讨论大数据架构,不可避免要讨论传统的结构化存储和数据仓库。
PS:最原始的结绳记事、仓颉造字不在咱们讨论范围内哈,咱们主要讨论计算机出现以后的数据存储 。
。

我们对数据存储方式的认知顺序一般是:

注意:这个演变过程,并不代表后者代替前者,每种方式都有其适合的应用场景,多种存储方式在一定时间内会是同时存在。他们的优缺点分析如下:
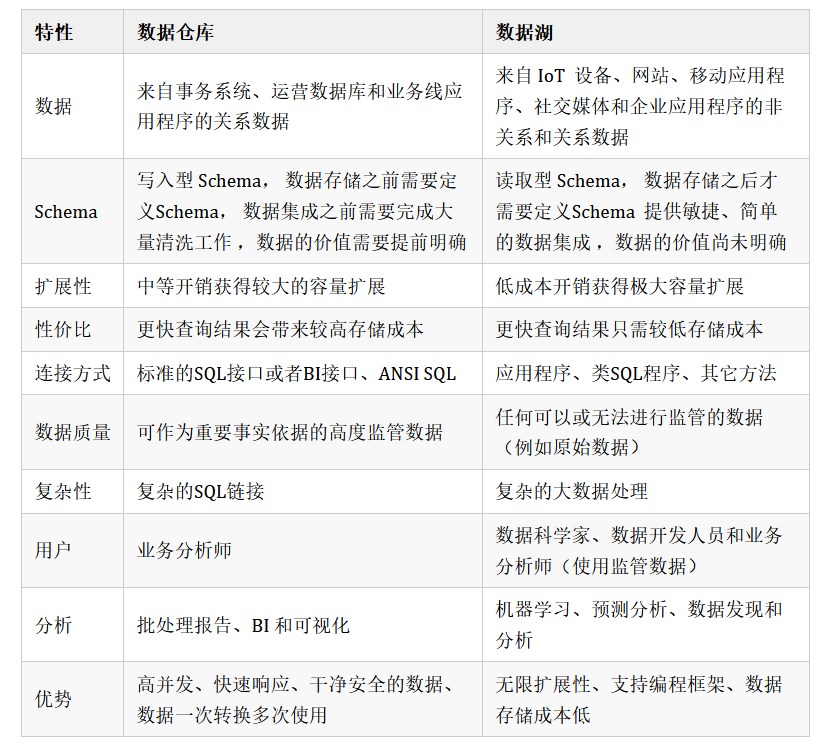
| 存储方式 | 简介 | 优点 | 缺点 |
| 结构化 数据库 | 也称作行数据库,使用二维表结构来逻辑表达现实中的信息。 | 通过事务保持数据一致性、数据可更新且开销很小,可以进行Join等复杂查询。 | 需sql解析,数据量大和高并发场景读写性能不足; 为保证数据一致性,加锁影响并发操作; 不能非结构化存储; 价格高、扩展复杂; 据说有个“阻抗失谐”问题,自行脑补吧。 |
| 数据仓库 | 面向主题的、整合的、随时间变化的、相对稳定的历史数据集合,支撑历史的、分析的和商务智能的数据需求。 | 面向主题 效率比较高 数据质量较高 扩展性较高 ... | 数据集中存储,查找和编译时比较长; 技术难度造成人员成本高; 采购硬件和软件成本较高; |
| 大数据 | 存储、管理、分析超出了传统数据库软件工具能力范围的数据集合,具有海量、多样性、价值密度低、处理速度快、真实性的特性。 | 提高生产力 降低硬件成本 更好的决策 改善客户服务 更好的创新 ... | 基础架构和数据分析方面面临诸多挑战。 资源利用率低 应用部署复杂 运营成本高 高能耗等 |

抛开结构化存储和数据仓库,咱们重点讨论大数据架构。
针对传统数据存储方式的种种缺陷,近些年出现了多种解决方案,其中以Hadoop体系为首的大数据分析平台逐渐表现出优异性,围绕Hadoop体系的生态圈也不断的变大。对于Hadoop系统来说,基本上解决了传统数据仓库的瓶颈问题,但是也带来一系列的问题(没有完美的架构,只有合适的架构):
(1)从数据仓库转到大数据架构,多数不能平滑演进,基本等于推翻重做。
(2)大数据下的分布式存储强调数据的只读性,类似于Hive,HDFS这些存储方式都不支持update(或不擅长),写操作对并行的支持也不是很好,这些特性导致其应用场景具有一定的局限性。

大数据架构也不能够满足任何场景使用,那么一般在什么场景使用大数据架构呢?
