概述
- 海明校验码又可以称为汉明校验码, 这只是一个音译的问题, 作者是 Richard Hamming
- 海明校验码对于信息纠错这个领域的贡献十分巨大,Richard Hamming 获得了1968年的图灵奖
- 内容主要包括:海明校验码的思想、如何构建海明校验码、如何使用海明校验码
海明校验码的思想
回顾奇偶校验码
- 奇校验码: 整个校验码(有效信息位和校验位) 中 “1” 的个数为奇数
- 偶校验码: 整个校验码(有效信息位和校验位) 中 “1” 的个数为偶数
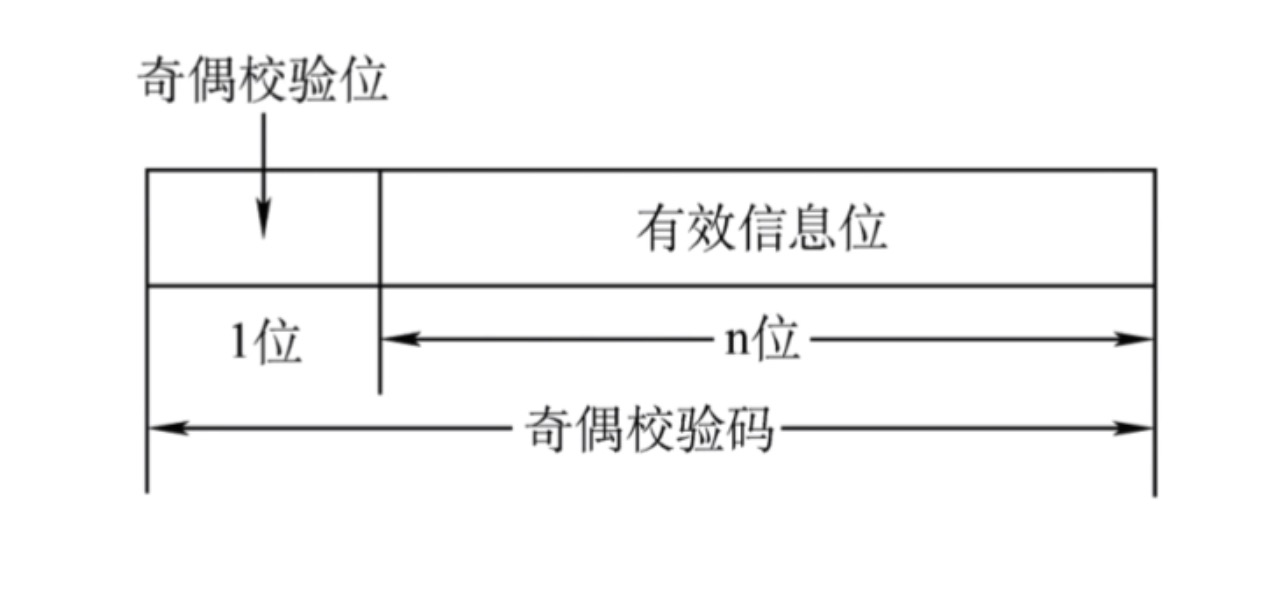
- 其思想是:对于n个有效的信息位, 我们只需要在首部或者尾部添加一个奇校验位或者偶校验位,用这样的方式构成奇偶校验码
- 比如对于偶校验来说,1010 这4个信息位,我们需要在头部添加一个0,即:01010, 保证整体来看总共有偶数个1
- 奇偶校验码的一个局限性就是我们只能发现奇数位的错误,但我们无法确定是哪一位出了错,没办法自动的把它进行修正,只能要求数据的传输方重新传送
- 由于奇偶校验的策略我们只添加了一个校验位,也就是一个比特的信息,而一个比特的冗余信息,显然它只能携带两种状态,也就是只能反馈对或者错这样的两种状态
海明校验码
- 海明码是基于偶校验的一个拓展, 对于n个有效的信息,我们会把它分为k个分组,然后对k的分数分别的进行偶校验
- 也就是说每一个分组会对应一个校验位,最终我们会携带k个校验位, 可以反映更多种状态的信息
- 除了反馈对错之外,我们还可以知道哪一位出了错, 这就是海明码的设计思想
- 基于这个思路,需要探讨几个问题
- 第1个问题,我们需要把这n个信息位分为多少个分组
- 第2个问题这n个信息位,我们怎么把他们分派到各个分组当中
- 第3个问题是基于海明校验码进行检错和纠错
1 ) 需要设置多少个校验位
- 假设信息位(n个) 添加的冗余校验位(k个)
- 我们期待,这k个校验位除了能反映对错之外,还能指明是哪一个比特位出现了错误
- k个比特能表示2的k次方种状态,而海明校验码整体来看,是信息位 + 校验位
- 也就是说, 海明校验码位数 = n + k, 而这n+k位都可能出错
- 那么这2的k次方种状态当中需要包含n+k种情况,那除了出错的这n+k种情况之外,还需要包含一种正确的状态
- 因此我们可以得到这样的一个不等式: 2 k ≥ n + k + 1 2^k \geq n + k + 1 2k≥n+k+1, 我们需要通过这个不等式来确定我们需要添加多少个校验位
- 如果有4个信息位,那么我们就只能取k等于3才能满足这个式子: 2 3 ≥ 4 + 3 + 1 2^3 \geq 4 + 3 + 1 23≥4+3+1
- 下面这个表给出了n和k的一般对应关系,可记忆,或者自己推
| n | 1 | 2-4 | 5-11 | 12-26 | 25-57 | 58-120 |
|---|---|---|---|---|---|---|
| k | 2 | 3 | 4 | 5 | 6 | 7 |
- 基于上述结论,如果说有4个信息位的话,那么我们可以确定我们要添加的校验位的数量k=3,也就是说最终我们生成的海明校验码应该是4+3=7位
2 ) 如何分组
