一、软件包管理及shell命令
1.流行的两种软件包管理机制
1.Deb软件包:由Debian Linux首先提出的软件包管理机制
2.RPM软件包:由Redhat Linux推出的软件包管理机制
2.Debian Linux开发了APT软件包管理器
1.检查和修复软件包依赖关系
2.利用Internet网络帮助用户主动获取软件包
3.软件包类型(Ubuntu有两种类型软件包)
1.二进制软件包:包含可执行文件、库文件、配置文件、man/info页面、版权声明和其他文档;
2.源码包:包含软件源代码、版权修改说明、构建指令以及编译工具等;
PS:当用户不确定软件包类型时,可以使用file命令查看文件类型
4.软件包命名
软件名称 软件版本 修订版本 体系架构
e.g.
sl_3.03-16_i386.deb
5.软件包管理工具分类(常见)
1.命令行:dpkg apt
2.文本窗口界面
3.图形界面
6.dpkg相关命令(离线软件包管理)
dpkg -i <package> 安装一个在本地文件系统上存在的Debian软件包
dpkg -r <package> 移除一个已经安装的软件包
dpkg -P <package> 移除已安装软件包及配置文件
dpkg -L <package> 列出安装的软件包清单
dpkg -s <package> 显出软件包的安装状态
7.在线安装软件
step1.下载软件源(可以在终端更新,也可以图形更新)——step2.更新软件包——step3.ping网络——安装软件包(sudo apt-get install 软件名)

8.软件管理相关命令:apt-get(同上)
update——下载更新软件包列表信息
upgade——将系统中所有软件包升级到最新版本
install——下载所需软件包并进行安装配置
remove——卸载软件包
autoremove——将不满足依赖关系的软件包自动卸载
source——下载源码包
build-dep——为源码包构建所需的编译环境
clean——删除缓存区中所有已下载的包文件
autoclean——删除缓存区中老版本的已下载的包文件
check——检查系统中依赖关系的完整性
-d——仅下载软件包,而不安装或解压
-f——修复系统中存在的软件包依赖性问题
-m——当发现缺少关联软件包时,仍试图继续执行
-q——将输出作为日志保留,不获取命令执行进度
--purge——与remove子命令一起使用,完全卸载软件包
--reinstall——与install子命令一起使用,重新安装软件包
-b——在下载源码包后,编译生成相应的软件包
-s——不做实际操作,只是模拟命令执行结果
-y——对所有询问都作肯定回答,apt-get不再进行任何提示
-u——获取已升级的软件包列表
-h——获取帮助信息
-v——获取apt-get版本号
9.查询软件包信息
apt-cache show:获取指定软件包的详细信息(安装状态、优先级、版本等等)
apt-cache policy:获取当前安装状态
apt-cache depends:了解某个软件包依赖于哪些软件包
apt-cache rdepends:了解某个软件包被哪些软件包所依赖
10.shell命令
定时关机与重启
sudo shutdown -h +45(分钟数)
sudo shutdown -r +60(分钟数)
命令格式
多个命令在一行书写时用“;”隔开;
一条命令不能在一行写完时,在行尾使用“\”标明该命令未结束
shell中的特殊字符
通配符:
当需要命令处理一组文件时,可以用通配符:
* 匹配任意长度字符 用file_*.txt,匹配file_wang.txt、file_Lee.txt、file3_Liu.txt
? 匹配一个长度的字符 用file_?.txt,匹配file_1.txt、file_2.txt、file_3.txt
[...] 匹配其中一个指定的字符 用file_[otr].txt,匹配file_o.txt、file_t.txt、file_r.txt
[-] 匹配指定的一个字符范围 用file_[a-z].txt,匹配file_a.txt、file_b.txt、file_z.txt
[^] 匹配其中指定的字符,均可匹配 用file_[^otr].txt,除了file_o.txt、file_t.txt、file_r.txt的其他文件。
管道
将第一个命令的输出作为第二个命令的输入 “|”
e.g. ls /usr/bin | wc -w
输入/输出重定向
是指改变shell命令或程序的标准输入/输出目标,重新定向到新的目标
重定向符 含义 e.g.
