一个良好的设计对于数据库系统至关重要,它可以减少数据冗余,确保数据的一致性和完整性,同时使得数据库易于维护和扩展。
实体关系图
实体关系图(Entity-Relationship Diagram,ERD)是一种用于数据库设计的结构图,它描述了数据库中的实体以及它们之间的关系。从结构上来说,数据库的ERD主要包括实体、属性以及关系三个部分。
实体
实体代表了一种对象或者概念。例如,员工、部门和职位都可以被称为实体。实体包含一个或多个属性,实体在数据库中对应的就是关系表。
属性
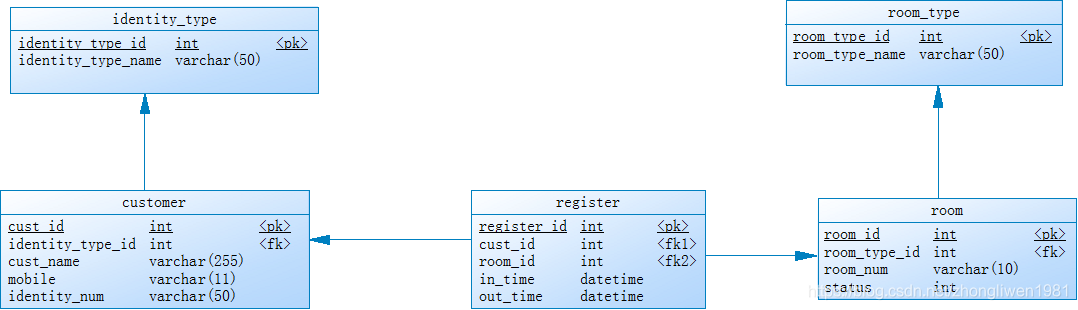
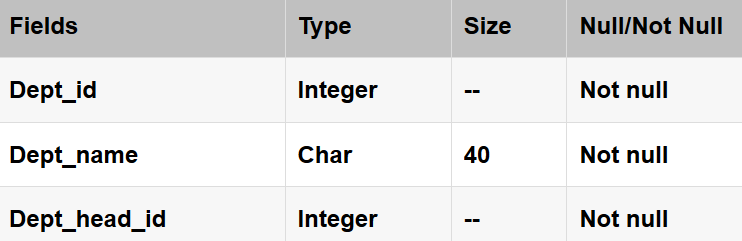
属性表示实体的某种特性,例如员工拥有姓名、性别、工资等属性。属性在数据库中对应的就是表中的字段,字段拥有一个指定的名称和数据类型。下图是一个包含各种属性的员工实体(employee)。

其中,员工编号(emp_id)属性可用于唯一标识每一位员工,被称为主键(Primary Key)。主键可以是单个字段,也可以由多个字段组成。
关系
关系用于表示两个实体之间的联系,三种常见的关系类型包括一对一、一对多以及多对多的关系。
例如,一夫一妻制是一种典型的一对一的关系。一个员工只能属于一个部门,一个部门可以拥有多个员工,因此部门和员工之间是一对多的关系。一个学生可以选修多门课程,一门课程可以被多个学生选修,因此学生和课程之间是多对多的关系。
规范化设计
规范化(Normalization)指的是用于数据库设计的一系列原理和技术,它可以减少表中数据的冗余,增加数据的完整性和一致性。我们通常在创建逻辑ERD或者物理ERD时引入规范化技术。
数据异常
假如我们不考虑规范化设计,将部门、员工以及职位等信息全部存储到一个表中,得到的表结构如下图所示。