| 应用场景 | 场景描述 |
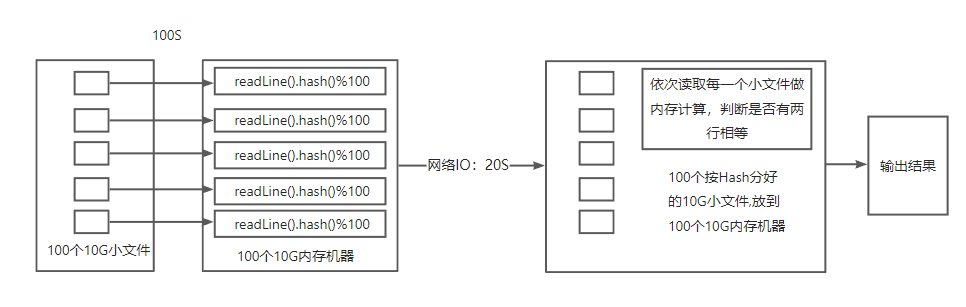
| 分布式 存储 | 业务开展过程中会频繁生成较大的文(几百M),而且数量比较多(如各种日志数据、传感器数据、GPS数据、视频监控数据等)的场景。这些数据放在传统存储上使用存在较多问题。 可将一个大文件拆成N份,每一份独立的放到一台机器上。这里就涉及到1个文件的分片、分副本的管理。提高存储和使用的性能,分布式存储的主要优化点基本都在这一块。 |
| 分布式 计算 | 对于涉及大量数据计算的场景,由于CPU、内存等硬件限制无法在一个节点上完成。可以使用分布式计算框架,让多个节点并行计算,并且强调数据本地性,尽可能的减少数据的传输。例如Spark(一种常用的分布式计算框架)通过RDD(一个分布式待计算的数据对象集合)的形式来体现数据的计算逻辑,可以在RDD上做一系列的操作(转换和输出),来减少数据的传输,让大规模计算成为可能。 |
| 检索和存储的结合 | 大数据的存储和后续数据处理是密不可分的,不能只考虑存储的优化,也不能只顾着数据处理起来方便。 目前的趋势是:通过在存储上进行优化,让查询和计算更加高效。因为对于计算来说高效主要是查找数据快、读写数据快,所以目前的存储方式,不只是存储数据本身,同时会存储和数据相关的元信息,以提高数据的读写性能。例如索引信息(如:hdfs、elasticsearch都是采用该思想)。
|
上面这几种场景,在oracle, sql server, mysql, postgresql 等传统数据存储技术上是比较难部署和应用的。数据量少,规模控制在5-10 台还能接受(管理和运维基本还能跟的上),100台以上集群,管理难度和成本会急剧加速。所以大数据的出现是数据爆炸时代的必然,也是趋势。了解和学习大数据是必须的,一起加油 ,把大数据拿下,成为大数据时代的弄潮儿
,把大数据拿下,成为大数据时代的弄潮儿 。
。

上面讨论了,大数据比较适合的几种业务场景,那么大数据一般有哪些架构模式,来满足这些场景呢。
喂!别走神,了解常用架构是了解大数据全貌的基础,是下一步学习大数据经典组件技术的前提,一定要认真理解。不然后面关于各个组件的讨论,都不知道为什么要学、要用这些组件,各个组件都位于大数据中的哪个环节。
言归正传,咱们开始讨论大数据的经典架构。
1、传统大数据架构