>file 将file文件重定向为输出源,新建模式
>>file 将file文件重定向输出源,追加模式
<file 将file文件重定向为输入源
2>或&> 将由命令产生的错误信息输入到文件中
命令置换
定义:将一个命令的输出作为另一个命令的参数
格式:command1 `command2`
e.g.:ls `pwd` :执行结果为显示当前目录的文件内容
二、Linux shell 命令
1.shell基本系统维护命令
a. man、passwd、su、echo命令的用法
man:获取联机帮助
格式:man commandname
功能:提供指定命令commandname的相关信息,包括名称、函数、语法、可选参数等 (使用":q"退出帮助页面)
passwd
格式:passwd username
说明:普通用户只能修改自己的用户口令,超级用户root可以修改所有其他用户的口令
su
格式:su [-c | -m - ] username "-c"表示执行一个命令后就结束;"-m"表示仍保留 变量不变;-表示转换用户身份,同时使用该用户的环境。
用法: su命令用于临时改变用户身份,具有其他用户的权限,普通用户可以使用su命 令临时具有超级用户权限;超级用户也可以使用普通用户完成一些操作;如果 放弃当前用户身份,可以使用exit命令切换回来。
su -l root 切换到超级用户下 环境也是超级用户
su root 只是切换到超级用户下 环境还是普通用户
区分su 和 su -
echo
格式:echo [-n] information
用法:echo命令用于在标准输出——显示器上显示一段文字,一般起到提示作用; 选项-n表示输出文字后不换行。提示信息字符串可以加引号也可以不加。
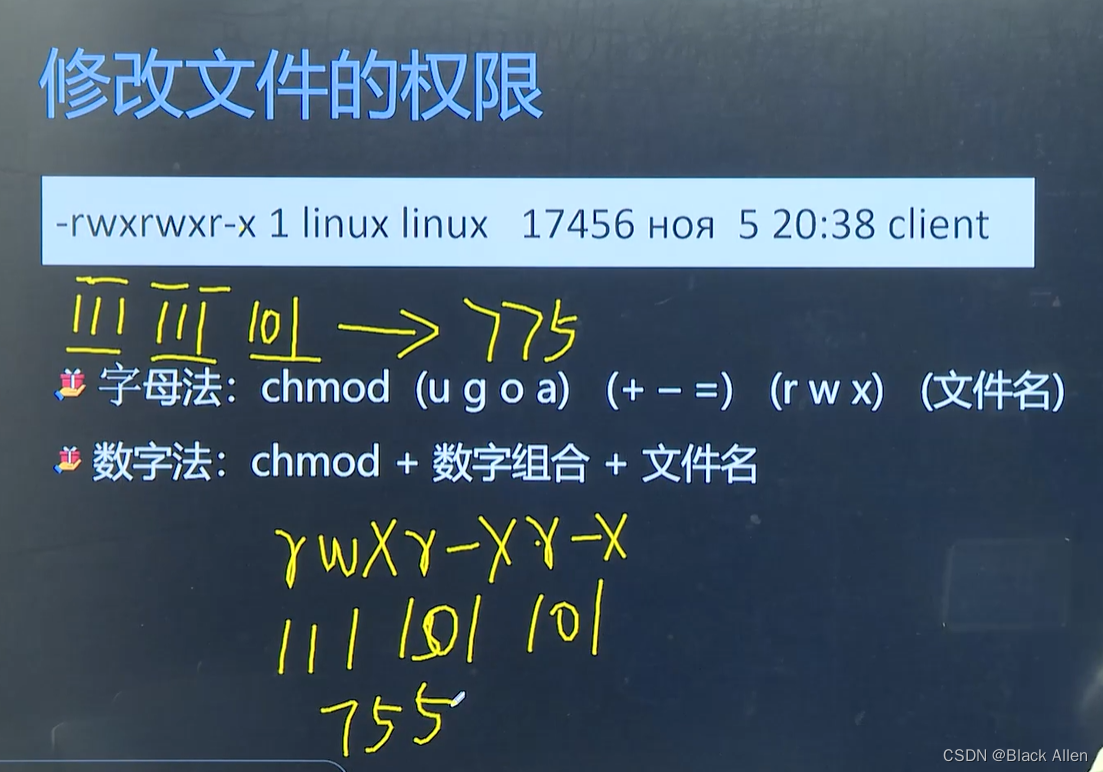
修改文件权限
b. date、clear、df、du命令用法
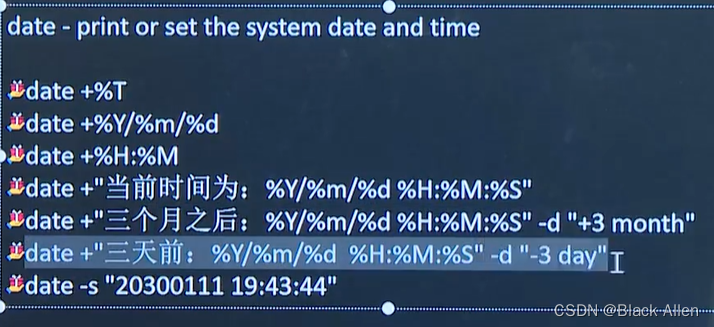
date
格式:date [-d | -s | -u] datestr
用法:date命令用于显示和设置系统日期和时间。选项-s表示按照datestr日期显示格式
clear
快捷键:Ctrl + L
df
格式:df [-a | -T | -h | -k] Filesystem
用法:用于查看磁盘空间使用情况。
du
用法:列出目录和文件所使用的磁盘块数,每块占512个字节
常用参数:
-a:仅列出空闲的文件数
-h:列出磁盘的使用情况(KB)
-s:列出总的空闲空间(KB)
PS:df、du一般在系统出故障时使用!