- 为了区分信息位和校验位, 我们用D1D4来表示这4个信息位,然后用P1P3来表示这三个校验位,用H1~H7来分别对应最终的这7位海明码
- 那这些信息位和校验位应该放到什么位置呢?
- 一个很容易想到的办法是把这三个校验位放到头部的位置,然后把4个信息位放到尾部的位置
- 但是海明码不能这么做,有一些特殊的规定,在海明校验码中规定所有的校验位 P i P_i Pi应该分别放在 2 i − 1 2^{i - 1} 2i−1这些位置上
- 也就是说P1P2P3,这几个校验位,应该分别把他们放到: 第1、2、4这几个位置,那如果还有一个校验位P4的话,那显然应该放到第8的位置
- 规律是:和我们二进制的权值的上升关系是相符合的, 比如:1、2、4、8、16
- 所以我们可以把这些校验位所放的位置, 看作是这个校验位它所对应的某一种权值
- 总之, P1放到第1个位置,然后P2放到第2个位置,P3要放到第4个位置,剩下位置存放其他的信息位, 如下表所示
| H7 | H6 | H5 | H4 | H3 | H2 | H1 |
|---|---|---|---|---|---|---|
| D4 | D3 | D2 | P3 | D1 | P2 | P1 |
| 1 | 0 | 1 | 0 |
- 目前为止我们已经确定了,基于上述的例子,我们需要添加三个校验位
- 或者换一个角度来说,需要把这些信息被分为三个分组,每个分组分别进行偶校验
- 因此接下来我们应该确定一种规则,就是三个分组当中应该分别包含哪几个信息位
- 当我们确定了如何分组之后,那么与这个分组相对应的偶校验位的值就很好确定了
- 来看一下怎么做,需要把这些信息为他所处的位置的序号用二进制的形式表示
- 比如,对于D1这个信息来说,它所处的位置是3, 那么3的二进制表示应该是011, 每个二进制位的权重是1、2、4(从低到高),011的值就是2+1=3
- 而下一个信息位是D2,它所处的位置是5,那么我们用二进制表示应该是101,此时,4+1=5
- 而D3所处的位置是6,那么6用二进制表示应该是110,此时,4+2=6
- 最后是D4,它处于7这个位置,用二进制表示就是111, 此时,4+2+1=7
- P1、P2、P3 分别把它放到1、2、4这些位置,我们可以把它理解为某一种权重,那么这些权重和刚才提到的这三位二进制的权重是一一对应的
- H3: 3 -> 011
- H5: 5 -> 101
- H6: 6 -> 110
- H7: 7 -> 111
- 所以P1这个偶校验位,它所处的分组当中应该有哪些信息位呢?我们只需要把末位为1的这几个信息未把它归为P1所属的分组就可以了
- 也就是如上:H3、H5、H7这几个位置所对应的信息位归为同一个分组,进行偶校验: P 1 = H 3 ⊕ H 5 ⊕ H 7 = D 1 ⊕ D 2 ⊕ D 4 = 0 P_1 = H_3 \oplus H_5 \oplus H_7 = D_1 \oplus D_2 \oplus D_4 = 0 P1=H3⊕H5⊕H7=D1⊕D2⊕D4=0
- 只需要把这个组里面的所有信息位进行异或运算,就可以确定我们的P1应该取0还是取1, 这就是P1的一个计算方式
- 接下来第2个分组,我们应该让它包含H3、H6和H7所对应的这几个信息位, 获得偶校验位: P 2 = H 3 ⊕ H 6 ⊕ H 7 = D 1 ⊕ D 3 ⊕ D 4 = 1 P_2 = H_3 \oplus H_6 \oplus H_7 = D_1 \oplus D_3 \oplus D_4 = 1 P2=H3⊕H6⊕H7=D1⊕D3⊕D4=1