传统架构(比较早期的架构),为了解决传统数据仓库(一般用于BI业务)存在问题。数据分析的业务场景没有什么变化,但随着数据量、用户量的增加带来一系列的管理和性能问题导致原有系统不好使用(或根本无法正常使用),需要进行架构升级改造,传统大数据架构就是为了解决这个问题。
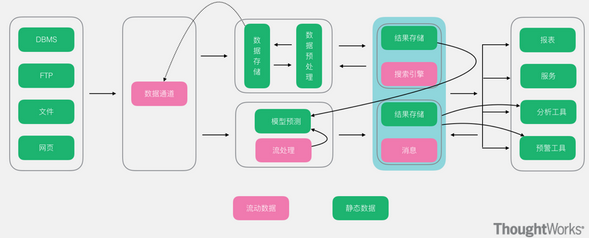
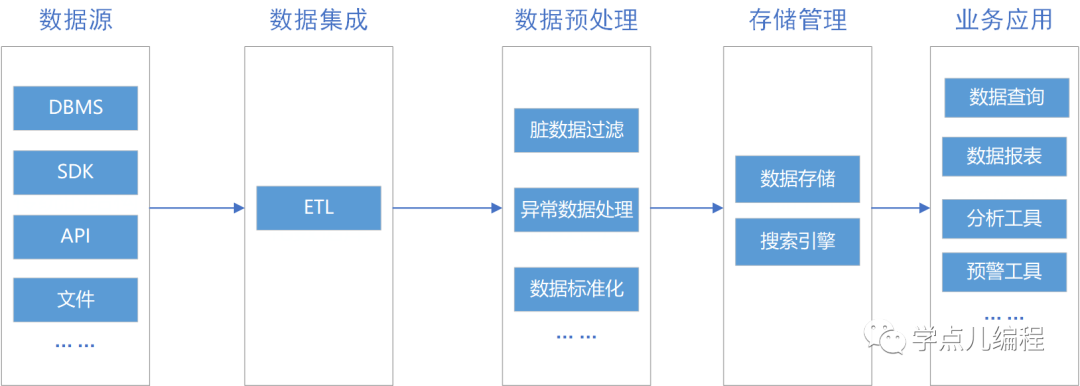
也有人比较直接的,直接称该架构为 数据仓库+hadoop。从下面图中,可以看到该架构中有ETL处理,数据经过ETL处理后进行数据存储。
说明:
数据存储使用传统的数据仓库和分布式存储(如HDFS)来实现。
原数据仓库能支撑的展现、分析工作仍然通过连接数据仓库实现;
需要大量计算的场景,通过连接分布式存储来实现;
数据仓库和分布式存储之间通过数据传输组件(如:sqoop)来做数据传输的通道。
| 优点 | 简单、容易迁移 对于传统的数据仓库(主要用于BI)BI系统来说,总体思想和数据处理流程基本没有什么变化,对于BI的使用者来说也分析功能和操作方式也基本没有变化。变化的内容主要是在数据处理阶段技术选型的改变,增加了大数据处理技术。 对于原有架构仍然能满足的数据展现、数据分析工作继续通过连接数据仓库实现;对于涉及海量数据,需要分布式存储和计算的场景,直接连接hadoop实现。 |
| 缺点 | 对于大数据架构,虽然解决了海量数据的存储和计算。但在数据分析灵活度和稳定性上(如:对SQL的支持能力),还没有达到BI对业务支撑的程度。 对于存在大量报表或复杂钻取的场景,经常需要定制化开发,同时以离线批处理为主,缺乏实时性的支撑。 |
| 适用 场景 | 业务中数据分析的需求仍然以BI场景为主。 但是存在因为数据量、性能等问题无法满足日常使用的场景。 |
说明:
了解大数据,不可避免需要接触数据仓库。
为了照顾以前没接触过、或接触数据仓库少的朋友。接下来,我会专门写一篇关于数据仓库的的文章。
2、流式数据处理架构
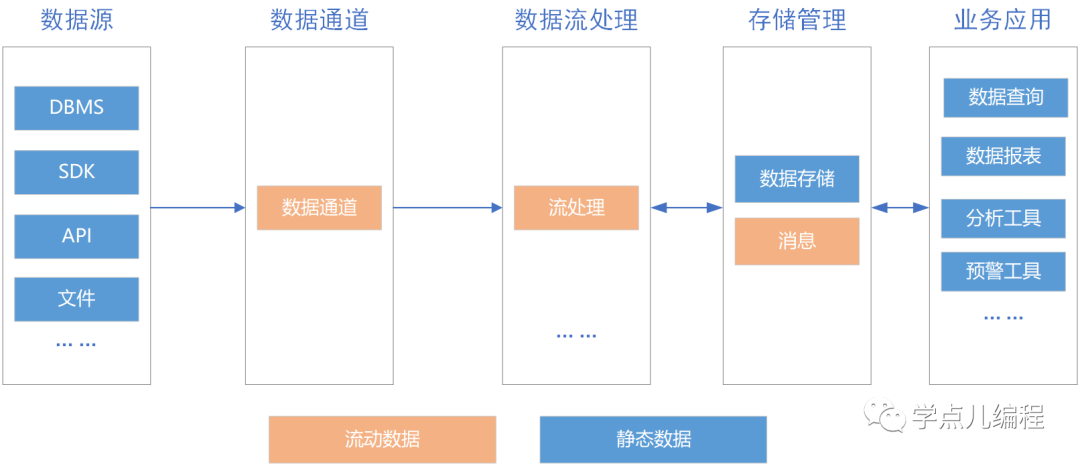
和传统大数据架构相比,流式架构非常激进,直接去掉了批处理,换为数据全程以数据流的形式处理。
在数据接入端没有了ETL过程,而是换为数据通道。经过流处理后的数据,以消息的形式推送给消费者。
数据处理过程中,也涉及一部分数据的存储,这部分数据主要以窗口的形式进行存储和处理。
| 优点 | 没有复杂的ETL过程,也不进行海量数据批处理。 数据的处理的实效性非常高。
|