find 路径 -name/-type 文件名
grep查找文件内容命令

e.g.
grep "hello" file grep -A 2 "hello" file //显示查找内容行和后面的两行 grep -B 2 "hello" file //显示查找内容行和前面的两行 grep -C 2 "hello" file //显示查找内容行和前后的两行 grep -irn -C 1 "hello" . //-i:不区分大小写;-n:显示查找内容在第几行;-r在目录下查找which命令
定位一个命令的位置
e.g. which ls


2.Linux用户管理
a.用户管理相关文件介绍
/etc/passwd文件
用法:/etc/passwd文件时系统能够识别的用户清单。用户登陆时,系统查询这个文 件,确定用户的UID并验证用户口令;
/etc/group文件
用法:包含了unix组的名称和每个组中成员列表,每一行代表一个组,包括四个字段
组名
加密的口令
GID号
成员列表,彼此逗号隔开
adduser
格式:adduser <username>
e.g.:# adduser newuser —— 添加用户名为newuser的新用户
adduser配置文件
路径:/etc/adduser.conf
SKEL模板
用法:/etc/skel目录是被/user/sbin/useradd使用,把想要新用户拥有的配置文 件从/etc/skel目录拷贝,常用文件:
.bash_profile
.bashrc
.bash_logout
.dircolors
.inputrc
.vimrc
b.用户管理相关命令介绍
设置初始口令 passwd
用法:使用passwd命令可以修改用户口令;root用户可以修改任何用户口令;
格式:passwd [-k] [-l] [u] [-f] [-d] username
修改用户属性 usermod
用法举例:将用户oldname改名为newname,同时更改家目录,如下
usermod -d /home/newname -m -l newname oldname
删除用户 deluser
格式:deluser <username>
用法:deluser --remove-home user1 ———删除用户user1同时删除用户的工作目录
添加/删除用户组 addgroup/delgroup
格式: addgroup groupname
用法: addgroup groupname
3.进程管理相关命令
进程的概念
程序的一次执行就是一个进程,程序的两次执行就是两个进程;
也有可能程序一次执行生成多个进程,见level5。
使用命令查看进程 ps
定义:显示进程的动态
格式:ps [options]
用法:ps -elf —— 普通标准
ps -aux —— BSD标准
进程的状态标志
D:不可中断的静止
R:正在执行中
S:阻塞状态
T:暂停执行
Z:不存在但暂时无法消除
<:高优先级的进程
N:低优先级的进程
L:有内存分页分配并锁在内库中
