目录
0、内网穿透的一般场景
1、内网穿透配置
a、frp软件下载
b、frp 的配置
3、通过 frp 实现远程连接
4、设置 frpc / frps 开机启动的方法
5、设置frp安全连接的方法
0、内网穿透的一般场景
放假回家怎么远程连接学校实验室的服务器?
先分析一波:首先家里的电脑与学校服务器主机分属不同的局域网(内网)中,也就是说家里网络设备上层的公网IP不同于学校服务器上层的公网IP,因此这种情况下就不能仅仅使用 SSH 来远程连接学校的服务器了,还需要借助一种叫做内网穿透的技术实现连接。如下面这幅图。

公网的IP是独一无二的,而局域网IP在从属不同公网的前提下可以是一样的,
内网穿透需要第三台电脑作为中转站,这个中转站需要有一个公网IP,一般来说可以用云服务器(一般都有公网IP)来作为中转站,可以租用阿里云腾讯云华为云这些平台中的云服务器。
1、内网穿透配置
使用的系统:云服务器(中转站)和实验室服务器(需要向公网暴露IP的本地主机)都是Ubuntu,个人电脑是Windows10.
a、frp软件下载
这里使用的内网穿透的工具是 FRP,GitHub地址:https://github.com/fatedier/frp。下载压缩包解压之后会看到下面的内容。这里以Windows版的为例,frp 含有 frps 和 frpc 两种配置文件,frps 是内网穿透服务端service(也就是中转站)的配置文件,作为内网穿透的桥梁。frpc 是内网穿透中需要向公网暴露IP的本地主机(也就是示例场景中的实验室服务器)。

b、frp 的配置
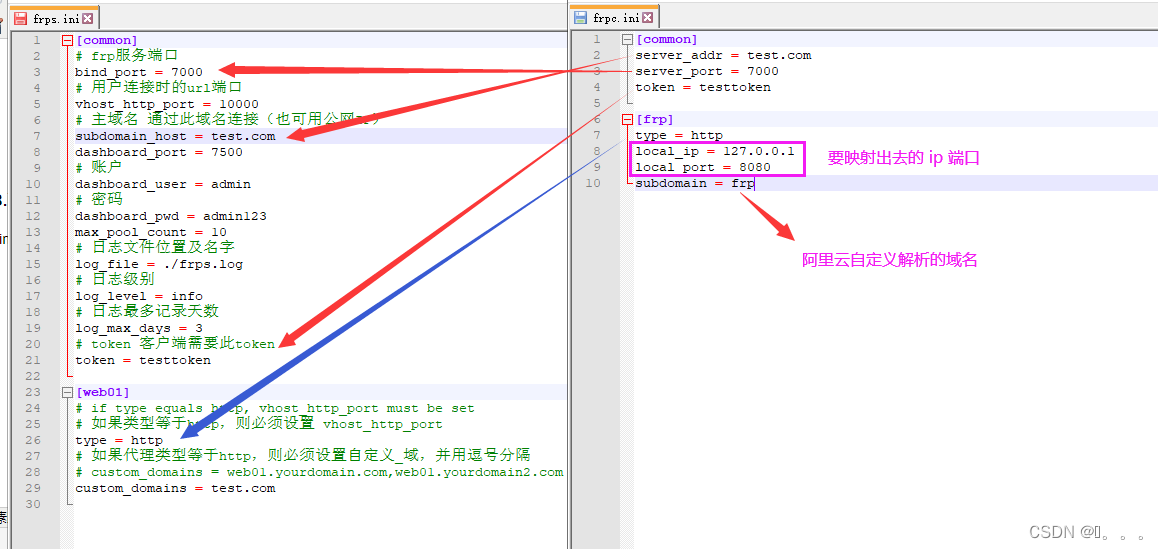
云服务器(后面称做A)作为内网穿透的桥梁,是内网穿透的服务端,需要使用 frps。实验室服务器(后面称做B)属于内网穿透中的服务端client,需要使用 frpc。可以通过分别修改 frps.ini 和 frpc.ini 来配置服务端和客户端。
A 中需要配置 frps.ini,这个文件原始内容如下:
[common]
bind_port = 7000保持默认参数即可。如果想配置其他内容,可以查看 frps_full.ini 文件的内容,里面有全部的配置语句。bind_port 表示将 B 与 A 的 7000 端口绑定,具体的端口号可以自定义修改。如果想配置其他内容,可以查看frps_full.ini文件的内容,里面有全部的配置语句。例如可以加一行 token=xxxx,类似于密钥,需两边都一样才能访问:
[common]
bind_port = 7000
# 可以加一行 token=xxxx,类似于密码,需两边都对上才能访问,此时客户端也需要有同样的设置
token=12345主机 B 需要配置 frpc.ini,这个文件原始内容如下:
[common]
# server_addr需要改成公网IP地址
server_addr = x.x.x.x
server_port = 7000
# 如前所述,可以加一行 token=xxxx,类似于密匙-密钥对,需两边都一样才能访问
token=12345
[ssh]
type = tcp
local_ip = 127.0.0.1
local_port = 22
# 这个端口可以自由设置,设置完后在云服务器中开启相应的端口即可
remote_port = 6000server_addr 参数修改为公网IP,server_port 用于frps与frpc之间交换数据的端口,local_port 是ssh服务端口,remote_port 是在frp服务器上公开的供外部设备连接的端口,6000 与 7000 端口的作用可以参照博客开头的那张图。接下来需要在云服务器的端口管理中添加相应的端口 6000 和 7000 并开放即可。比如我用的阿里云服务器,是在“服务器安全设置”选项中添加端口的:

3、通过 frp 实现远程连接
在上述配置都修改完成后,,在云服务器 A 上执行以下指令运行frps端:
./frps -c ./frps.ini在本地服务器 B 上执行以下指令运行 frpc 端:
./frpc -c ./frpc.ini然后本地主机就可以使用内网穿透来远程访问本地服务器了,在本地主机上执行以下指令:
ssh [username]@[ip] -p [port_num]- 其中:
- username 是 B 中的用户名,后面需要输入的密码也是该账户的密码。
- ip 是 A 的公网 ip 地址。这里注意!是 A 的公网 ip 地址,不是 B 的!
- port_num 是 frpc.ini 中设置的 remote_port 。
例如,要连接 实验室服务器(B)中的名为 abc 的用户,中转账云服务器的公网ip为123.0.0.3,remote_port 设置为 6000,则指令如下:
ssh abc@123.0.0.3 -p 6000同样也可以借助 VSCode 中的 Remote-SSH 插件,方便远程连接后的文件管理,方法可以看这篇博客 :SSH远程连接实例_地球被支点撬走啦的博客-CSDN博客_ssh连接实例
4、设置 frpc / frps 开机启动的方法
如果想让远程服务器 B 与本地服务器 A 开机自动启动 frps 和 frpc 这两个服务,就需要用到 systemd 文件夹中的文件了。内容如下:

Linux 系统下的开机启动需要使用 frps.service 与 frpc.service 这两个文件,将这两个文件分别拷贝到对应机器的 /lib/systemd/system 文件夹下。需要修改其中的 User 字段,改为当前主机用户的用户名,还需要修改 ExecStart 字段,把其中的 frps/frps 的路径改成你实际 frpc/frpc 所在的绝对路径。
在云服务器主机 A 中修改如下:
这里运行 frps 的云服务器的用户名为 admin,frps 的路径为 /home/admin/frp/frps,因此将原始的
frps.service 中的:
[Unit]
Description=Frp Server Service
After=network.target[Service]
Type=simple
User=nobody
Restart=on-failure
RestartSec=5s
ExecStart=/usr/bin/frps -c /etc/frp/frps.ini
LimitNOFILE=1048576[Install]
WantedBy=multi-user.target
ExecStart=/usr/bin/frps -c /etc/frp/frps.ini改为:
[Unit]
Description=Frp Server Service
After=network.target[Service]
Type=simple
User=admin
Restart=on-failure
RestartSec=5s
ExecStart=/home/admin/frp/frps -c /home/admin/frp/frps.ini
LimitNOFILE=1048576[Install]
WantedBy=multi-user.target
ExecStart=/usr/bin/frps -c /etc/frp/frps.ini然后运行 frpc 的本地服务器 B 中也是类似的设置:
[Unit]
Description=Frp Client Service
After=network.target[Service]
Type=simple
User=nobody
Restart=on-failure
RestartSec=5s
ExecStart=/usr/bin/frpc -c /etc/frp/frpc.ini
ExecReload=/usr/bin/frpc reload -c /etc/frp/frpc.ini
LimitNOFILE=1048576[Install]
WantedBy=multi-user.target# 改为:====================================================[Unit]
Description=Frp Client Service
After=network.target[Service]
Type=simple
User=ocean
Restart=on-failure
RestartSec=5s
ExecStart=/home/pathto/frp/frpc -c /home/pathto/frp/frpc.ini
ExecReload=/home/pathto/frp/frpc reload -c /home/pathto/frp/frpc.ini
LimitNOFILE=1048576[Install]
WantedBy=multi-user.target然后在 B 中依次执行以下四条指令启动 service 服务,实现开机启动:
systemctl daemon-reload # 重新加载
systemctl enable frpc.service # 使能开机启动
systemctl start frpc.service # 开启服务
systemctl status frpc.service # 查看服务状态 如果开启成功,则会显示如下界面 Activate 会显示绿色的 running。

云服务器 A 中的开机启动方式也是类似的,就不再赘述了。
5、设置frp安全连接的方法
如果直接将服务器暴露到公网上可能会有安全隐患,如果别人知道了公网中转站的 ip 和转接端口,就相当于知道了内网服务器的 ssh 端口,如果知道密码的话就可以随意登陆了。因此,登陆密码可以复杂一些以保证安全。另外一点,可以使用安全ssh登录,这个是官网的方法GitHub - fatedier/frp: A fast reverse proxy to help you expose a local server behind a NAT or firewall to the internet.A fast reverse proxy to help you expose a local server behind a NAT or firewall to the internet. - GitHub - fatedier/frp: A fast reverse proxy to help you expose a local server behind a NAT or firewall to the internet. https://github.com/fatedier/frp#expose-your-service-privately
https://github.com/fatedier/frp#expose-your-service-privately
frp 服务端主机 A 的 frps.ini 不需要修改,这要修改 frp 客户端主机 B 的 frpc.ini 的配置,这里移除了 remote_port 的设置。
[common]
server_addr = x.x.x.x
server_port = 7000
token = 12345
[secret_ssh]
# secret tcp
type = stcp
# security key,只有 sk 一致的用户才能访问到此服务
sk = abcdefg
# 向外部暴露的本地SSH服务端口
local_ip = 127.0.0.1
local_port = 22 另外,需要远程连接内网服务器的个人PC也需要运行 frpc,此时 frpc.ini 的配置为:
[common]
server_addr = x.x.x.x
server_port = 7000
token = 12345
[secret_ssh_visitor]
type = stcp
role = visitor
server_name = secret_ssh
# secret key,必须与目标主机的 frpc.ini 中的 sk 一样
sk = abcdefg
# 绑定本地端口用于访问 SSH 服务
bind_addr = 127.0.0.1
bind_port = 6000使用安全连接的情况下,在远程连接时,需要先在个人电脑上(这里是Windows)运行以下命令:
frpc.exe -c frpc.ini然后再执行ssh命令实现远程连接
ssh [username]@127.0.0.1 -p [port_num]