CS231n
CS 程序:https://cs.stanford.edu/people/karpathy/convnetjs/demo/cifar10.html
CS 课件http://cs231n.stanford.edu/slides/2017/:
CS 课程首页:http://cs231n.stanford.edu/
CS 附带教程网页版:https://cs.stanford.edu/people/karpathy/convnetjs/
数据集CIFAIR10
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w2J236td-1665138472309)(https://api.bilibili.com/x/note/image?image_id=169754)]

如何比较图片,比较测试图片和训练图片
方法1曼哈顿距离
像素值相减的绝对值求和
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-stceGwSX-1665138472311)(https://api.bilibili.com/x/note/image?image_id=169755)]

对于这种方式的优缺点
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g6Cax7ei-1665138472312)(https://api.bilibili.com/x/note/image?image_id=169756)]

KNN
K最近邻算法:根据一部分的样本的点数分类,K越大,越平滑
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wdHsJDSj-1665138472313)(https://api.bilibili.com/x/note/image?image_id=169757)]

KNN:DM

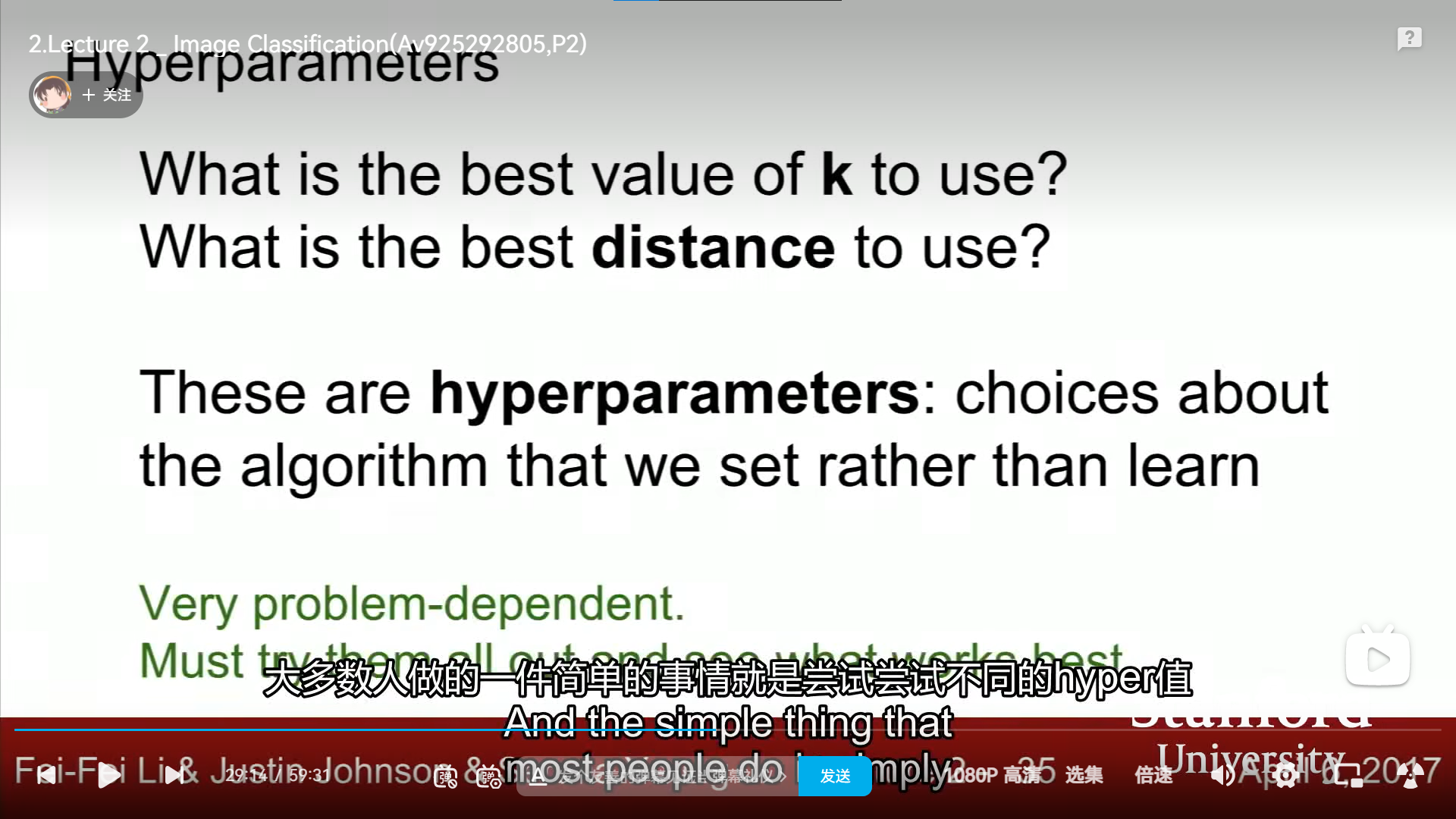
hyperparameters:(超参数)