top命令
终止进程 kill
格式:kill [-signal] PID ——signal是信号,PID是进程号
用法:kill命令向指定的进程发出一个信号signal,这个信号是杀死进程的
4.文件系统的类型和结构
a. Linux文件系统
定义
在任何一个操作系统中,文件系统无疑是其最重要的组件,用于组织和管理计算机存 储设备上的大量文件,并提供用户交互接口。用户既可以使用界面友好的Nautilus图形 文件管理器,也可以使用功能强大的shell文件系统管理工具。
文件系统类型
磁盘文件系统
网络文件系统
专有/虚拟文件系统
SCSI与IDE设备命名
sata硬盘的设备名称是"/dev/sda"
IDE硬盘的设备名称是"/dev/hda"
如果很在意系统的高性能和稳定性,应该使用SCSI硬盘 cat/proc/partitions
Linux分区的命名方式
字母和数字的结合
前两个字母表示设备类型
"hd"代表IDE硬盘
"sd"表示SCSI或SATA硬盘
第三个字母说明具体的设备
"/dev/hda(1)"表示第一个IDE硬盘(第一个分区)
"/dev/hdb"表示第二个IDE硬盘
交换分区
将内存中的内容写入硬盘或从硬盘中读出,称为内存交换(swapping)
交换分区最小必须等于计算机的内存
可以创建多个交换分区
尽量把交换分区放在硬盘驱动器的起始位置
b.Linux文件系统的结构
分区和目录的关系
在Windows下,目录结构属于分区;在Linux下,分区属于目录结构;
在Linux中,一切皆文件
Linux文件系统是一个树形的分层组织结构
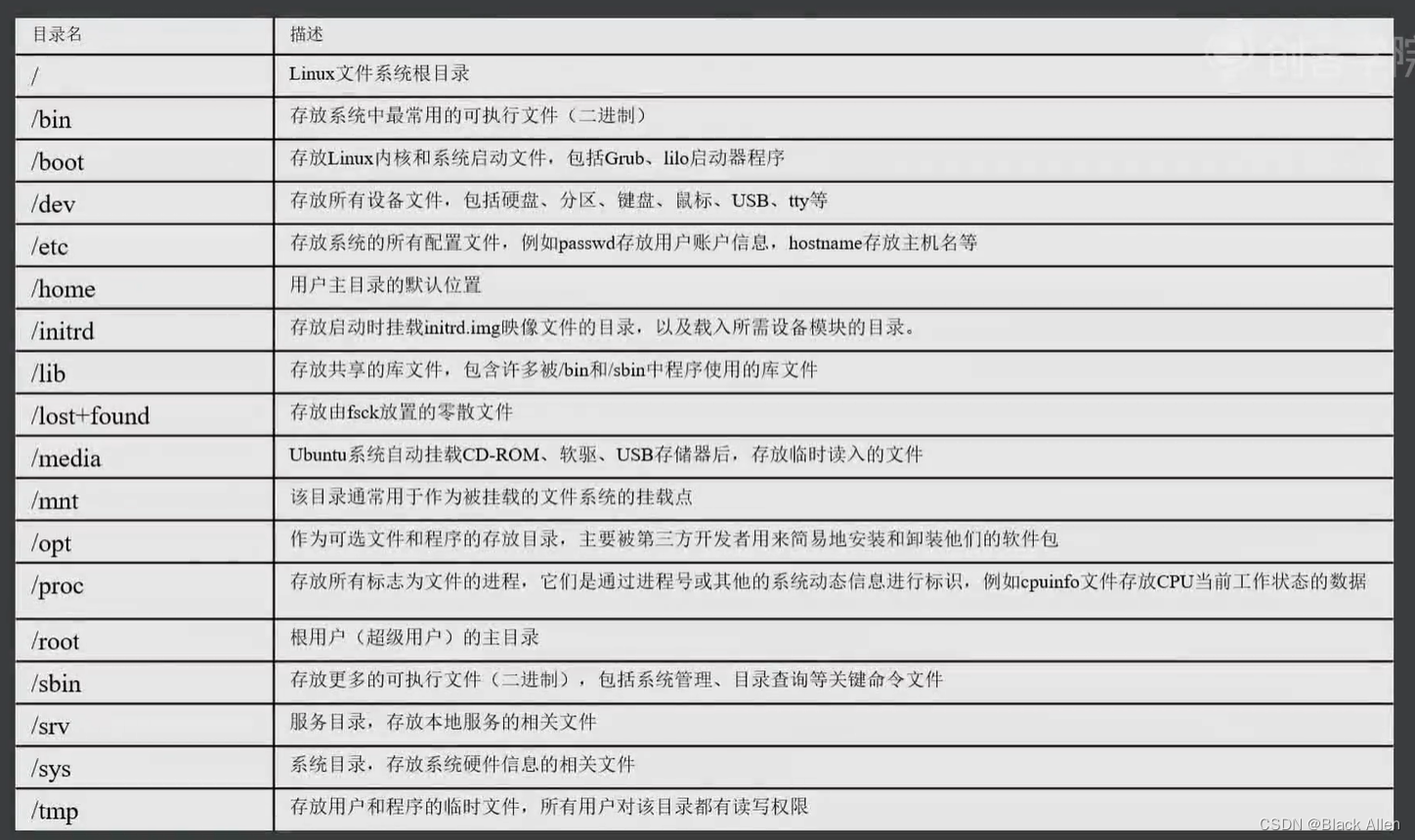
Linux各目录
Linux文件系统与Windows文件系统比较

5.文件系统相关命令
a. file、ln命令
file命令
格式:file [filename]
用法:file命令功能用于判定一个文件的类型。
ln命令、软/硬链接
硬链接:硬链接是利用Linux中为每个文件分配的物理编号——incode建立链接。 因此,硬链接不能跨越文件系统。(相当于Windows的备份)
e.g. ln copy.c copy_link
软连接:是利用文件的路径名建立链接;通常建立软链接使用绝对路径而不是相对 路径,以此最大限度增加可移植性。(相当于Windows下的快捷方式)
e.g. ln -s test.c test_link
区别:如果修改硬链接的目标文件名,链接依然有效;如果修改软链接的目标文件 名,则链接将断开;对一个已存在的链接文件进行移动或删除操作,有可能 导致链接的断开。加入删除目标文件后,重新创建一个同名文件,软链接将 恢复,硬链接不再有效,因为文件的incode已改变。
b. 文件的归档和压缩
定义
归档文件:是将一组文件或目录保存在一个文件中;
压缩文件:是将一组文件或目录保存在一个文件中,并且按照某种存储格式保存在磁 盘上,所占磁盘空间比其中所有文件总和要少。
压缩工具
