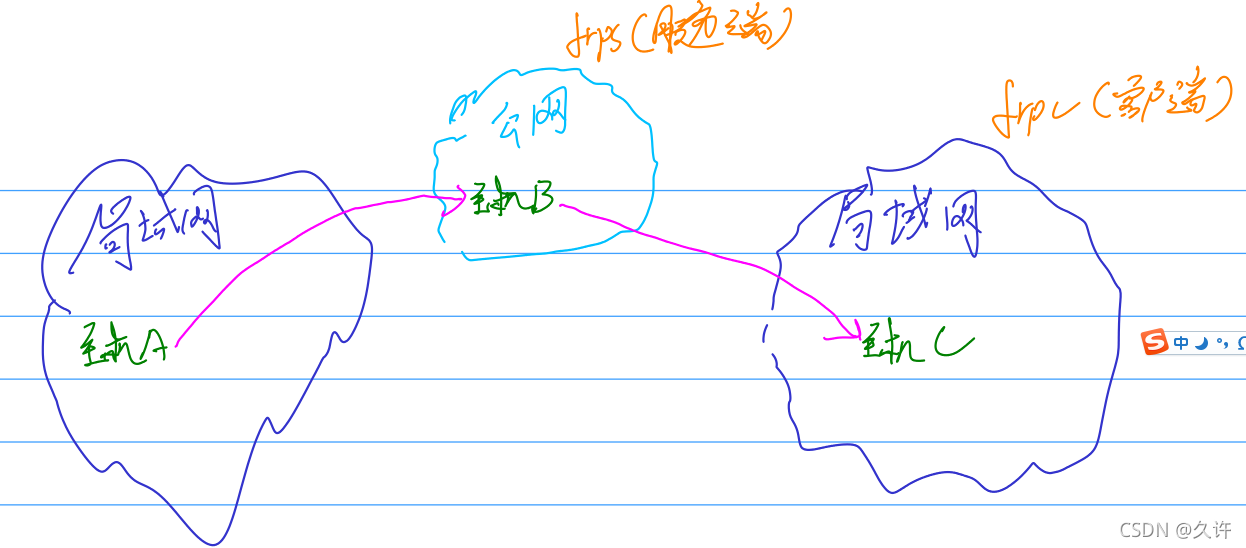
如上图,假设我们想要通过主机A访问主机C,但是主机A和主机C绑定的都是私有ip地址,所以它们之间是无法直接进行通信的。要想使得A和C能够进行通信,就需要用到内网穿透的技术。
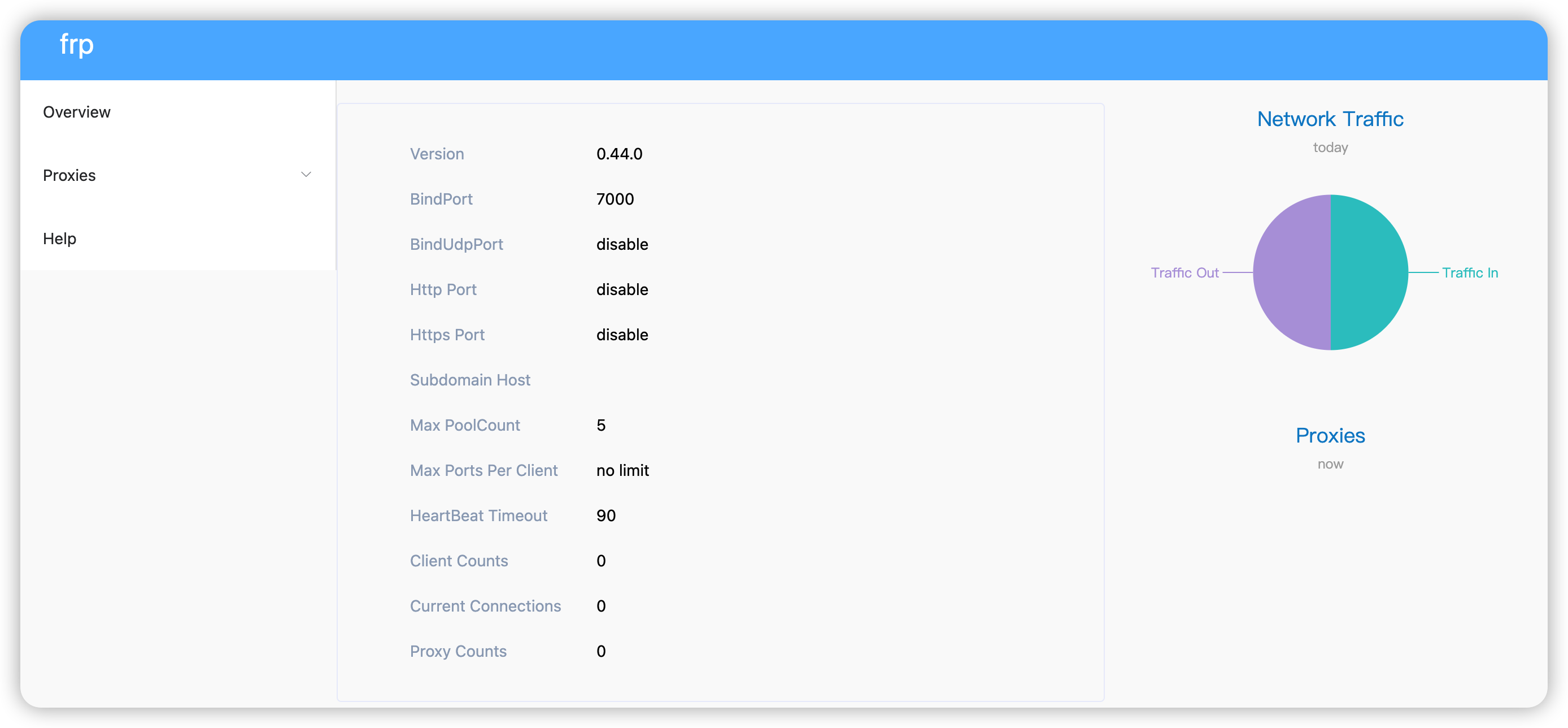
我们可以借助frps(服务端)和frpc(客户端)来实现主机A对主机C的访问。
需要做的是:
1.在绑定了公网ip的主机B中配置frps(服务端)
2.在主机C中配置frpc(客户端)
frps/frpc的工具包的github地址是:
Releases · fatedier/frp · GitHub
下载适合自己机器的版本即可。
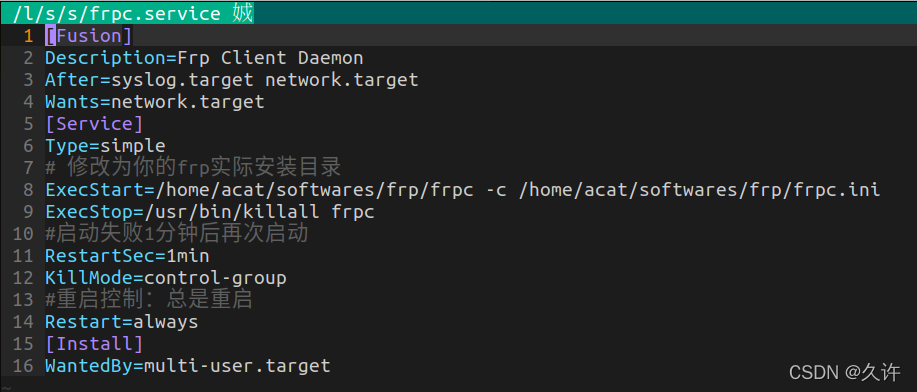
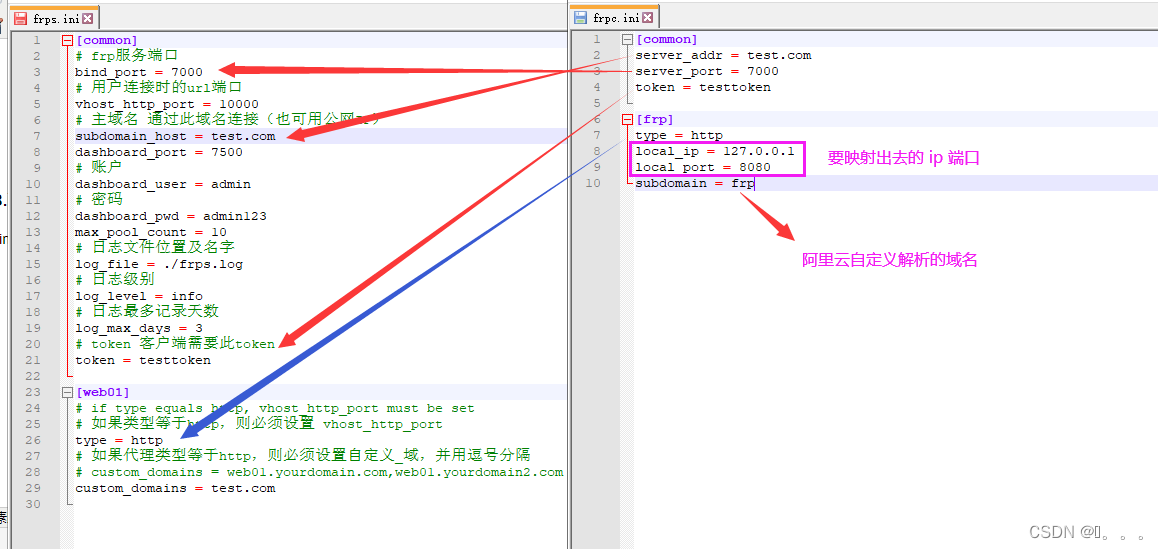
在服务端,即主机B中,编辑frps.ini文件:
[common]
bind_port = 7000
dashboard_port = 7500
dashboard_user = admin
dashboard_pwd = admin
authentication_method = token
token = pass123456然后可以启动服务端,切换到frps软件的解压目录之后,使用命令:
./frps -c frps.ini

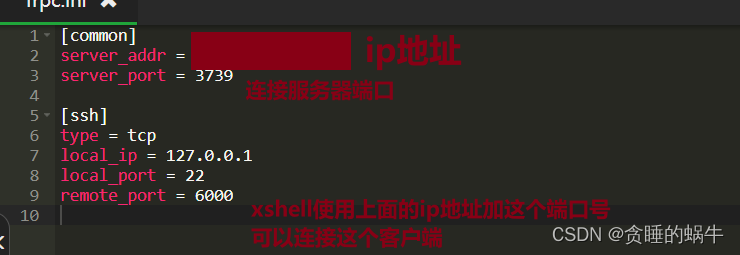
在客户端,即主机C中,编辑frpc.ini文件:
[common]
server_addr = x.x.x.x#公网ip地址
authentication_method = token
token = pass123456
server_port = 7000
[Fusion-ssh]
type = tcp
local_ip = 127.0.0.1
local_port = 22
remote_port = 20022
[Fusion-rdp]
type = tcp
local_ip = 127.0.0.1
local_port = 3389
remote_port = 23389客户端会根据frpc.ini文件中配置的server的ip以及port 与 服务端监听的7000端口进行连接
客户端使用命令连接到服务端:
./frpc -c frpc.ini
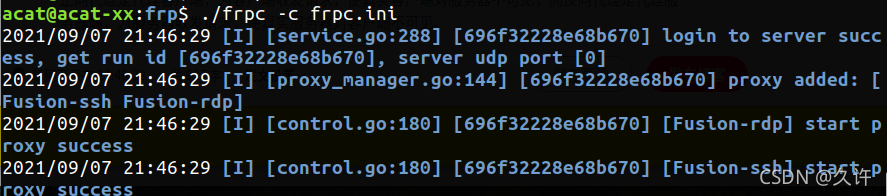
这里主机C(客户端)相当于是充当了反向代理的角色,而主机B(服务端)充当了正向代理的角色。
正向代理是代理客户端,为客户端收发请求,使真实客户端对服务器不可见;而反向代理是代理服务器端,为服务器收发请求,使真实服务器对客户端不可见。