KNN几乎从来没有使用过 tint:染色,着色


关于选择超参数的方法,各种方法的优劣
其中validation和train的区别:validation可以看到训练的标签,但是train不能看到,test是最后的验证
[外链图片转存中…(img-UnrLSkd2-1665138472318)]
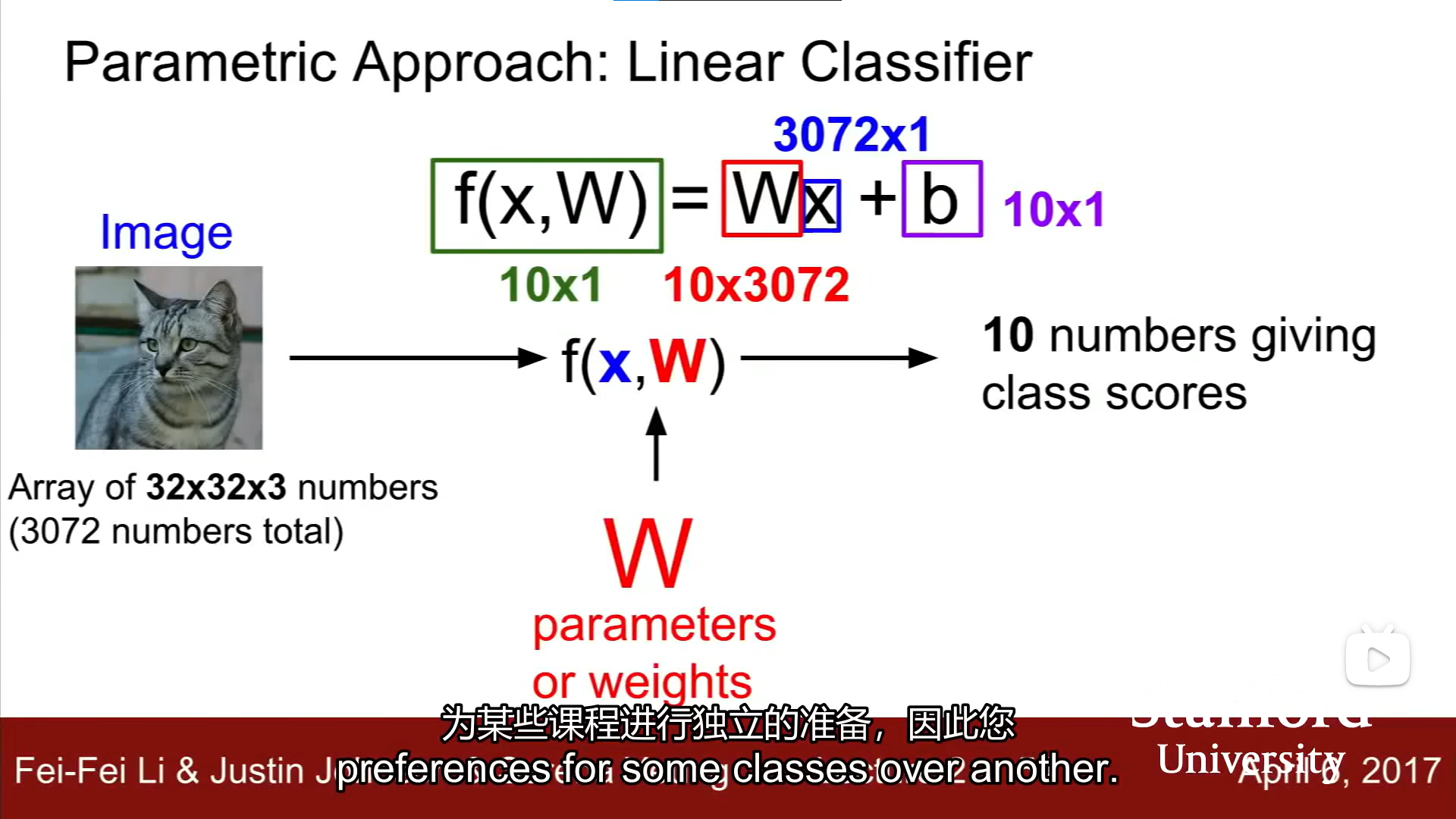
Linear Classification
example关于一个最小的LC