gzip:是Linux中最流行的压缩工具,有很好的移植性,可在很多不同架构的系统中使用
bzip2:性能上优于gzip,提供最大限度地压缩比率
zip:当用户需要经常在Linux和Windows间交换文件时使用
gzip(压缩)与gunzip命令(解压)
gzip格式:gzip [-l | -d | -num] filename(只能压缩一个文件)
-l:查看压缩文件内的信息,包括文件数、大小、压缩比等参数,并不进行文件解压
-d:将文件解压,功能与gunzip相同
-num:指定压缩比率,num为1~9个等级
gunzip[ -f ] file.gz ————当解压重复时,-f能够起到覆盖同名文件不做提示作用。
tar命令
用法:用于将若干文件或目录合并为一个文件,以便备份和压缩



6.网络配置管理
方法一:虚拟机——设置——硬件——网络适配器——自定义Vmnet0——输入命令ifconfig——写DNS——/etc/resolv.conf
ifconfig:查看网络状态
三、Linux shell脚本编程
1.shell脚本--变量
a .shell脚本的基础知识
shell脚本的本质:shell命令的有序集合
shell编程的基本过程
step1.建立shell文件(.sh):包含任意多行操作系统命令或shell命令的文本文件
step2.赋予shell文件执行权限:用chmod命令修改权限
step3.执行shell文件:直接在命令行上调用shell程序(./文件名 或者 bash 文件名)
e.g. step1、 vi test.sh
#!/bin/bashls pwdstep2、chmod 740 test.sh
step3、./test.sh
b.shell变量
shell允许用户建立变量存储数据,但不支持数据类型(整型、字符、浮点型),将任何赋给变量的值都解释为一串字符。
e.g.1.打印变量
step1、vi val.sh
#!/bin/bashCOUNT=1 #变量名一般大写,等号两边无空格 echo $COUNT #打印变量的值,需在变量前加$step2、chmod 740 val.sh
step3、./val.sh ——结果为1
e.g.2.打印时间
#!/bin/bashDATE=`date` echo $DATE
Bourne Shell有以下四种变量
用户自定义变量(取消变量使用unset 变量名)
位置变量即命令参数
预定义变量
环境变量
2.shell脚本-功能语句
shell程序由零或多条shell语句构成。shell语句包括三类:说明性语句、功能性语句和结构性语句。
说明性语句
以#号开始到该行结束,注释
功能性语句
任意的shell命令、用户程序或其他shell程序
read指令
e.g.1.
step1.vi read.sh
#!/bin/bashread val echo $valstep2. chmod 740 read.sh
step3. ./read.sh
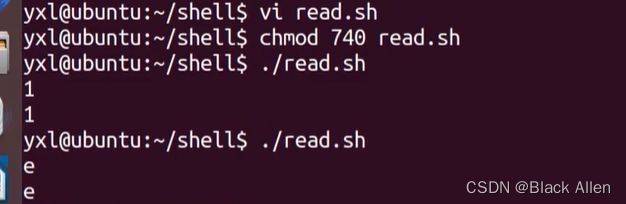
e.g.2.