因此,主机B用来接收主机A发送过来的请求,然后主机B将请求转发给主机C,从而主机A和主机C就能够进行通信了。
比如根据上面frpc.ini配置的ssh的内容,可知主机A通过ssh访问主机B的20022端口的时候,主机B会把该请求转发给主机C的22端口,因此主机A和主机C就建立了ssh的连接。
举例:
Windows中openssh的下载地址是:mls-software.com,安装完成之后,可以直接在powershell的命令行中调用ssh命令。
现在通过主机A(WIndows7)进行ssh访问,我们还知道主机B和主机C都是linux系统。
假设主机C中有两个用户,一个用户的用户名是acat,另一个用户的用户名是oracle,
那么ssh命令的格式是为: ssh -p 公网的转发端口 主机C的用户名@公网的ip
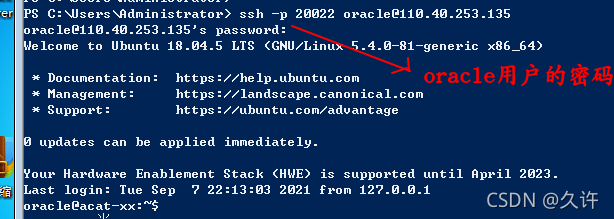
同样,可以使用SFTP协议传输文件,相当于是使用SCP命令来完成这种操作,因为SCP相当于是传输文件的过程中加了密。
命令格式:
把主机A(本地机器WIndows7)上的文件传到主机C:(注意这里的P是大写的)
scp -P 公网的转发端口 主机A文件路径 主机C用户名@公网ip地址:主机C文件路径

拉取主机C上的文件到主机A(本地机器Windows7)中:
scp -P 公网的转发端口 主机C用户名@公网ip地址:主机C文件路径 主机A的目录

PS:
配置为服务