loss founction
对于W的确定好坏

防止分类器走偏,我们需要加入一些诱导函数,类似λR



two lc difference

summary
op
gradient descent(梯度下降)
concolution neural networks(CNN)
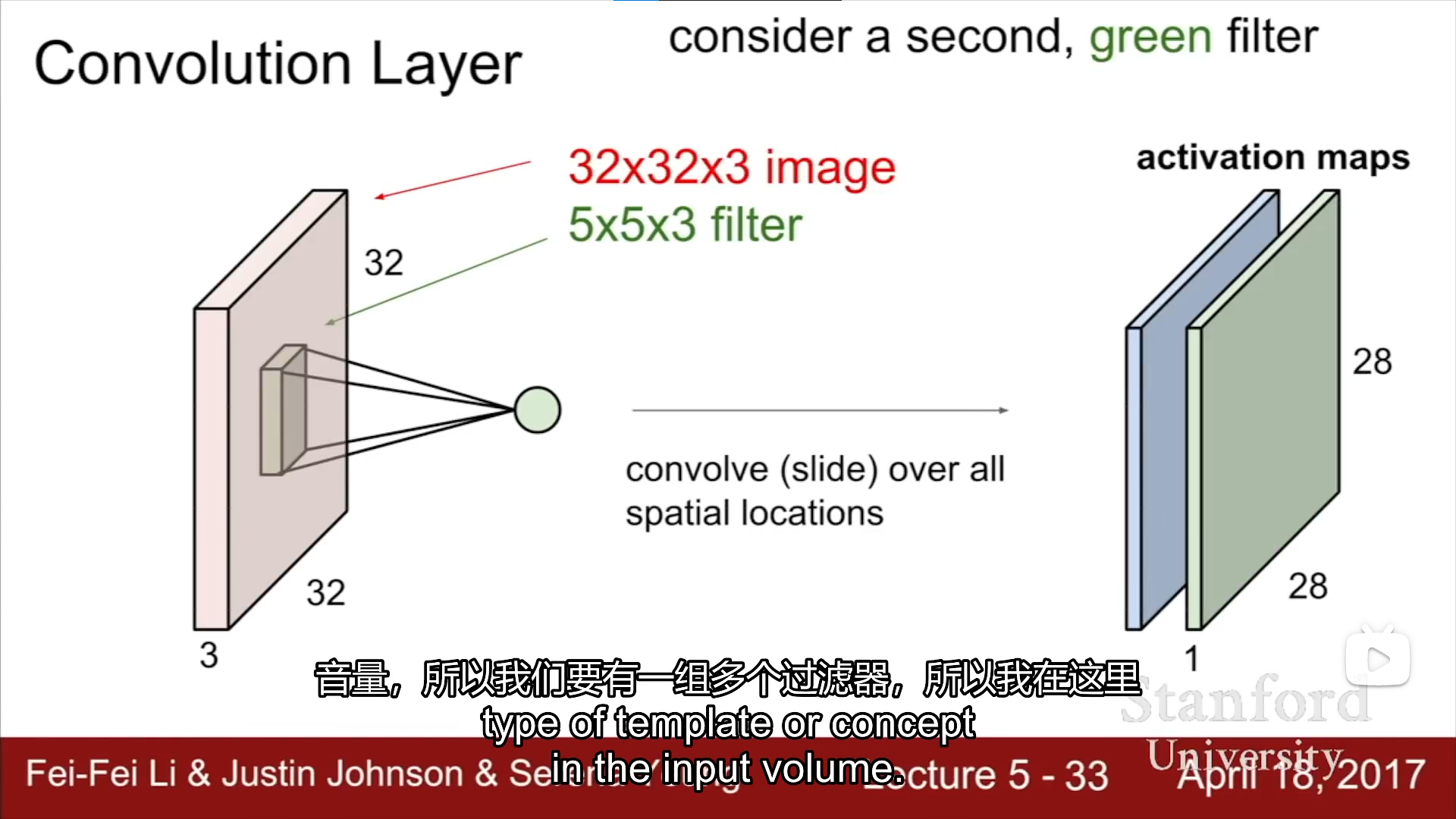
convolution layer

32x32x3 经过 5x5x3的扫描(convolution layer)之后 获得一个28x28x1的activation maps
[外链图片转存中…(img-oXqxqaZV-1665138472333)]
stride(步长) plus(+) minus & subtract(-)by(*)divid(/)
有关计算公式