| 缺点 | 对于流式架构来说,他的优点也是他的缺点。 没有批处理,对于数据重复数据和历史统计无法很好的支撑。 对于数据的逻辑处理、分析、统计以窗口内的数据为主分析。
|
| 适用 场景 | 预警、监控等业务场景,特别是对数据有“有效期”要求的场景。 |
3、Lambda架构
因为Lambda架构同时兼顾了实时处理和批处理,所以Lambda架构在大数据中有举足轻重的位置,基于Lambda架构衍生出了多种优秀大数据架构。
Lambda的数据通道分为两条分支:实时流和离线。
实时流依照流式架构,通过增量计算保障了其实时性;
离线则以批处理方式为主,通过全量运算保障了最终一致性。
| Lambda 是充分利用了 批次(batch) 处理和 流处理(stream-processing)各自强项的数据处理架构。它平衡了延迟,吞吐量和容错。我们既可以看到即时的数据,又可以看到历史的聚合数据。 (1)利用批次处理生成正确且深度聚合的数据视图,同时借助流式处理方法提供在线数据分析。 (2)在展现数据之前,可以将两者结果融合在一起。 注意: Lambda依赖于只增不改的数据源。历史数据是稳定不变的历史数据,变化着的数据永远是最新进来的,并且不会重写历史数据。 |
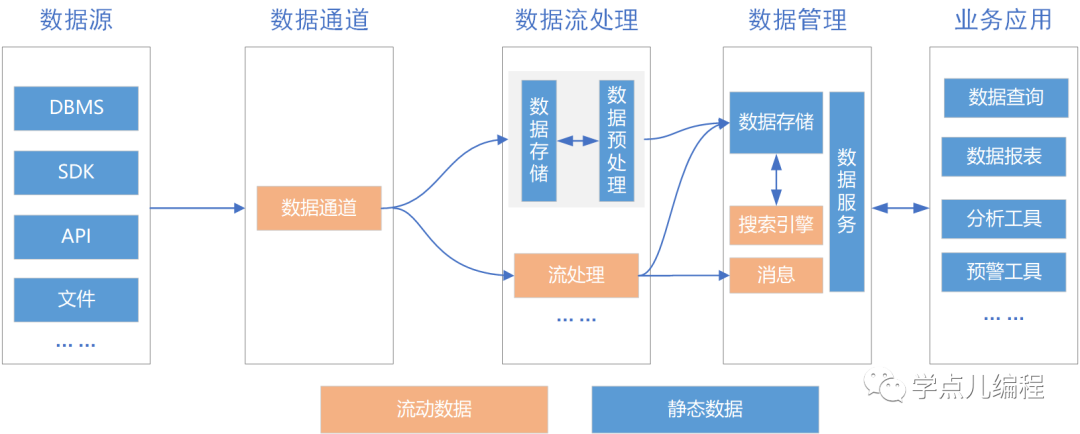
Lambda包括三部分:批次处理(batch), 高速处理也称为实时处理(speed or real-time),和响应查询的服务层(serving)。服务层实现实时层和离线层数据的合并,此操作是Lambda中很重要的一个处理。
| 常用的技术组合为: (1)高速处理层:用实时计算的手段,将数据集成到存储端。虽然没有最终的批次处理来的完整和精确,但弥补了批次处理的时效差的弱点。 (2)批处理层:利用分布式系统的强大处理能力,提供了可靠准确无误的数据视图。一旦发现错误的数据,即可重新计算全部的数据来获得最新的结果。 常用技术组件:Hadoop 被视为这类高吞吐架构的标准。 (3)响应查询的服务层:服务于终端数据消费者的数据查询和分析。最终计算结果存储到本层后,就可以对外服务了。 常用的技术组件:
|
PS:存在一种说法,基于传统的数据处理组件也可以实现Lambda 架构,了解一下即可(非主流)。技术组合如下:
-
批处理层:使用商用的ETL 工具(如 SSIS, Informatic 等)
-
实时处理层:使用消息总线(如RabbitMQ, ActiveMQ等)
