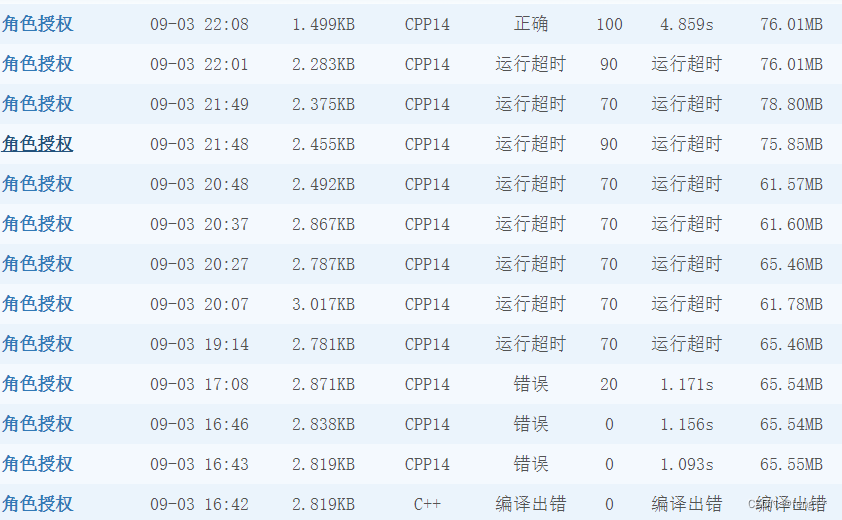
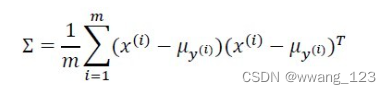损失函数和后向传播
铰链损失函数:SVM常用,打击和正确结果相似度高的错误答案
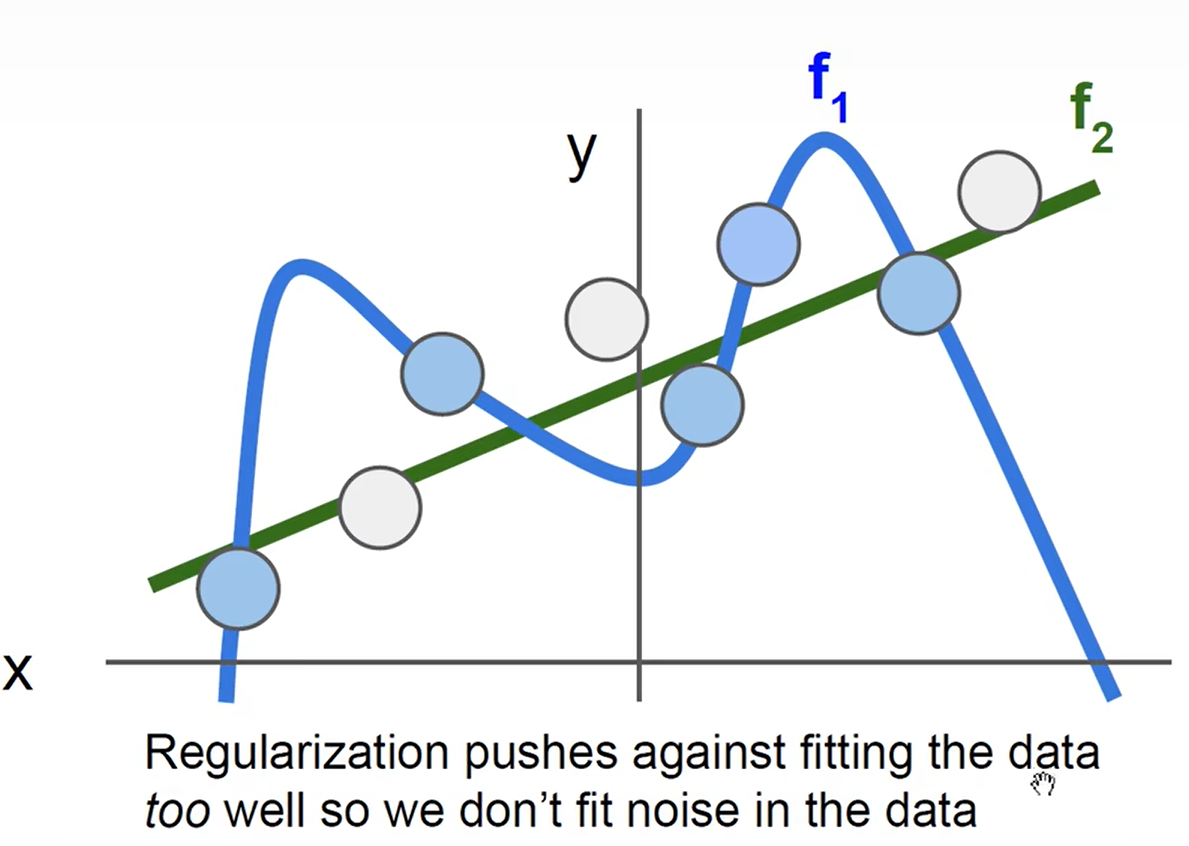
正则化:获得更简单的模型,获得更平均的模型,避免过拟合(绿色线)
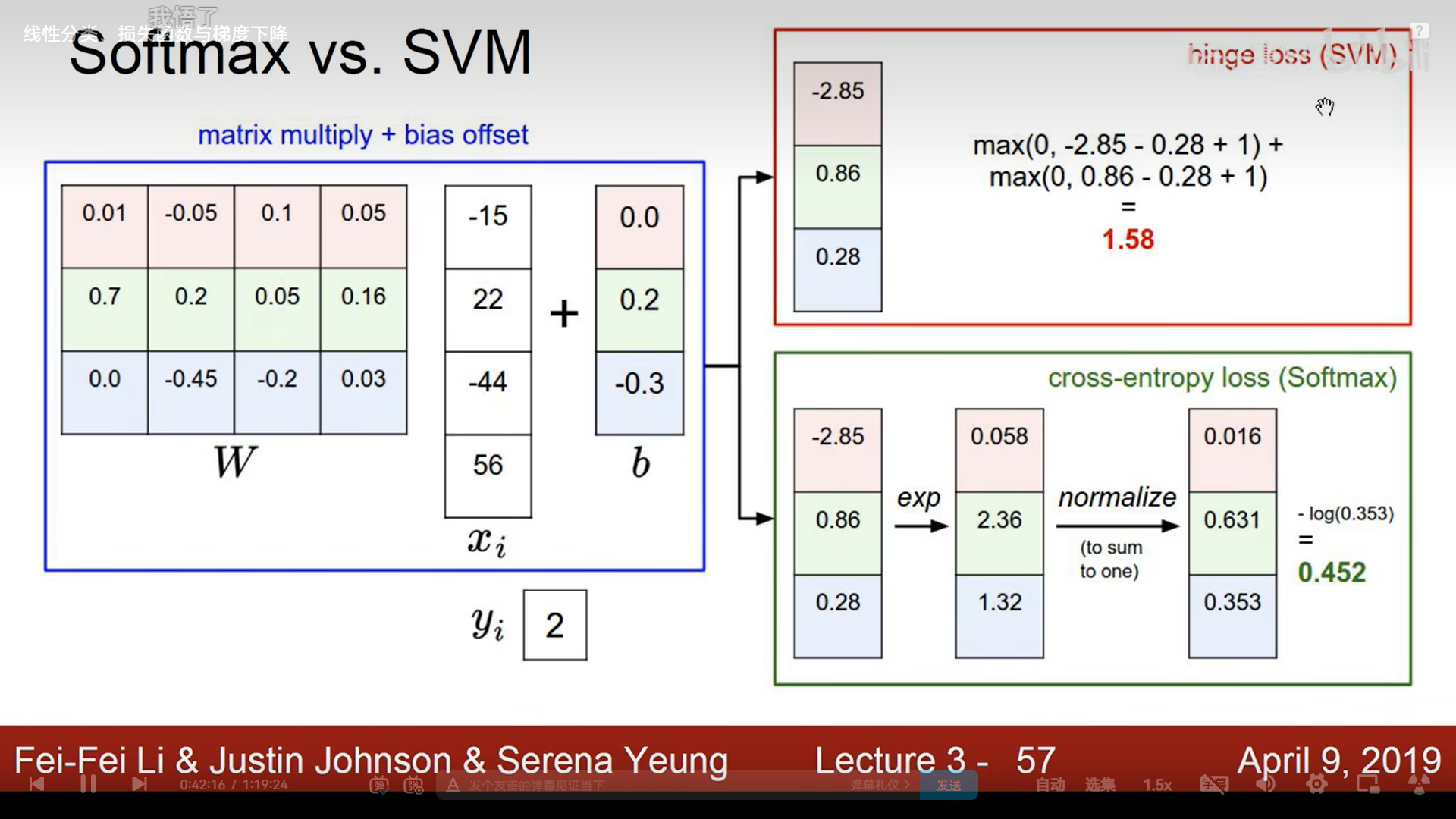
Softmax:先指数计算(去除负数,增加差异性),再归一化得到概率

交叉熵损失函数:取对数

optimization:梯度下降的反向调节过程,目的是使得损失函数变小;
梯度:就是导数,不过调节时要反过来
学习率:其实就是下面这个step_size,决定了是大踏步下山还是小碎步下山

损失函数和后向传播
铰链损失函数:SVM常用,打击和正确结果相似度高的错误答案
正则化:获得更简单的模型,获得更平均的模型,避免过拟合(绿色线)
Softmax:先指数计算(去除负数,增加差异性),再归一化得到概率
交叉熵损失函数:取对数
optimization:梯度下降的反向调节过程,目的是使得损失函数变小;
梯度:就是导数,不过调节时要反过来
学习率:其实就是下面这个step_size,决定了是大踏步下山还是小碎步下山