zero pad(区域零补)
作用:可以保持输入输出的大小,
会不会影响输出?会
[外链图片转存中…(img-o1GFT6GW-1665138472337)]
有关pad的选取的一个计算例子&输出的大小
[外链图片转存中…(img-uAU7DD6e-1665138472340)]
关于中间层W的参数计算
[外链图片转存中…(img-efkS3Lr8-1665138472342)]
Pooling layer
-使代表数据更具管理性,更小,但是本质不作任何数学处理
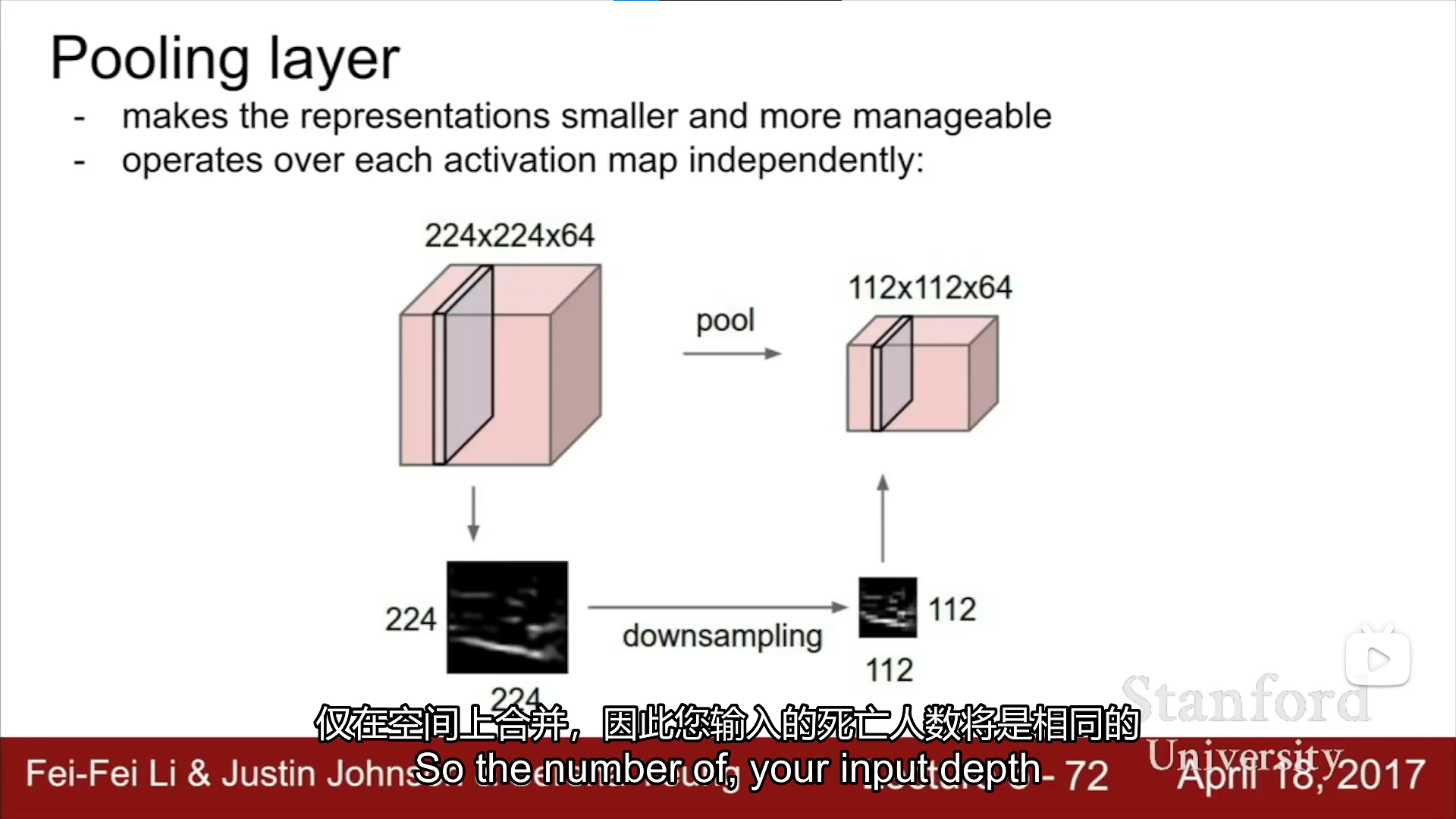
最常用的max pooling
在所选的范围内选取每个范围最大的数值组成新的输出
通常使用的滤波器大小为 F=2,S=2;F=3,S=2
而且zero-padding(边缘加0保持输出大小)并不在pooling layer中使用

经过池化之后的输出大小为
fully connection layer(FC layer)?

