一、什么是Kappa架构
Kappa 架构是由 LinkedIn 的前首席工程师杰伊·克雷普斯(Jay Kreps)提出的一种架构思想。克雷普斯是几个著名开源项目(包括 Apache Kafka 和 Apache Samza 这样的流处理系统)的作者之一。
Kreps 提出了一个改进 Lambda 架构的观点:
-
通过改进 Lambda 架构中的Speed Layer,使它既能够进行实时数据处理,同时也有能力在业务逻辑更新的情况下重新处理以前处理过的历史数据
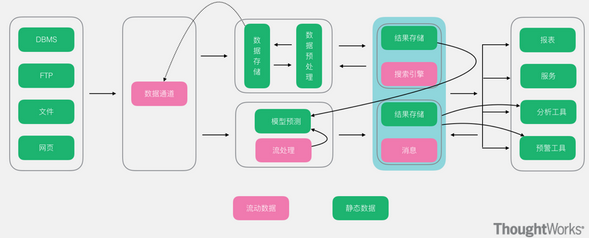
Kappa架构的原理是:在Lambda 的基础上进行了优化,删除了 Batch Layer 的架构,将数据通道以消息队列进行替代。因此对于Kappa架构来说,依旧以流处理为主,但是数据却在数据湖层面进行了存储,当需要进行离线分析或者再次计算的时候,则将数据湖的数据再次经过消息队列重播一次则可。