所示表中的每一行数据对应一个员工的信息,包括员工所在的部门、姓名、性别、职位等。显然,这种设计存在以下问题:
数据冗余
同一个部门的信息存储多份,占用了更多的磁盘空间。由于数据冗余,有时候也可能导致在不同的表中存储了重复的数据或者字段。
插入异常
如果我们想要成立一个新的部门,由于还没有增加新的员工,因此无法录入这个部门的信息。
删除异常
如果我们删除了某个部门的所有员工,该部门的信息也将不复存在。
更新异常
如果我们想要修改部门信息,必须更新与该部门相关的多个记录,执行效率低下。如果不小心忽略了某些记录的话,将会导致数据不一致。
为了解决这些问题,数据库引入了规范化过程。规范化过程使用范式(Normal Form)进行定义和衡量,范式就是关系模型需要满足的一种规范要求或者标准级别。
关系模型的创始人Edgar Frank Codd博士最早提出了第一范式(1NF)、第二范式(2NF)以及第三范式(3NF)。随后人们又提出了更高级别的范式,包括BC范式(BCNF)、第四范式(4NF)以及第五范式(5NF)等。每个范式都基于前面的范式进行定义,例如若要实现第二范式,需要先满足第一范式的条件。
第一范式
第一范式要求关系模型满足以下条件:
- 表中的字段都是不可再分的原子属性。
- 表需要定义一个主键(Primary Key)。
简单来说,首先就是每个属性要有单独的字段。在上面的不规范设计中,员工的个人电话和工作电话存储在一个字段中,破坏了原子性。另外,我们还需要为表定义一个主键,用于唯一地识别每一行数据。假如每个部门中的员工姓名不会重复(实际上并非如此),我们可以使用部门名称加上员工姓名作为主键。
因此,我们将“电话”字段拆分成两个字段就可以满足第一范式,如下图所示。

第一范式要求表中的字段具有不可分割的原子性。不过我们知道,原子虽然是化学反应中不可再分的基本粒子,但其在物理状态下仍然可以被分割,它是由原子核和绕核运动的电子组成的。因此,我们同样需要了解数据库设计中的字段不可分割到底是针对什么而言的。
例如,“姓名”实际上也可以拆分成两个字段:“姓氏”和“名字”。我们要不要进行拆分取决于应用程序如何使用这些信息。一般我们可以将“姓名”作为一个字段存储,但是某些应用可能会对其进行拆分,比如申请信用卡时填写的表单。这样我们在给客户发送消息时,可以方便地称呼其为“尊敬的某先生/女士”。
另一个类似的情况是地址信息,比如“××省××市××区(县)××小区”。我们应该将其存储到一个字段中,还是拆分成多个字段呢?大部分情况下,应用程序可能需要统计不同地区的用户数据,将地址拆分成多个字段可以便于分析。
图中的表结构仍然存在数据冗余的问题(部门和职位信息),这可能导致插入异常、删除异常以及修改异常等问题,因此我们还需要对其进一步规范化。
第二范式
第二范式要求关系模型满足以下条件:
- 满足第一范式。
- 非主键字段必须完全依赖于主键,不能只依赖于主键的一部分。
“部门地址”取决于“部门名称”,也就是依赖于主键的一部分。这种依赖关系被称为部分函数依赖(Partial Functional Dependency)。此时,部门地址信息存在冗余,这可能会导致各种数据异常问题。另外,职位信息也存在相同的问题。
我们可以将部门和职位信息分别单独存储到一张部门表中,并且在它们和员工表之间维护一个一对多的外键关系,如下图所示。

我们将员工信息拆分成了3个表,并且为它们分别增加了一个编号字段。这是因为姓名、部门名称、职位名称等信息并不适合作为主键。例如,当我们使用部门名称作为主键时,如果需要修改某个部门的名称,员工表中就需要相应地修改多条记录。通常我们可以为每个表增加一个与业务无关的字段作为主键。
第三范式
第三范式要求关系模型满足以下条件:
- 满足第二范式。
- 属性不依赖于其他的非主属性。
如果主键决定了字段A,字段A又决定了字段B,这种依赖关系被称为传递函数依赖(Transitive Functional Dependency)。考虑到在同一个部门中可能存在多个姓名相同的员工这种情况,我们直接在员工表中增加一个编号字段作为主键也可以满足第二范式的要求,如下图所示。