???完全不懂,貌似就是把之前的一些东西连接起来,几乘几乘几之类的
training nural networks
part1
activation functions
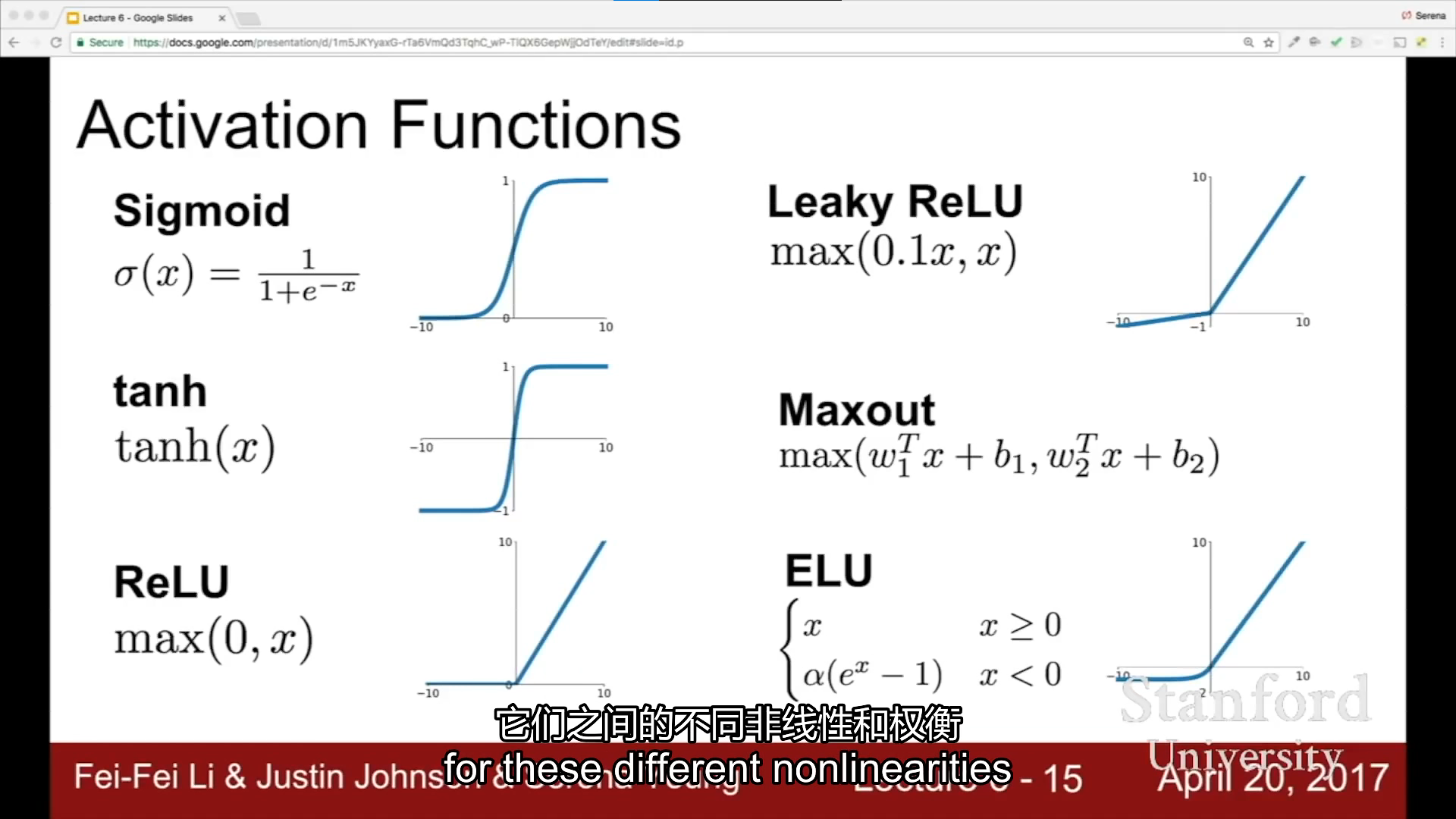
sigmoid