我觉得只能说,是部分实现,但费用和运维成本也是比较高的。以Hadoop 为代表的分布式系统,才有资格称得上是 Lambda 架构的组成。利用分布式系统的强大处理能力,提供了可靠准确无误的数据视图。
| 优点 | 既有实时又有离线,满足多种数据分析场景。
|
| 缺点 | 技术复杂性较高。运维成本较高。
|
| 适用场景 | 同时存在实时和离线需求的场景。 |
4、Kappa架构
Kappa架构是在Lambda的基础上进行了优化(更加侧重于实时处理了)。
(1)将实时和流部分进行了合并。
(2)将数据通道以消息队列进行替代。
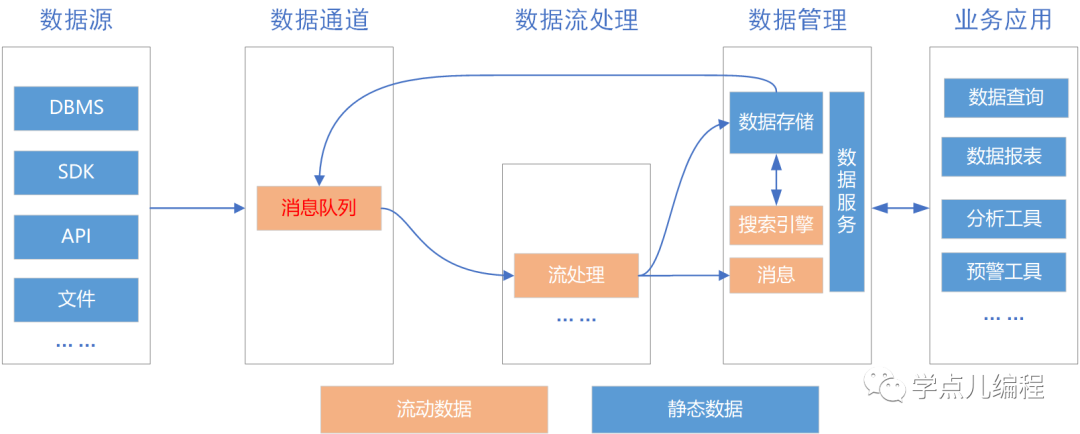
特点:以流处理为主(但是,数据在分布式存储中进行了存储),当需要进行离线分析或者再次计算的时候,将数据再次经过消息队列处理一次则可。
(1)所有数据都走实时路线,一切都是流。并且以分布式存储作为最终存储目的地。本质上还是以 lambda为基础,只是将批次处理层(Batch Layer ) 去掉,剩下 实时处理和数据服务层。
(2)Kafka 在该架构中扮演了实时分发数据的角色,它的快速,容错和水平扩展能力都表现非常出色。
| 优点 | 相对于Lambda架构,Kappa架构非常简洁。
|
| 缺点 | 实时计算和批处理过程使用的是同一份代码,逻辑复杂。 实施难度较大。 |
| 适用场景 | 和Lambda类似,该架构是针对Lambda的优化。 |
5、Unified 架构
上面几种架构主要是围绕海量数据处理为主,Unified架构则是将机器学习和数据处理揉为一体。
从架构核心上,Unified还是以Lambda为主,进行了改造(在流处理层新增了机器学习层)。可以看到数据在经过数据通道进入数据湖后,新增了模型训练部分,并且将其在流式层进行使用。同时流式层不单使用模型,也包含着对模型的持续训练。
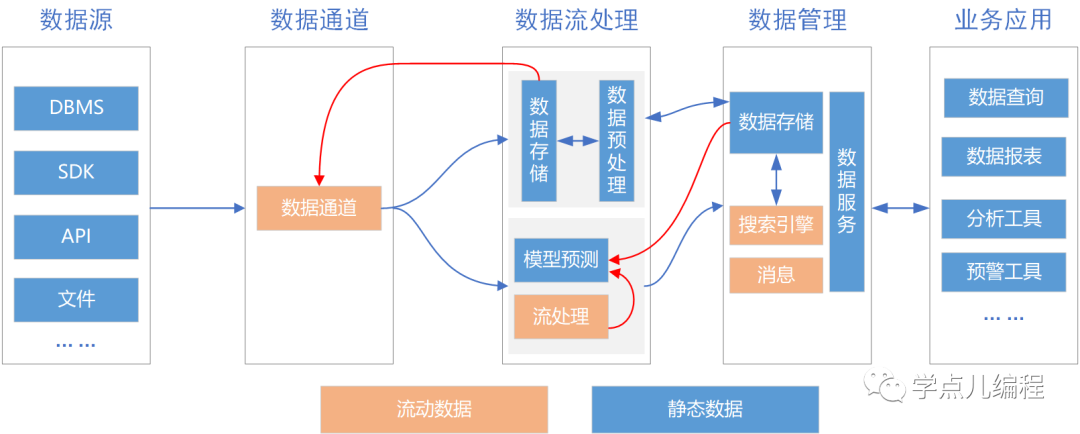
-
Lambda 架构:兼容了 批处理、实时流处理。
-
Kappa 架构:使用实时流处理全程处理实时数据和历史数据。
-
Unified 架构:利用统一的 Api 框架,兼容了批处理和实时流处理。
在 Hadoop 生态圈系统中,由于分布式文件系统没有对批处理、实时流处理、数据服务 三个层的一致性支持,所以想要基于 Hadoop 做统一存储管理就比较困难。