- 最后一个分组的确定方法也是一样的:H5、H6、H7, 也就是D2、D3、D4,它们从属于同一个分组,把它们异或可以得到偶校验位的值: P 3 = H 5 ⊕ H 6 ⊕ H 7 = D 2 ⊕ D 3 ⊕ D 4 = 0 P_3 = H_5 \oplus H_6 \oplus H_7 = D_2 \oplus D_3 \oplus D_4 = 0 P3=H5⊕H6⊕H7=D2⊕D3⊕D4=0, 这时候我们已经全部确定了海明校验码的值
| H7 | H6 | H5 | H4 | H3 | H2 | H1 |
|---|---|---|---|---|---|---|
| D4 | D3 | D2 | P3 | D1 | P2 | P1 |
| 1 | 0 | 1 | 0 | 0 | 1 | 0 |
3 ) 检错和纠错
- 怎么检测出错误呢?其实就是把各个分组内的这些二进制比特币进行一个异或运算, 也就是对这个分组进行偶校验
- 如果说这个分组内没有出错的话,那么进行异或运算得到的结果应该是0
- 如果现在接收方接收到的数据没有发生任何一个比特的错误,即:1010010,我们根据刚才确定的这三个分组对每个分组内的这些比特位依次进行异或运算
- 因为每个分组都有偶数个1,所以异或之后肯定都是000,这是没有出错的情况
- S 1 = P 1 ⊕ D 1 ⊕ D 2 ⊕ D 4 = 0 ⊕ 0 ⊕ 1 ⊕ 1 = 0 S_1 = P_1 \oplus D_1 \oplus D_2 \oplus D_4 = 0 \oplus 0 \oplus 1 \oplus 1 = 0 S1=P1⊕D1⊕D2⊕D4=0⊕0⊕1⊕1=0
- S 2 = P 2 ⊕ D 1 ⊕ D 3 ⊕ D 4 = 1 ⊕ 0 ⊕ 0 ⊕ 1 = 0 S_2 = P_2 \oplus D_1 \oplus D_3 \oplus D_4 = 1 \oplus 0 \oplus 0 \oplus 1 = 0 S2=P2⊕D1⊕D3⊕D4=1⊕0⊕0⊕1=0
- S 3 = P 3 ⊕ D 2 ⊕ D 3 ⊕ D 4 = 0 ⊕ 1 ⊕ 0 ⊕ 1 = 0 S_3 = P_3 \oplus D_2 \oplus D_3 \oplus D_4 = 0 \oplus 1 \oplus 0 \oplus 1 = 0 S3=P3⊕D2⊕D3⊕D4=0⊕1⊕0⊕1=0
- 如果说接收方接收到的数据为:1010000,H2这一位发生了错误,也就是P2这个校验位从1变成了0
- 第1个分组进行异或得到了0,第2个分组中由于P2发生了跳变,所以导致第2个分组中,现在只有奇数为1,那么异或出来的结果就是1
- 而第3个分组没有任何一个数据发生跳变,因此异或的结果应该是0
- S 1 = P 1 ⊕ D 1 ⊕ D 2 ⊕ D 4 = 0 ⊕ 0 ⊕ 1 ⊕ 1 = 0 S_1 = P_1 \oplus D_1 \oplus D_2 \oplus D_4 = 0 \oplus 0 \oplus 1 \oplus 1 = 0 S1=P1⊕D1⊕D2⊕D4=0⊕0⊕1⊕1=0