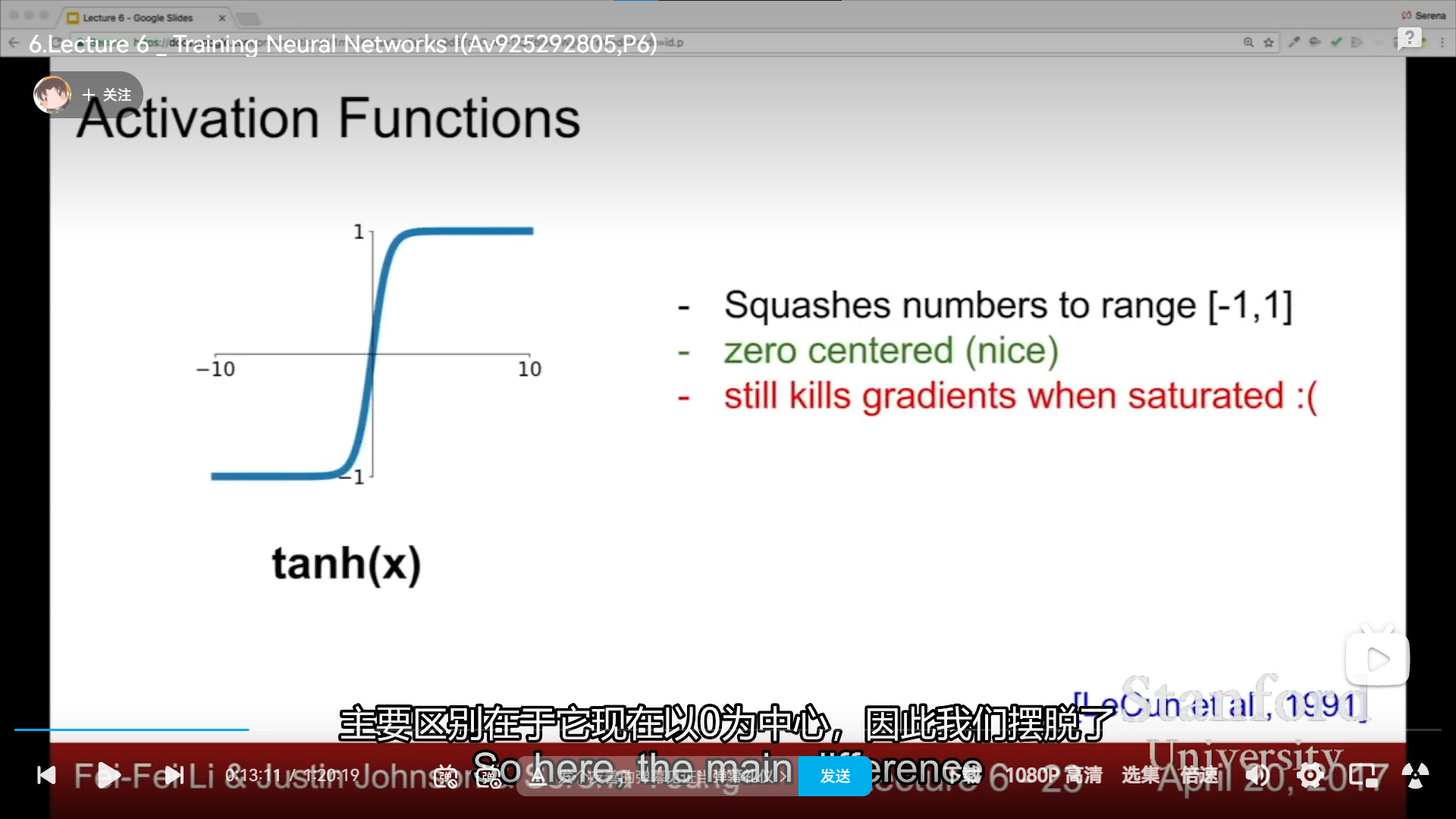
tanh

ReLU
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5QtKNoAO-1665138472349)(C:\Users\光明斗士\AppData\Roaming\Typora\typora-user-images\image-20220814215626405.png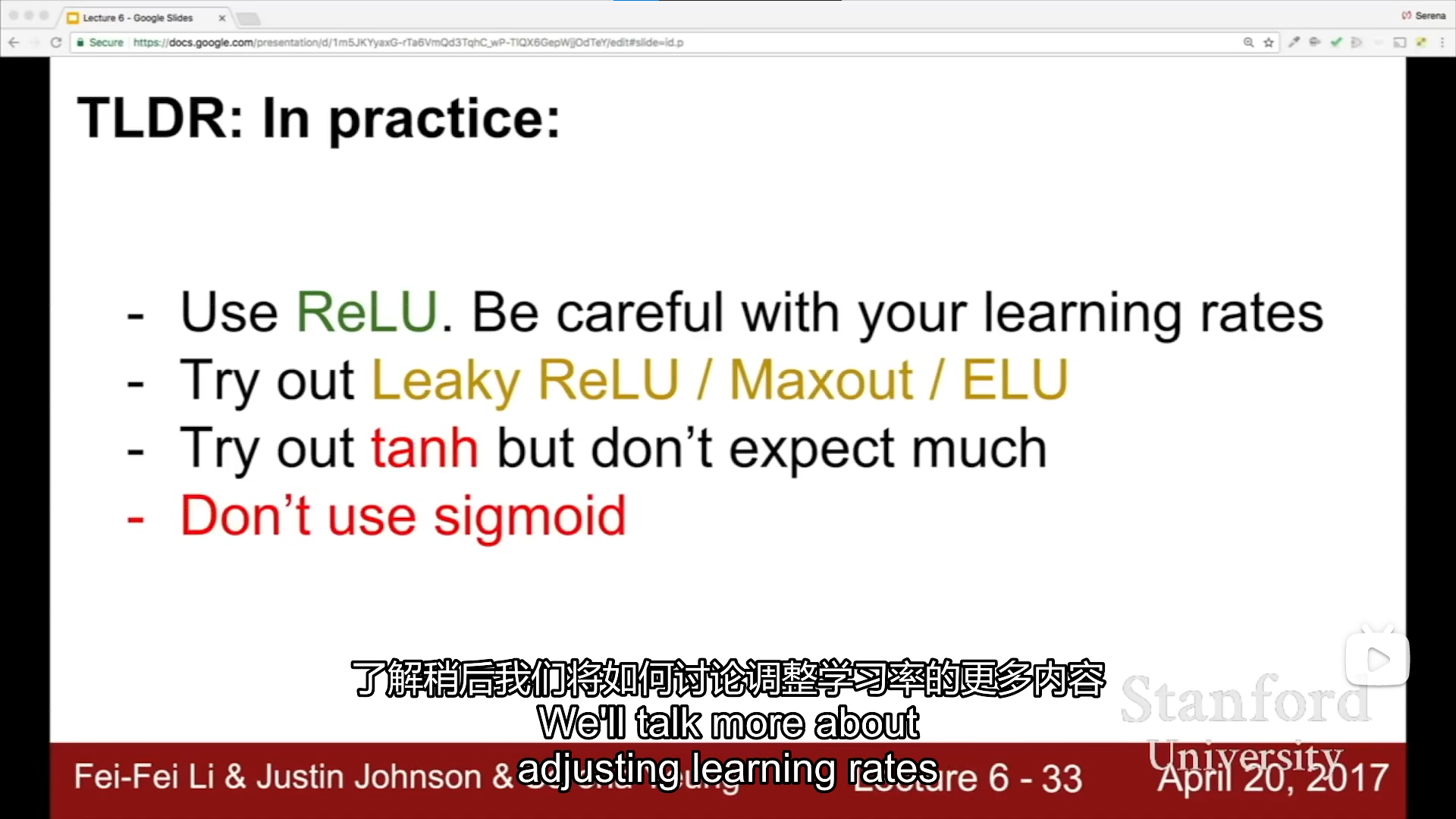 ]
]
leaky ReLU & parametric ReLU