二、Kappa架构组成
1.基本概念

1)消息传输层(Speed Layer)
消息传输层提供接收和存储流数据的消息队列,数据可以在某个需要限度内全量存储,并在必要时从头开始读取重新计算,从而获得可靠结果。
消息传输层通常具有以下特点:
-
持久性------数据可任意设定存储时间
-
分布式------数据分布式存储
-
数据可重放------数据可以被replay,从头重新处理
-
高性能------能够提供高性能数据读写访问
2)流处理层(Serving Layer)
流处理层提供流计算引擎,用于进行流分布式实时计算。
流处理层通常具有以下特点:
-
低延迟------保证快速响应
-
高吞吐------同时处理庞大数据量
-
具有容错与恢复能力------保证系统稳定可用
-
一致性保证------适用任何强一致性需求的应用(如金融级需求)
3)流处理核心思想
1.用Kafka或者类似MQ队列系统收集各种各样的数据,你需要几天的数据量就保存几天。
2.当需要全量重新计算时,重新起一个流计算实例,从头开始读取数据进行处理,并输出到一个新的结果存储中。
3.当新的实例做完后,停止老的流计算实例,并把老的一些结果删除。
2. Kappa架构优点
Kappa架构的优点在于将实时和离线代码统一起来,方便维护而且统一了数据口径的问题。
3. Kappa架构缺点
-
流式处理对于历史数据的高吞吐量力不从心:所有的数据都通过流式计算,即便通过加大并发实例数亦很难适应IOT时代对数据查询响应的即时性要求。
-
开发周期长:此外Kappa架构下由于采集的数据格式的不统一,每次都需要开发不同的Streaming程序,导致开发周期长。
-
高度依赖实时计算系统的能力:在实时数据处理时,遇到大量不同的实时流进行关联时,非常依赖实时计算系统的能力,很可能因为数据流先后顺序问题,导致数据丢失。
-
服务器成本浪费:Kappa架构的核心原理依赖于外部高性能存储redis,hbase服务。但是这2种系统组件,又并非设计来满足全量数据存储设计,对服务器成本严重浪费。
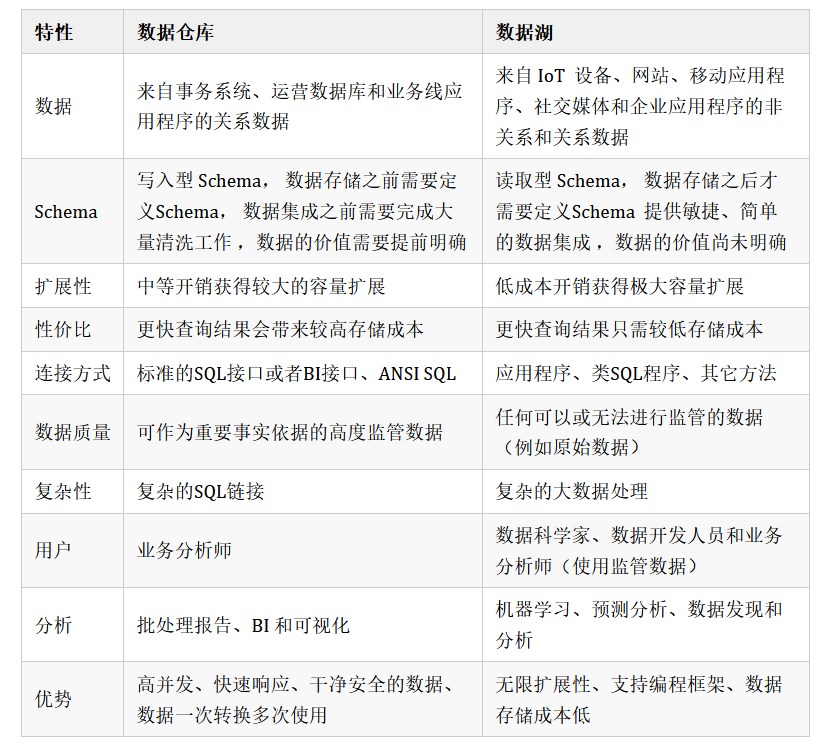
4.Lambda架构和Kappa架构的对比
| 优点 | 缺点 | |
|---|---|---|
| lamba | 1)架构简单 2)很好的结合了离线批处理和实时流处理的优点 3)稳定且实时计算成本可控 4)离线数据易于订正 | 1)实时,离线数据很难保持一致结果 2)需要维护两套系统 |
| kappa | 1)只需要维护实时处理模块 2)可以通过消息重放 3)无需离线实时数据合并 | 1)强依赖消息中间件缓存能力 2)实时数据处理时存在丢失数据可能 |
| 对比项 | Lambda | Kapppa |
|---|---|---|
| 实时性 | 实时 | 实时 |
| 计算资源 | 批和流同时运行,资源消耗大 | 只有流处理,资源开销小 |
| 重新计算吞吐量 | 批式全量处理,吞吐较高 | 流式全量处理,吞吐较批式全量要低一些 |
| 开发、测试难度 | 系缚 个需求都需要批处理和流处理两励磁代码,开发,测试,上线难度大一些 | 只需实现一套代码,开发,测试,上线难度相对较小 |
| 运维成本 | 维护两励磁系统(引擎),运维成本大 | 维护一套系统(引擎),运维成本较小 |
三、Kappa架构选型
1. Kappa架构模型

与 Lambda 架构不同的是,Kappa 架构去掉了批处理层这一体系结构,而只保留了速度层。你只需要在业务逻辑改变又或者是代码更改的时候进行数据的重新处理。
2.Kappa架构处理逻辑

-
部署 Apache Kafka,并设置数据日志的保留期(Retention Period)。这里的保留期指的是你希望能够重新处理的历史数据的时间区间
-
例如,如果你希望重新处理最多一年的历史数据,那就可以把 Apache Kafka 中的保留期设置为 365 天。
-
如果你希望能够处理所有的历史数据,那就可以把 Apache Kafka 中的保留期设置为“永久(Forever)”
-
-
如果我们需要改进现有的逻辑算法,那就表示我们需要对历史数据进行重新处理
-
我们需要做的就是重新启动一个 Apache Kafka 作业实例(Instance)。这个作业实例将从头开始,重新计算保留好的历史数据,并将结果输出到一个新的数据视图中。
-
我们知道 Apache Kafka 的底层是使用 Log Offset 来判断现在已经处理到哪个数据块了,所以只需要将 Log Offset 设置为 0,新的作业实例就会从头开始处理历史数据。
-
-
当这个新的数据视图处理过的数据进度赶上了旧的数据视图时,我们的应用便可以切换到从新的数据视图中读取。
-
停止旧版本的作业实例,并删除旧的数据视图。
3.组件选型

