因果分析是在统计领域内建立因果关系的实验分析。在数据分析中,我们始终对因果关系问题感到困扰,通常从统计角度对可用数据进行分析。虽然知道因果关系的金钥匙是 A/B 测试,但是由于某些原因(例如时间限制,成本或只是没有数据)无法进行测试,该怎么办。在这里,我们可以应用因果分析来估计干预(功能)对结果的影响。因果分析在本质上与机器学习建模预测不同。虽然我们可以尝试通过学习数据模式来预测结果,但是我们永远不知道在数据维度之外会发生什么。试想一下,您明天可能会考试并决定连续学习两个小时。结果是在两个小时的学习干预下您的考试成绩,但是如果您只学习一小时怎么办?有什么效果吗?我们不能倒退时间。这就是为什么我们进行因果分析而不是机器学习预测的原因。这样的反事实数据不存在,这就是机器无法学习的原因。我们只能学习一个小时的结果是我们无法观察到的,因为我们无法倒带时间。这就是为什么这种情况称为“反事实”。这是因果分析的根本问题。我们只能近似预估因果效应。
近似预估因果效应的最佳库之一是 DoWhy 包。在本文中分享如何使用 DoWhy 来确定分析中的因果关系。
DoWhy的因果分析
根据 DoWhy 官方文档,因果关系分析共有以下 4 个步骤:
根据假设对因果推理问题进行建模
确定因果效应表述(“因果估计”)
使用统计方法(例如匹配或工具变量)估计
使用各种稳健性检验来验证估计有效性
1、定义问题
在开始分析数据之前,我们需要定义要解决的问题。在客户流失数据集中,假设我们正在与信贷部门合作,我们想知道信贷额度是否对客户流失具有因果关系。信贷部门限制,任何超过 20000 的信贷额度都被视为高额客户。在这种情况下问题为:“高额信贷会影响银行流失吗?”
import pandas as pddf = pd.read_csv('BankChurners.csv')
df.info() #Creating the High_Limit attribute
df['High_limit'] = df['Credit_Limit'].apply(lambda x: True if x > 20000 else False)
#Creating True or False columns from the Attrition flag for the churn column
df['Churn'] = df['Attrition_Flag'].apply(lambda x: True if x == 'Attrited Customer' else False)

2、创建因果模型
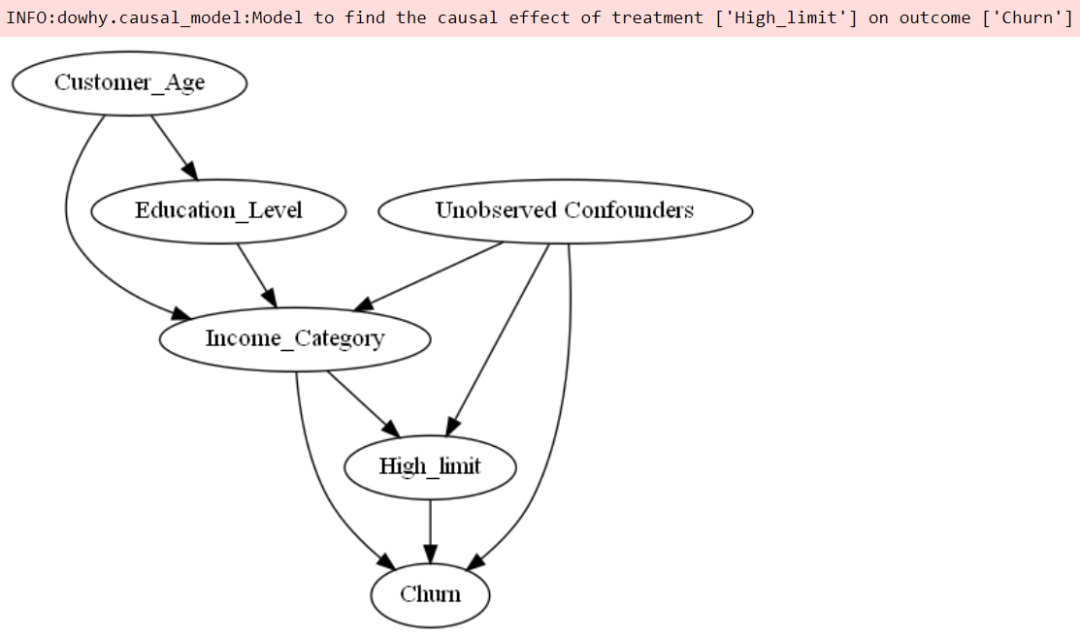
因果模型基于问题假设,这意味着该模型将基于我们的先验知识建立。我们可以在图中表示我们的先验知识。
training= df[['Customer_Age','Education_Level','Income_Category', 'High_limit', 'Churn' ]].copy()
从先验知识中,我们列出了会影响流失率和其他功能的假设:
高限制类别可能会影响客户流失,因为低限制类别的人可能不那么忠诚于银行。
收入类别影响信用额度上限。信用额度通常基于收入。收入类别本身可能会影响流失率。
受教育程度会影响收入类别。
客户年龄可能会影响他们所受的教育程度和收入类别。
不可观察的混杂因素正在影响收入类别,最高限额和客户流失。
将所有假设创建到图中,可以使用 DoWhy 包。
#Creating the
causal_graph = """
digraph {
High_limit;
Churn;
Income_Category;
Education_Level;
Customer_Age;
U[label="Unobserved Confounders"];
Customer_Age -> Education_Level; Customer_Age -> Income_Category;
Education_Level -> Income_Category; Income_Category->High_limit;
U->Income_Category;U->High_limit;U->Churn;
High_limit->Churn; Income_Category -> Churn;
}
"""from dowhy import CausalModel
from IPython.display import Image, display
model= CausalModel(data = training,graph=causal_graph.replace("\n", " "),treatment='High_limit',outcome='Churn')
model.view_model()
display(Image(filename="causal_model.png"))
得到如下的因果关系图:
3、确定因果关系
因果分析的定义是,如果除干预外的其他变量不变时,干预的改变将影响结果。使用 DoWhy 因果模型确定因果效应。
#Identify the causal effect
estimands = model.identify_effect()
print(estimands)