[外链图片转存中…(img-hkYOmMwc-1665138472350)]
exponential linear units
[外链图片转存中…(img-3hsxRtMr-1665138472351)]
notes
[外链图片转存中…(img-curVquFa-1665138472351)]
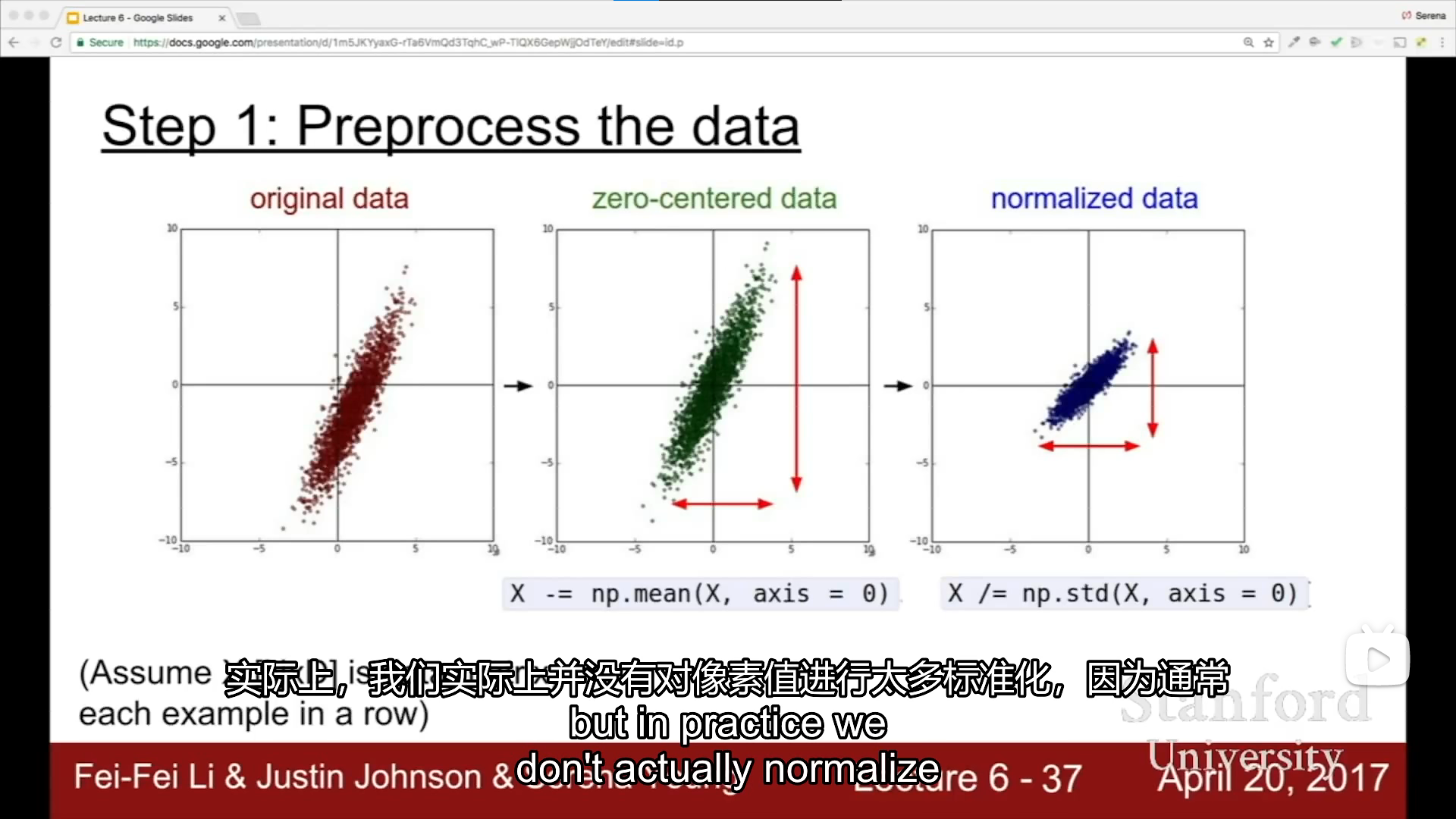
data preprocessing
[外链图片转存中…(img-agqifQ5D-1665138472352)]
weight initialization
first idea

