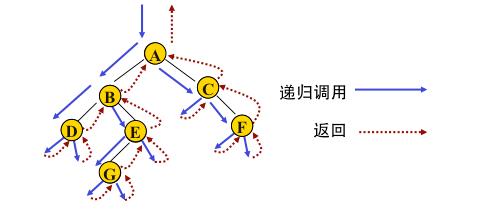
说明
Gremlin是Apache TinkerPop的图形遍历语言。Gremlin是一个功能,数据流 语言,使用户能够简洁地表达复杂的遍历(或查询)的应用程序的性能曲线图。每个Gremlin遍历都由一系列(可能嵌套的)步骤组成。步骤对数据流执行原子操作。每一步都是map步骤(转换流中的对象),filter步骤(从流中移除对象)或sideEffect-step(计算有关流的统计信息)。Gremlin步骤库在这3个基本操作的基础上扩展,为用户提供了丰富的步骤集,用户可以编写这些步骤,以询问他们可能对Gremlin is Turing Complete数据有任何可能的疑问。
场景一
g.V().has("name","gremlin").out("knows").out("knows").values("name")
- Gremlin的朋友的朋友的名字是什么?获得名称为“ gremlin”的顶点。
- 游历Gremlin认识的人。
- 遍历那些认识的人。
- 获取这些人的名字。
场景二
g.V().match(as("a").out("knows").as("b"),as("a").out("created").as("c"),as("b").out("created").as("c"),as("c").in("created").count().is(2)).select("c").by("name")
两个朋友创建的项目的名称是什么?
- …存在一些认识“ b”的“ a”。
- …存在创建“ c”的一些“ a”。
- …存在创建“ c”的一些“ b”。
- …存在一个由2个人创建的“ c”。
- 获取所有匹配的“ c”项目的名称。
场景三
g.V().has("name","gremlin").repeat(in("manages")).until(has("title","ceo")).path().by("name")
- 让经理从gremlin遍历到首席执行官。
- 获得名称为“ gremlin”的顶点。
- 遍历管理链…
- …直到拥有CEO头衔的人为止。
- 获取遍历路径中经理的姓名。
场景四
g.V().has("name","gremlin").as("a").out("created").in("created").where(neq("a")).groupCount().by("title")
- 获取Gremlin的合作者之间的标题分配。
- 获得名称为“ gremlin”的顶点并将其标记为“ a”。
- 获取Gremlin创建的项目,然后由谁创建…
- 不是gremlin
- 按标题对这些协作者进行分组统计。
场景五
g.V().has("name","gremlin").out("bought").aggregate("stash").in("bought").out("bought").where(not(within("stash"))).groupCount().order(local).by(values,desc)
- 获取供Gremlin购买的相关产品的排名列表。
- 获得名称为“ gremlin”的顶点。
- 获取Gremlin购买的产品并保存为“存储”。
- 还有谁买了那些产品,又买了什么…
- … Gremlin尚未购买。
- 按相关性对产品和订单进行分组计数。
场景六
g.V().hasLabel("person").pageRank().by("friendRank").by(outE("knows")).order().by("friendRank",desc).limit(10)
- 在知识图中获得10个最重要的人物。
- 获取所有人的顶点。
- 使用知识边缘计算其PageRank。
- 按他们的friendRank分数排序人。
- 获得排名前10位的人。
OLTP和OLAP遍历
Gremlin是根据“编写一次,随处运行”的哲学设计的。这意味着不仅所有启用TinkerPop的图形系统都可以执行Gremlin遍历,而且每个Gremlin遍历都可以评估为实时数据库查询或批处理分析查询。前者被称为在线事务处理Online transaction processing(OLTP),后者被称为在线分析过程Online analytical processing(OLAP)。Gremlin遍历机使这种通用性成为可能。这个基于图形的分布式虚拟机 了解如何协调多机图遍历的执行。而且,不仅执行可以是OLTP或OLAP,遍历的某些子集还可以执行OLTP,而其他子集则可以通过OLAP执行。好处是用户不需要学习数据库查询语言和特定于域的BigData分析语言(例如Spark DSL,MapReduce等)。Gremlin是构建基于图形的应用程序所需的全部,因为Gremlin遍历机将处理其余部分。

命令式和声明式遍历
Gremlin遍历可以用命令式(过程式),声明式(描述性)方式编写)方式,或同时包含命令式和声明式方面的混合方式。命令式Gremlin遍历告诉遍历者如何在遍历的每个步骤进行。例如,右边的命令式遍历首先在顶点处放置一个遍历器,表示Gremlin。然后,那个遍历者将自己分散到不是Gremlin自己的所有Gremlin合作者中。接下来,遍历者走到那些协作者的经理,最终被归类为经理姓名计数分布。这种遍历是必须的,因为它以一种明确的程序方式告诉遍历者“去这里然后去那里”。
g.V().has("name","gremlin").as("a").out("created").in("created").where(neq("a")).in("manages").groupCount().by("name")
