前言
对复杂信息系统进行运维的相关研究工作中,一个子领域是“根因定位”。这个子领域的一种问题定义是:在复杂系统的大量监控变量(如CPU利用率、响应时间)中,找到“根因”(“根因”指具体的监控变量)。在这一问题定义下,近年来的论文中采用的方法主要是深度优先搜索和随机游走。但这两个方法说不清楚为什么应该有效,甚至问题定义都有问题:“根因定位”指“定位根因”!
我们的工作用因果推断的语言为这个问题给出了一个形式化定义,继而给出了一个针对这一问题定义的、说得清楚为什么应该有效的、简单的方法。该工作已发表于KDD'22[1]。囿于投稿时的认识、时间压力、篇幅限制,一些内容在论文中没有说明白。这篇文章将展开论述忠实性假设、提出结构化构图的动机等论文中没交代清楚的内容,同时也充当一个面向国内读者的中文介绍。
问题定义
Judea Pearl将已有的因果推断任务分为三种,构成因果阶梯[2]。在因果阶梯上,第一级关注变量之间的联合概率分布。第二级则在第一级之上,关注当我们做些什么之后概率分布的变化。这里的“做些什么”在因果推断中称为干预。反事实推理处于因果阶梯的第三级,其特点在于施加的干预与事实相违背。
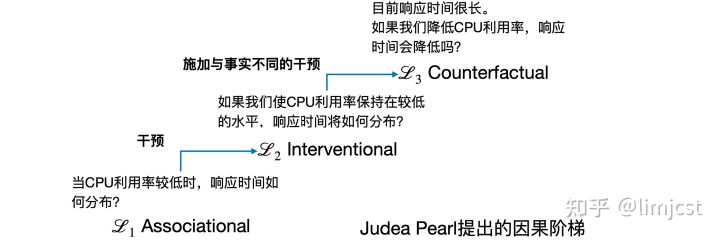
Judea Pearl的因果阶梯
我们将因果推断中的干预与根因分析中的故障建立联系,将无故障数据和故障数据映射为对干预前后两个分布的采样。基于这样的概念映射,我们将根因分析映射为一个新的因果推断任务——干预识别,即,基于干预前分布 P(V) 识别干预后分布 P(V∣do(m)) 中被干预的变量 m 。这里的 do 算子表示将一组变量赋为给定的值。

将根因分析形式化定义为一个新的因果推断任务——干预识别
分析
忠实性假设
对于一组给定的变量 V ,所有可能的干预 do(M=m),M⊂V 为定义在V上的所有分布给出了一组等价类: [m1]=[m2]⟺P(V∣do(m1))≡P(V∣do(m2)) 。换句话说,do 算子定义了一个从所有可能的干预到定义在V上的所有分布的映射。
- 当这个映射是双射时,干预识别要解决的是这个do 算子的逆映射;
- 当这个映射不是双射时,干预识别不总是有解。
下图展示了干预不同、但干预后分布相同的两个世界。当出现这样的情况时,干预识别无法给出确定的结论。
对于这个例子,
在左边这个响应时间被干预的世界中,CPU利用率的分布和干预前是一样的。
而右边这个CPU利用率被干预的世界保留了干预前响应时间的条件概率分布。
结合这两个信息我们可以得到结论,这两个干预后的世界和干预前看起来完全一样。然而,这样的场景对于根因分析而言没有什么实际意义。为此,我们引入忠实性假设排除这样不具有实际意义的情况,假定任何干预都会引起可以被观测到的变化。

干预不同、但干预后分布相同的两个世界
因果层次定理
在前述忠实性假设下,可以证明干预识别处于因果阶梯的第二级[1]。因果层次定理(Causal Hierarchy Theorem)[2]指出,因果阶梯坍缩的测度为零。如果我们想回答因果阶梯上某一级的问题,我们需要那一级、或更高级的知识。由此可以得到以下两个推论。
- 求解干预识别问题需要因果阶梯第二级的知识。而因果贝叶斯网络[3]是连接因果阶梯前两级的桥梁[2],这也解释了为什么许多已有的根因分析工作会把构建指标或服务之间的因果图作为步骤之一。
- 求解干预识别问题并不需要反事实推理的知识。
干预识别判据
在前述忠实性假设下进一步分析,我们得到干预识别判据作为根因的判定定理[1]:检测故障时刻以因果图中父结点为条件的条件概率分布是否发生了变化,即
Vi∈M⟺P(Vi∣pa(Vi),do(m))≠P(Vi∣pa(Vi))
因果图
因果层次定理要求我们引入因果阶梯第二级的知识来求解干预识别问题,为此,我们首先需要构建因果图。
因果发现
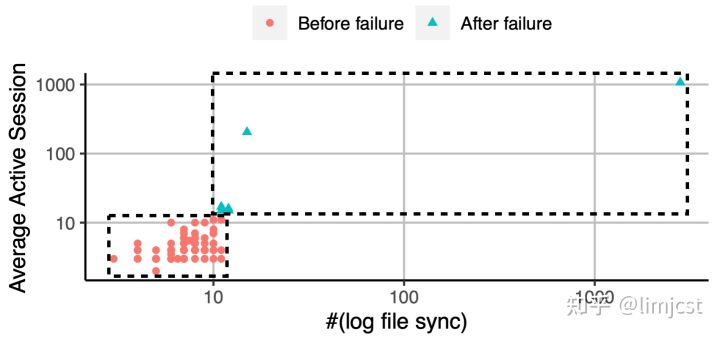
已有的根因分析工作在应用PC算法等因果发现算法之后并不在意挖掘出来的图是否正确。在这项工作之前,我们曾在一个开源数据集[4]上评估一些算法的效果,结果如下图所示[5]。实验中尝试的算法在处理实际问题时并不理想。