- S 2 = P 2 ⊕ D 1 ⊕ D 3 ⊕ D 4 = 0 ⊕ 0 ⊕ 0 ⊕ 1 = 1 S_2 = P_2 \oplus D_1 \oplus D_3 \oplus D_4 = 0 \oplus 0 \oplus 0 \oplus 1 = 1 S2=P2⊕D1⊕D3⊕D4=0⊕0⊕0⊕1=1
- S 3 = P 3 ⊕ D 2 ⊕ D 3 ⊕ D 4 = 0 ⊕ 1 ⊕ 0 ⊕ 1 = 0 S_3 = P_3 \oplus D_2 \oplus D_3 \oplus D_4 = 0 \oplus 1 \oplus 0 \oplus 1 = 0 S3=P3⊕D2⊕D3⊕D4=0⊕1⊕0⊕1=0
- 现在根据S1~S3组成的数就可以确定,是010这个位出现了错误,那010转换成10进制是2
- 也就是说S3S2S1所组成的这个二进制数指明了我们出错的位置在哪, 如果所得的结果110的话,那么就说明出错的位置是在6这个位置
- 这么神奇的规律背后是什么原理呢?如下图所示
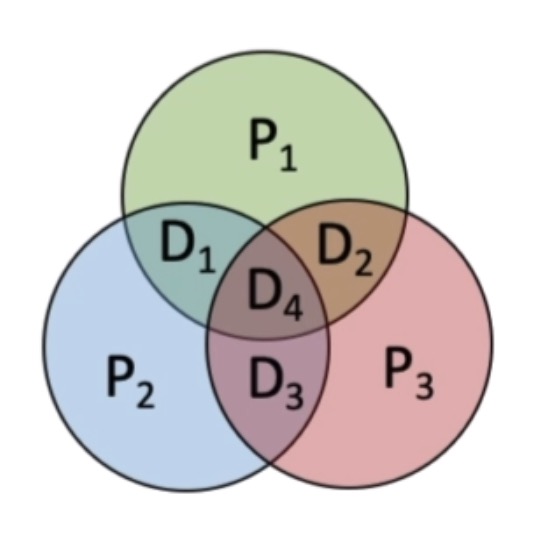
- 这个图里边每一个圆圈表示的是从属于同一个分组的比特位
- P1、D1、D2、D4 从属于同一个分组
- P2、D1、D3、D4 从属于第2个分组
- P3、D2、D3、D4 从属于第3个分组
- 而这三个分组相互之间是有交集的,如果D3这个信息位发生了跳变,由于第2个分组和第3个分组都包含了D3这个信息位
- 因此D3的跳变会导致S2和S3算出来的结果都是1,而S1中所有的信息位都没有跳变,因此, 它出来的结果肯定是0
- 我们最终得到的S3~S1,结果是110, 这个数等于6刚好就指向了D3所对应的位置
- 再比如,假定了P2发生了跳变,那么P2它只从属于第2个分组,因此它只会影响S2的值,而得到的结果,010刚好又是指向了P2所处的位置
- 再举一个例子,如果说是D4发生了跳变,D4从属于所有的这些分组, 因此所有的分组的偶校验,或者说这个异或运算结果
- 肯定都会被影响的, 111对应的十进制是7, 刚好指向了D4它所处的这个位置,这就是海明码的一个纠错原理
海明码的格式变化
- 有时候,海明码的编号是从小到大,但是我们上面探讨的是从大到小
- 其实从小到大的做法是一模一样的,只不过是左右方向换了而已,在做法上没有任何区别
- 而另外一个要补充的具有一个比特位的纠错能力
海明码的缺点
- 海明码有1个比特位的纠错能力,有两个比特位的检错能力
- 这里有一个例子,假设我们在传输的过程当中,P1和P2这两个校验位发生了跳变,那么得到的结果就是S1=1, S2=1, S3=0
- 那么按照之前的规则011对应的十进制是3,那这是否说明了H3这个位置出现了错误呢?显然这个结论是不对的
- 此时我们是发生了两个比特位的跳变,我们是没有办法区分到底是一个比特位的错误,还是两个比特位的错误
- 为了解决这个问题实际海明码在使用的时候通常还会在最首部加上一个全校验位
- 所谓全校验就是对我们之前得到的全部的比特信息,统一的进行一次偶校验
- 在上述这个例子当中总共有三个1,所以这个全校验位,我们应该把它设定为1,保证整体来看有偶数个1
| H8 | H7 | H6 | H5 | H4 | H3 | H2 | H1 |
|---|---|---|---|---|---|---|---|