主键“工号”决定了“部门名称”字段,“部门名称”决定了“部门地址”字段。因此,以上表结构虽然满足第二范式,但是存在传递函数依赖,可能会导致数据的冗余和不一致。
表结构中将员工表拆分成了多个表,避免了传递函数依赖问题,因此满足第三范式。
此时,我们再来回顾一下非规范化设计时的几个问题:
- 部门、员工以及职位信息分别存储一份,并且通过外键建立了它们之间的关系,因此不存在数据冗余的问题。
- 如果我们需要成立一个新的部门,可以直接录入部门信息。这样就解决了插入异常的问题。
- 删除某个部门的所有员工不会影响该部门的信息,不存在删除异常问题。
- 如果我们需要修改部门信息,直接更新部门表即可,不会导致数据不一致的问题。
对于大多数的交易型数据库系统而言,满足第三范式就已经足够了。我们在进行数据库设计时,只需将不同的实体或者实体的关系单独存储到一张表中即可满足第三范式。
主键与外键
规范化设计
在设计数据库的结构时,还有一个需要考虑的问题,那就是外键(Foreign Key)。外键是数据库用来实现参照完整性约束的,可以保证数据的完整性和一致性。同时,外键的级联操作可以方便数据的自动处理,减少程序出错的可能性。
例如,员工属于某个部门,我们可以在员工表的dept_id字段中创建一个引用部门表主键字段dept_id的外键约束。此时,我们必须先创建部门,然后才能为该部门创建员工,不会出现员工属于某个不存在的部门的情况,从而保证了数据的完整性。
同样,如果我们想要删除一个部门,必须确保该部门中不存在任何员工,或者同时删除该部门下的所有员工。利用数据库的外键级联删除或者级联更新功能,可以自动删除相关的员工,或者将相关员工的所属部门修改为其他部门。
不过,虽然外键可以实现参照完整性约束,但是也可能会导致性能问题。因为数据库为了维护外键需要牺牲一定的性能,这在大数据量高并发的情况下可能导致性能明显下降。
除以上方法外,另一种解决方法就是在应用层实现完整性检查,因为应用程序相对比较容易扩展。但是这种方案也可能引起一些问题。首先,应用程序中的实现更加复杂,无法百分之百地保证数据的完整性,尤其是在多个应用程序同时共享一个数据库时。另外,缺少外键会导致表之间的关系不明确,需要依赖相应的文档进行说明。
总之,我们在系统设计之初应该尽量利用外键实现数据的完整性约束。如果随着业务的增长而出现了数据库性能问题,可以考虑在应用程序中实现约束检查。
反规范化设计
简单来说,规范化就是将大表拆分成多个小表,并且通过外键建立它们之间的联系。规范化带来的一个结果就是连接查询。例如,为了查看员工所在的部门和职位,我们需要关联查询employee、department以及job表。
如果表中的数据量很大,多表连接可能会导致大量的磁盘I/O,从而降低数据库的性能。因此,有时候为了提高查询性能,可以降低规范化的级别,也就是反规范化(Denormalization)。
常用的反规范化技术包括增加冗余字段、增加计算列、将小表合成大表等。例如,我们需要连接查询department和employee,才能得到每个部门的员工数量。此时,我们可以在department表中增加一个存储员工数量的字段(emp_count),然后直接查询部门表就可以得到所需的信息。不过,我们每次增加或者删除员工时,需要同步更新部门表中的emp_count字段。
规范化增加了数据维护的开销和数据的冗余,可能会导致数据完整性和一致性的问题。因此,我们通常应该先进行规范化设计,再根据实际情况考虑是否需要反规范化。一般来说,数据仓库(Data Warehouse)和在线分析处理(OLAP)数据库会用到反规范化技术,因为它们以复杂查询和报表分析为主。