在一个开源数据集上评估一些相关分析、因果发现算法挖掘因果图的能力
随机对照试验?
随机对照试验是确定因果关系的黄金准则。笔者曾经尝试通过调节故障注入的强度来实现控制变量的效果,但在总结故障注入的原则时遇到了问题[6]:对于下面这个例子,在分别针对第4、7、10行的 A、B、C 三个计数器注入故障时,我们是否需要保证 counter_B 和 counter_C 之和总是等于 counter_A 呢?如果只在干预 B 或 C 时不再保证等量成立,其实已经假设了 A 是 B 和 C 的原因。
01 function foo() {
02 defer timer.ObserveDuration()
03 // A
04 counter_A += 1
05 if (condition) {
06 // B
07 counter_B += 1
08 } else {
09 // C
10 counter_C += 1
11 }
12 }
在对随机对照试验的尝试中,总结了如下两个认识:
- 故障注入本身依赖假设;
- 随机对照试验“发现”的因果关系是假设的体现。
既然如此,不如直接基于假设构建监控变量之间的因果图,也就有了论文中描述的结构化构图。
结构化构图
- 我们首先将监控变量分类为四种元变量,称为负载(Traffic)、资源利用率(Saturation)、响应时间(Latency)、错误率(Errors)。四种元变量连接有向边作为因果假设。例如,由于用户输入是一个请求的开始,对应的负载就被当做其它元变量的原因。
- 其次,将四个元变量构成的图依系统架构进行拓展。例如,数据库可以被当做服务的一种资源。服务资源利用率中描述数据库的部分可以拓展为数据库的四种元变量,并继承服务的资源利用率与服务的其它元变量之间的关系。
- 最后,我们将监控变量填入对应的元变量,完成因果图的构建。
实现
应用前述干预识别判据会遇到数据不足的问题,体现在两方面:
- 及时止损的要求限制了能够使用的故障数据时间跨度,我们对故障的了解有限;
- 无故障数据也不够,表现为故障前后两个数据分布之间缺少交集。
应用干预识别判据时遇到数据不足的问题
基于回归的假设检验方法
为了减少对故障数据的需求,我们将干预识别判据以假设检验的形式重新表述。空假设 H0 为一个变量 Vi 没有被干预,检验该变量在故障发生后的一个取值 Vi(t)是否依然服从之前的分布 P(Vi(t)∣pa(t)(Vi)) ,以Vi(t)距均值的距离相比方差的倍数当作异常分数。另一方面,利用回归技术尝试将有限的无故障数据拓展到故障时刻的数据范围。
后继调整
当我们知道数据生成过程的具体形式[7]时,回归模型可以有较好的表现。而现实则是,我们既不知道数据生成过程的具体形式,数据不足的问题又限制了数据驱动方法的发挥。为此,我们在这项工作中引入了后继调整。
例如,当系统响应时间居高不下时,增加机器、降低资源利用率可能是一个有效的方法。后继调整通过将响应时间的异常分数加到资源利用率(因果图中响应时间的父结点)上,表达对后者的偏好。
在我们采用的真实数据集上,后继调整帮助基于回归的假设检验方法获得了更好的效果。但后继调整的效果还需要在更多数据集上评估,或是被其它应对数据不足的方法所替代。
其它问题
为什么说Sage在方法设计中假定系统本身没有故障?
对于一个给定数据分布 P′(V) ,反事实推理首先基于已有观测推断出隐变量的取值 z′ ,在此基础上施加干预计算反事实分布 P′(V∣z′,do(x)) 。Sage[8]应用反事实推理诊断系统性能问题,关心施加哪些干预后,系统整体延时 Y 会恢复正常。
我们的工作将故障映射为因果推断中的干预。当系统本身没有被干预时,有 P′≡P ,后者可以从故障发生前的数据中进行学习;而当系统本身存在干预时, P′(V)≡P(V∣do(M)) ,后者需要从故障数据中学习。Sage基于故障发生前的数据训练模型,因而隐含了系统本身没有被干预这一假设,即假定系统本身没有我们工作中定义的故障。
如果将故障当作干预之外、在因果阶梯上处于低一层的事物,根因分析到底是在分析什么还需要进一步的探讨。
参考
- ^abcCausal Inference-Based Root Cause Analysis for Online Service Systems with Intervention Recognition. Causal Inference-Based Root Cause Analysis for Online Service Systems with Intervention Recognition | Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
- ^abcOn Pearl's Hierarchy and the Foundations of Causal Inference. https://causalai.net/r60.pdf
- ^参考系统:关河因果分析系统https://yinguo.grandhoo.com/home