这是根据我们之前的假设所做的估算。
4、基于统计方法估算因果效应
干预对结果的因果关系基于干预变量值的变化。统计因果效应的方法有很多,常用的有以下几种:
倾向得分匹配
倾向得分分层
基于倾向得分的逆概率加权法
线性回归
广义线性模型(例如,逻辑回归)
工具变量
断点回归
这里我将使用“基于倾向得分的逆概率加权”方法。
#Causal Effect Estimation
estimate = model.estimate_effect(estimands,method_name = "backdoor.propensity_score_weighting")
print(estimate)

从上面的结果中,我们得到的平均估计值为 -0.095,相当于说当客户拥有较高的信用额度时,流失的可能性降低了约 9%。
5、稳健性检验
因果效应估计是基于数据统计估计,但因果关系本身并不基于数据;而是基于我们之前的假设。
使用 DoWhy 包,我们可以通过多次稳健性检验来测试我们的假设有效性。这些是可用于检验假设的一些方法:
添加随机生成的混杂因素
添加与干预和结果相关的混杂因素
安慰剂(随机)变量代替干预
选取数据随机子集
随机共同因子
将独立随机变量作为共同影响因子添加到数据集;如果原假设是正确的,则估计不应改变。
refutel = model.refute_estimate(estimands,estimate, "random_common_cause")
print(refutel)
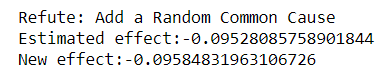
数据子集
用随机选择的子集替换给定的数据集;如果假设是正确的,则估计值不应有太大变化。
refutel = model.refute_estimate(estimands,estimate, "data_subset_refuter")
print(refutel)
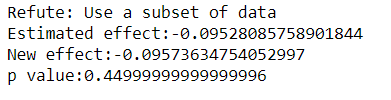
安慰剂干预
用独立的随机变量代替真实的干预变量;如果假设是正确的,则估计值应接近零。
refutel = model.refute_estimate(estimands,estimate, "placebo_treatment_refuter")
print(refutel)

基于上面的 refutal 方法;可以支持我们的假设是正确的,即信用额度上限对客户流失具有因果关系。
6、结论
因果分析是在统计领域内建立因果关系的实验分析。它从根本上与机器学习预测不同,因为我们尝试根据反事实来近似估计干预效应。使用 Microsoft 开源的 DoWhy 包,使用四个步骤来估计因果关系:
建立因果模型
识别效应
估计效应
证实有效性
数据链接:https://github.com/cornelliusyudhawijaya/Churn_Causality_Analysis/blob/main/BankChurners.csv