| P全 | D4 | D3 | D2 | P3 | D1 | P2 | P1 |
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
- 如果我们求得的S1 ~ S3全部是0,并且全体的偶校验是成功的,那么就说明此时没有发生错误
- 如果S1~S3都不等于0。并且全体的偶校验失败,那么说明有移位的错误,我们只需要把它纠正就可以
1 ) 纠错场景1
- 比如P1发生了跳变,那么最终我们S1~S3应该是001也就是指向了1这个位置
- 由于P1这一个位发生了跳变就导致整体的偶校验失败的,此时H1这个位置发生了错误,我们只需要把它从1改为0就可以,不需要要求发送方重新发送这个数据
2 ) 纠错场景2
- 如果说有两个位发生了错误,就像刚才那个例子一样,P1、P2同时发生了错误, 那么S1~S3得到的结果应该是011
但这种情况下整体的偶校验是会成功的, 所以此时就说明是发生了两个比特位的错误,由于我们没有办法确定这两个比特位错在哪, 所以就需要要求对方重新传送这些数据
总结
概述
- 在所有的数据校验方式当中海明码是比较难理解的,但是如果我们从它的基本思想出发就能更方便的理解为什么海明码这么设计
- 本质上,它就是把所有的信息位进行分组,然后每一个组都进行偶校验,而每一个分组会对应一个校验位,所以如果有k个分组分组的话,自然就会有k个校验位
- 对于海明码的求解,首先需要确定校验位的位数,接下来需要确定各个校验位还有信息位的分布
- 那所有的这些校验位应该是分布在编号为1、2、4、8、16… 这些具有二进制位权重的位置
- 我们可以把这些校验位的位置信息理解为某一种权重, 这些权重信息可以帮助我们记忆和理解
- 当我们在进行分组的时候,这个分组规则是怎么制定的,每一个校验位所属的分组都应该确保他们拥有偶数的1
- 再进行检错纠错的时候,我们就可以根据各个分组是否满足拥有偶数个1这样的条件来判断哪些分组出现了问题
- 那根据各个分组偶校验的一个结果,我们就可以来判断到底是哪个位置出现了错误
- 关于海明码的纠错和检错能力,为了区分到底是一位错还是两位错,我们通常还会在最高位加上一个全校验位,保证海明码的整体有偶数个1
- 海明码这个知识点同时归属于计算机组成原理和计算机网络
结构树
- 海明码
- 基本思想
- 分组偶校验,多个校验位可反应出错位置
- 求解步骤
- 确定校验位个数(k个校验位,n个信息位) 2 k ≥ n + k + 1 2^k \geq n+k+1 2k≥n+k+1
- 确定校验位分布
- P1、P2、P3 … 分别在 1, 2, 4, 8, 16 …
- 空出来的其他位置一次填入信息位
- 求校验位
- 将信息位的位置序号用k位二进制数表示出来
- 校验位 Pi 与 位置序号 第i位为1的信息位归为同一组, 进行偶校验
- 纠错
- 对P1,P2,P3…所属个分组进行异或(相当于分组偶校验), 求得 S1, S2, S3 …
- S3S2S1 = 000 说明无错误
- S3S2S1 ≠ \neq = 000, 则其值反应出错位置
- 补充
- 海明码有1位纠错,2位检错能力
- 为了区分1位错还是2位错,还需添加"全校验位"对整体进行偶校验
- 注意: 位置编号可能是从小到大的顺序,但是我们的处理方式雷同
- 基本思想