声明性Gremlin遍历不告诉遍历者执行行走的顺序,而是允许每个遍历者从一组(可能嵌套的)模式中选择要执行的模式。左侧的声明性遍历产生的结果与上面的命令性遍历相同。但是,声明性遍历具有一个附加的好处,即它不仅利用编译时查询计划程序(如命令遍历),而且还利用运行时查询计划程序根据每个模式的历史统计信息选择下一个要执行的遍历模式-支持那些倾向于减少/过滤最多数据的模式。
g.V().match(as("a").has("name","gremlin"),as("a").out("created").as("b"),as("b").in("created").as("c"),as("c").in("manages").as("d"),where("a",neq("c"))).select("d").groupCount().by("name")
用户可以选择任何方式编写遍历。但是,最终在遍历遍历时,并根据基础执行引擎(即OLTP图数据库或OLAP图处理器),将通过一组遍历策略来重写用户的遍历,这些策略将尽力确定最佳执行方式根据对图形数据访问成本以及底层数据系统的独特功能的理解(例如,从图形数据库的“名称”索引中获取Gremlin顶点)进行计划。Gremlin旨在为用户提供表达查询方式的灵活性,并为图形系统提供者提供灵活性,以针对支持TinkerPop的数据系统有效地评估遍历。
宿主语言嵌入
经典的数据库查询语言(例如SQL)被认为与最终在生产环境中使用它们的编程语言根本不同。因此,经典数据库要求开发人员以其本机编程语言以及数据库的相应查询语言进行编码。可以说“查询语言”和“编程语言”之间的差异不如我们所教。Gremlin统一了这种鸿沟,因为遍历可以使用任何支持函数组合和嵌套的编程语言编写(每种主要编程语言都支持)。这样,用户的Gremlin遍历将与应用程序代码一起编写,并受益于宿主语言及其工具(例如,类型检查,语法突出显示,点完成等)提供的优势。存在各种Gremlin语言变体,包括:Gremlin-Java,Gremlin-Groovy,Gremlin-Python, Gremlin-Scala等。

下面的第一个示例显示了一个简单的Java类。请注意,Gremlin遍历以Gremlin-Java表示,因此是用户应用程序代码的一部分。开发人员无需String用(但)另一种语言创建查询的表示形式,以最终将其传递String给图形计算系统并返回结果集。而是将遍历嵌入到用户的主机编程语言中,并与所有其他应用程序代码同等地位。使用Gremlin,用户不必面对下面第二个示例中所示的尴尬情况,这是整个行业中常见的反模式。
public class GremlinTinkerPopExample {public void run(String name, String property) {Graph graph = GraphFactory.open(...);GraphTraversalSource g = graph.traversal();double avg = g.V().has("name",name).out("knows").out("created").values(property).mean().next();System.out.println("Average rating: " + avg);}
}public class SqlJdbcExample {public void run(String name, String property) {Connection connection = DriverManager.getConnection(...)Statement statement = connection.createStatement();ResultSet result = statement.executeQuery("SELECT AVG(pr." + property + ") as AVERAGE FROM PERSONS p1" +"INNER JOIN KNOWS k ON k.person1 = p1.id " +"INNER JOIN PERSONS p2 ON p2.id = k.person2 " +"INNER JOIN CREATED c ON c.person = p2.id " +"INNER JOIN PROJECTS pr ON pr.id = c.project " +"WHERE p.name = '" + name + "');System.out.println("Average rating: " + result.next().getDouble("AVERAGE")}
}
在幕后,Gremlin遍历将针对嵌入式图形数据库进行本地评估,通过网络将其序列化为远程图形数据库,或将其发送给OLAP处理器以进行集群范围的分布式执行。遍历源定义确定遍历在何处执行。一旦定义了遍历源,就可以类似于数据库连接的方式反复使用它。最终的效果是,用户“感觉”到他们的数据和遍历都位于应用程序中,并且可以通过其应用程序的本机编程语言进行访问。“查询语言/编程语言”划分由Gremlin桥接。
Graph graph = GraphFactory.open(...);
GraphTraversalSource g;
g = graph.traversal(); // local OLTP
g = traversal().withRemote(DriverRemoteConnection.using("localhost", 8182)) // remote
g = graph.traversal().withComputer(SparkGraphComputer.class); // distributed OLAP
参考
https://tinkerpop.apache.org/gremlin.html