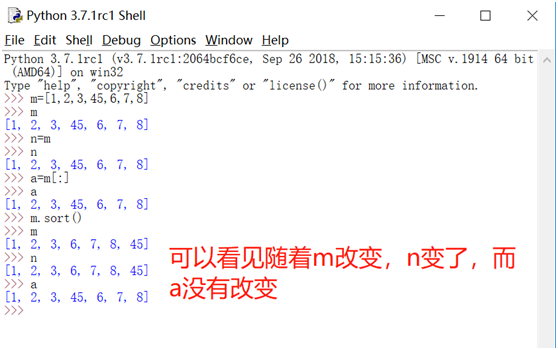
在现实场景中我们常被要求回答“如果”的问题,经济学家称之为反事实。如果我现在要的不是这个价格,而是另一个价格,会发生什么?如果我不吃低脂饮食,而是吃低糖饮食会怎么样?如果你在银行工作,提供信贷,你必须弄清楚改变客户线如何改变你的收入。
在这些问题的核心是一个因果调查,我们希望知道答案,同时能够进行归因。因果问题渗透在日常问题中。回答这种问题比大多数人想象的要难。事实上,如何解释因果分析的情况还要更复杂一些。
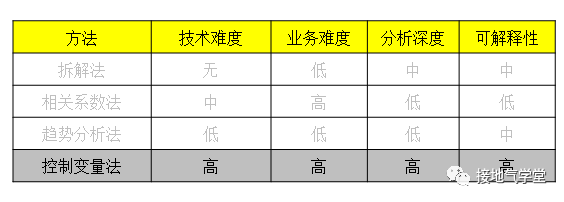
因果分析方法中所用到的相关分析、回归分析、聚类分析,本质上不是“分析”,而是计算。通过计算,得出两列数字或者几列数字之间的关系。至于这个关系到底有没有含义,计算公式本身就不负责解释了。
这些统计学方法都有类似的问题,只能解释数据本身的关系,解释不了现实中的关系。更本质地看:是否所有业务行为,外部因素都能量化?完全不是。比如消费者对品牌的信任,比如产品体验好坏,比如文案感受,是很难量化到一个稳定、可靠的指标的。因此,用统计学方法,可以大范围地筛选过滤指标,但是很难推理出真实因果。至于这部分,下文将致力于研究如何使联想成为因果关系。
因果分析的核心:
· identification:将因果关系从关联中分割
· estimation:计算因果关系的大小
· inference:基于统计的推断(有多大的信心结果是正确的Hypothesis testing,结果会存在多大的波动Confidence interval)
相关不是因果
凭直觉,我们便知道相关不是因果关系。在此之前我们先要清楚相关性的定义:相关分析是研究两个或两个以上处于的随机变量间的相关关系的统计分析方法,常用事物中的关联规则来表示。
相关分析仅仅是基于数据的特征进行分析,所有分析结果都是来源于数据所呈现的情况,但大部分数据并不足以支撑所有的相关性出现,同时这些相关规则也仅是因果关系中的一部分,并不能够代替因果。
相关性体现了两个事物之间相互关联的程度。比如房屋面积越大,房价就越高,改变其中一个变量(房屋面积)会引发另一个变量(房屋的价格)朝着同样的方向变化,这两个变量就存在正相关性。反之,如果一个变量的改变会让另一个变量朝着相反方向变化,就表明它们有负相关性,比如海拔高度和大气压的关系。
不过,数据之间通常只能呈现关联性,而很难直接体现因果性。人工智能就是一个典型代表,计算机只能发现数据之间的联系,它不负责解释原因。
相关推导因果
相关性和因果性之间的联系,从统计学教材到大数据著作,都有着广泛的探讨,甚至争议不断。迈尔舍恩伯格在《大数据时代》里说,“要相关,不要因果”,在大数据时代,有相关,就够了。
而周涛则在《为数据而生》一书中说,放弃对因果关系的追寻,就是人类的自我堕落,相关性分析是寻找因果关系的利器,能够为因果关系的发现提供一点思路。

《为数据而生》
在大数据分析领域又存在着这样的分析方法:相关分析法,常用于对总体中确实具有联系的标志进行分析,其主体是对总体中具有因果关系标志的分析。但两个变量之间存在相关关系,不一定说明两者之间存在着因果关系。因果关系,是指一个变量的存在一定会导致另一个变量的产生。而相关性是统计学上的一个概念,是指一个变量变化的同时,另一个因素也会伴随发生变化,但不能确定一个变量变化是不是另一个变量变化的原因。
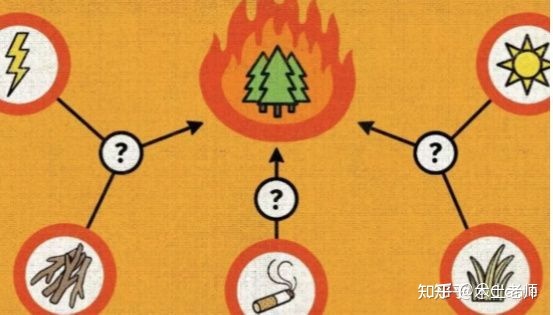
比如天气冷和下雪通常一起发生,说明两者有很强的相关性,但不能肯定是谁导致了谁,所以不确定两者是够有因果关系。

因果有前因有后果,显然不能通过已知的关联性直接看到是事物间的因果关系,但一定是基于关联性之下去推导因果关系的,相关性——>因果性的跨越一定的需要认知参与的。
如何实现因果
相关分析为发现因果关系提供了基础。从大量数据集中发现项集之间的关联性或相关性。若两个或多个变量的取值之间存在某种规律性,就可以挖掘出关联规则。由关联规则结合时序便可推断出因果关系。
而在关联规则的挖掘中图数据的关联分析能发现大数据中的相互依赖关系和关联关系使用图理论完成关联关系挖掘,相比机器学习理论拥有可解释的特性。 对现实世界的规则有更好的 亲和性,更容易寻找到数据中潜在的规律。
在得到大量规则后,通过发现他们之间的时间顺序来筛选关联规则,在这些规则中归因、求果。
这种方式是行业中大部分数据分析、数据挖掘系统所选择的方向,在关联规则中进行因果分析,较为成熟的产品是基于钓鱼城引擎研发的关河因果数据分析系统:
新型数据分析产品_因果分析_关河因果【官网】yinguo.grandhoo.com/home正在上传…重新上传取消
想要实现真正的因果分析还有很长的一段路要走,就相当当年的神经网络的历程一样,经过多次的推翻与重塑。因果分析的研究是会一直进行下去的。