据说,有个名为“bufferfly architecture”的框架,实现了基于每一层的存储做灵活的计算处理抽象,使得存和取都使用同一套软件框架。多种计算框架(如:MPP SQL (Impala,Drill,HAWQ), MapReduce, Spark, Flink, Hive, Tez)可以同时访问这些存储抽象中的数据(如:datasets, dataframes 和 event streams)。感兴趣的可以自行脑补。
| 一个讨论:为什么有了 Kappa 架构还需要 Unified Lambda 架构呢? Kappa 架构使用实时处理技术,既满足了高速实时处理需求,还兼顾了批次处理的场景。那么kappa 的缺陷是什么呢? (1)kappa 的批次处理能力可能不如 Lambda 架构下的 MapReduce。 Lambda 架构下MapReduce的处理优势是:存储和计算节点扩展容易,离线处理成功率高,而且每一步的 Map/Reduce 都有可靠的容错能力,在失效场景下恢复数据处理够快。这些对于实时处理程序 Storm/Flink/Spark,可靠性可能相对差一些(关键还得看 配置参数)。 (2)Kappa批次处理的硬件成本可能比纯粹的批次处理架构要高。 (3)Unified Lambda架构可提供一套统一的API来执行批处理和实时流处理。综合了Kappa的优势,还克服了 Kappa 的劣势(流式处理容易出错和高成本)。 |
| 优点 | 提供了一套数据分析和机器学习结合的架构方案,解决了机器学习与数据平台的结合问题。
|
| 缺点 | 实施复杂度更高(如:机器学习相关软件、硬件的部署)。 |
| 适用 场景 | 有大量数据需要分析,同时对机器学习有着较大需求(或规划)的场景。 |

上面是目前数据处理领域使用较多的几种架构,相关的、延伸的还有非常多其他架构(要疯了 ),不过数据处理思想都多少有相似的地方。
),不过数据处理思想都多少有相似的地方。
大数据领域和机器学习领域在快速发展,数据处理是个很广的领域,我们只能与时俱进,不断更新自己的知识库。
上面的架构模式,指出了常见的数据处理流程和方式。实际工作中,一般不会硬套上面的架构模式,根据业务需求选择合适的数据处理方式。没有完美的架构,只有合适的架构。
对于大数据架构的相关问题,欢迎大家留言讨论。

了解了常用的大数据架构,接下来开始讨论流行的、重要的的大数据组件。首先要介绍的当然就是动物园管理员啦。敬请期待。
如果觉得这篇文章对您有帮助,欢迎关注公众号 “学点儿编程”,公众号不断推送干货文章!