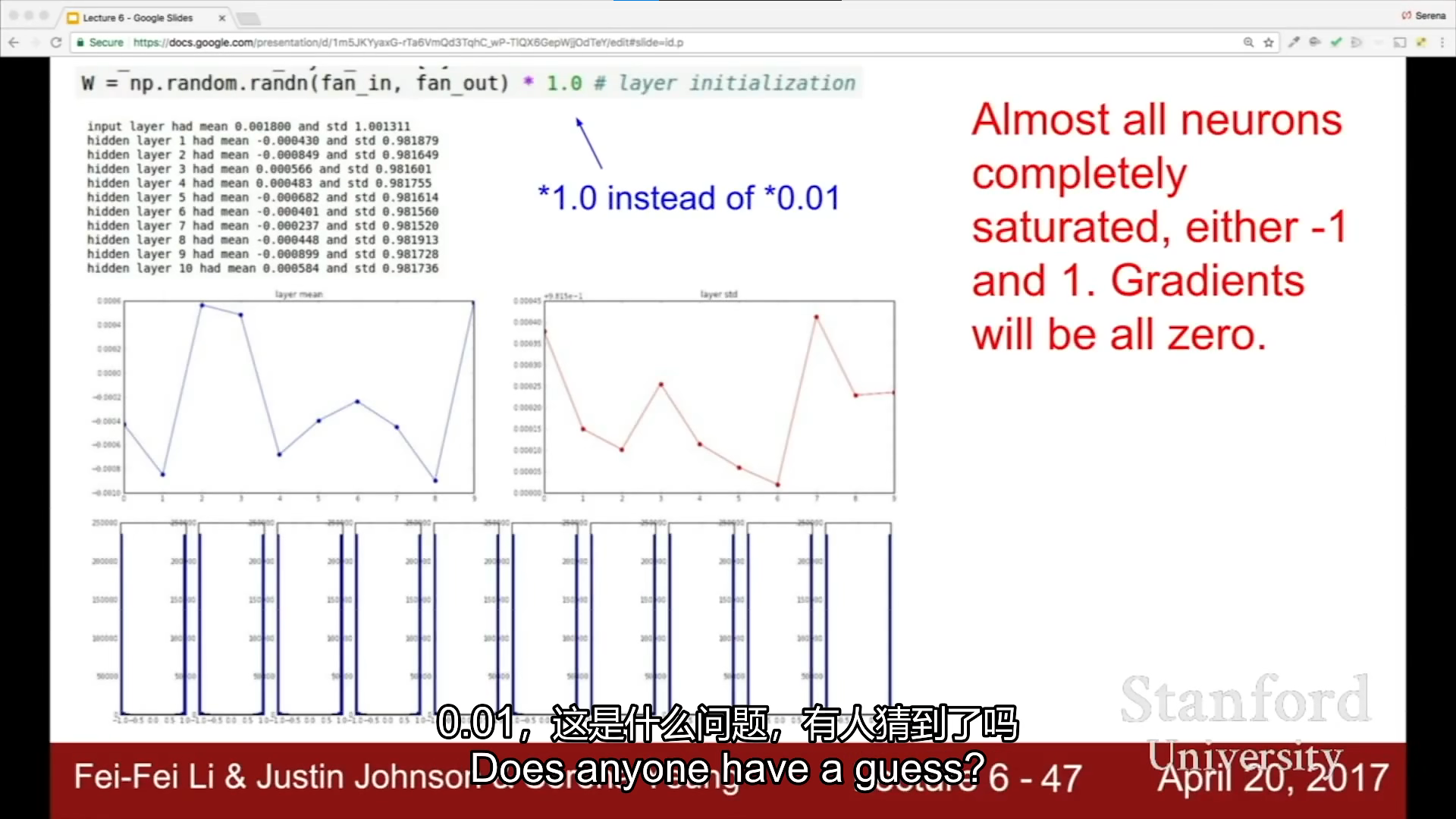
batch normalization
[外链图片转存中…(img-jlC0Ym2H-1665138472355)]
我突然发现,老外的课就是个引子,给了很多其他的资源需要自己去看的,跟国内的很不同,国内基本把东西都讲完了,国外需要自己看,自己去发掘

babysitting the learning process
????
hyperparameter optimization
[外链图片转存中…(img-xwpcQk14-1665138472357)]
[外链图片转存中…(img-xEb7DJhQ-1665138472358)]
SGD(梯度下降)



[外链图片转存中…(img-NBDBIwgF-1665138472362)]