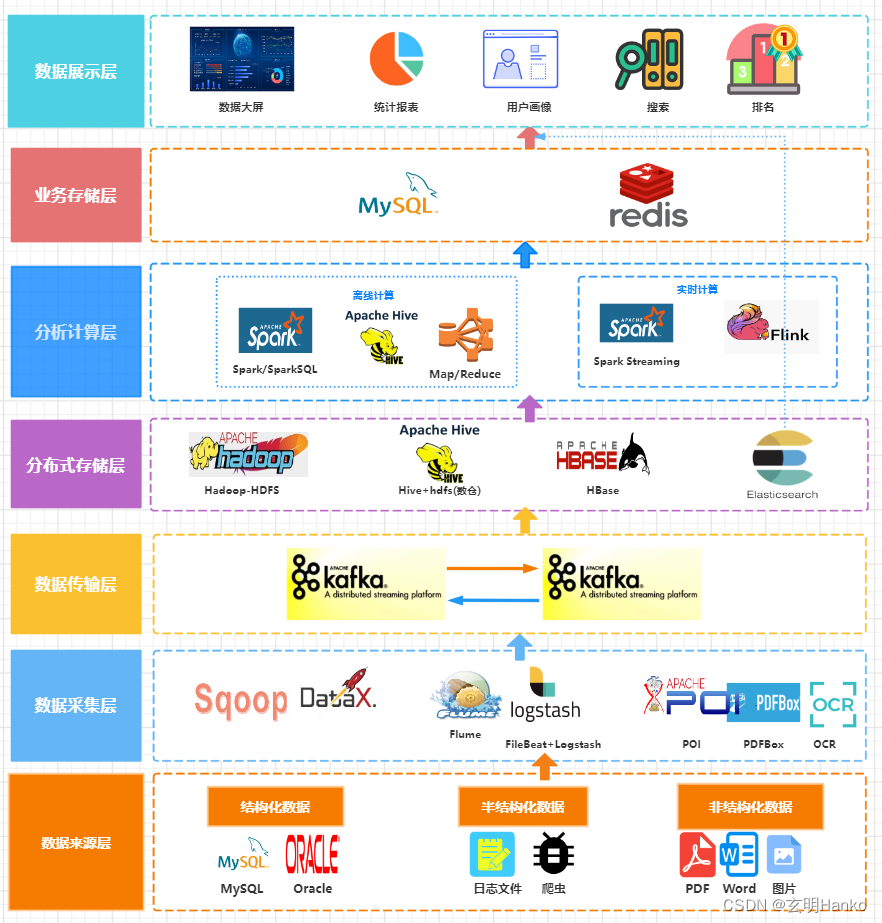
(1)使用Kafka + Flink构建Kappa流计算数据架构。
(2)Kafka对接组合ElasticSearch实时分析引擎,部分弥补其数据分析能力不足的问题。
但是ElasticSearch也只适合对合理数据量级的热数据进行索引,无法覆盖所有批处理相关的分析需求,这种混合架构某种意义上属于Kappa和Lambda间的折中方案。
(3)Spark流处理输出时是无法保证Exactly-once(失败时部分已经写出、而还有部分未写出,重启时从上一个检查点开始,造成部分重复),需要借助外部存储的唯一键或者是事务来保证幂等输出。而Flink借鉴 Chandy-Lamport 分布式快照算法实现的Asynchronous Barrier Snapshots算法来提供一致性保证。
参考资料:
二:大数据架构回顾-Kappa架构 - 天戈朱 - 博客园
Lambda架构,Kappa架构和去ETL化的IOTA架构 - 简书
从Lambda架构到Kappa架构再到?浅谈未来数仓架构设计~-阿里云开发者社区
Lambda架构,Kappa架构和去ETL化的IOTA架构 - 简书