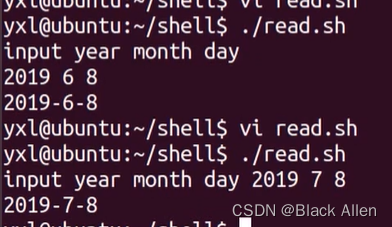
step1. vi read.sh
#!/bin/bashecho "input year month day" read year month day echo $year-$month-$day也可以输入
#!/bin/bash#echo "input year month day" read -p "input year month day" year month day echo $year-$month-$daystep2. chmod 740 read.sh
step1. ./read.sh
expr命令
算术运算命令expr主要用于进行简单的整数运算,包括加(+)、减(-)、乘(\*)、整除(/)和求模(%)等操作。
e.g.
#!/bin/bashread -p "input two number" val1 val2 num=`expr $val1 + $val2` echo $numnum=`expr $val1 - $val2` echo $numnum=`expr $val1 \* $val2` echo $numnum=`expr $val1 / $val2` echo $numnum=`expr $val1 % val2` echo $numtest语句
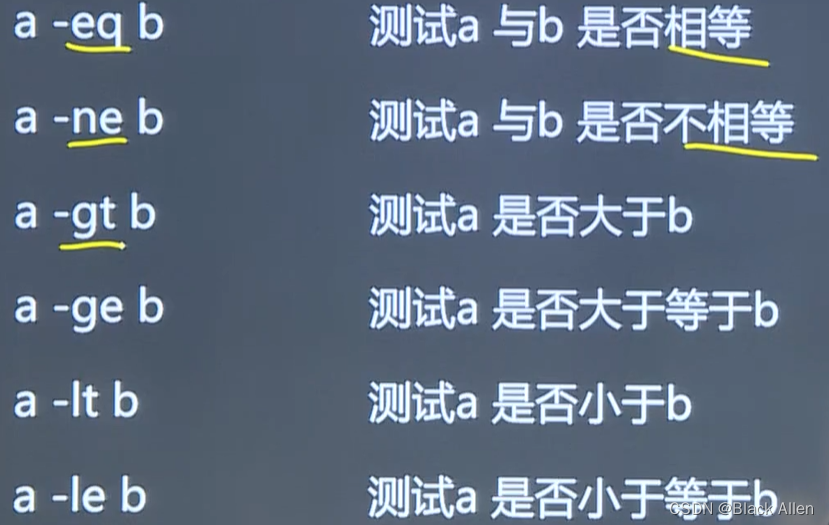
test语句可测试三种对象:字符串、整数、文件属性
字符串测试
#!/bin/bashtest "hello" = "hello" echo $?test "hello" = "hell" echo $?test "hello" != "hell" echo $?test -z "hello" echo $?test -n "hello" echo $?结果为 0 1 0 1 0
结果为0表示正常,1表示不正常
整数测试
test 1 -eq 1 echo "1 -eq 1? $?"输出结果为 1 -eq 1? 0
文件测试
test -d test.sh echo $?test -f test.sh echo $?结果为 1 0
结构性语句
结构性语句主要根据程序的运行状态、输入数据、变量的取值、控制信号以及运行时间等因素来控制程序的运行流程。
主要包括:条件测试语句(两路分支)、多路分支语句、循环语句、循环控制语句和后台执行语句等。


3.shell脚本--分支语句
a.条件语句(类似于C中if-else)
格式:
if 表达式
then
命令表
fi
用法:如果表达式真,则执行命令表中的命令;否则退出if语句,即执行fi后面的语句。
if和fi是条件语句的语句括号,必须成对使用;
命令表中的命令可以是一条,也可以是若干条。
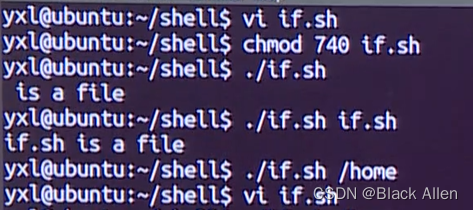
e.g. 文件测试结合if的用法
#!/bin/bashif test -f $1 thenecho "$1 is a file" fi
#!/bin/bashif test -f $1 #此处test可由[]代替,格式为 if [ -f $1 ] 需注意空格 thenecho "$1 is a file" elseecho "$1 is not a file" fi
当情况出现不止两种时用法如下

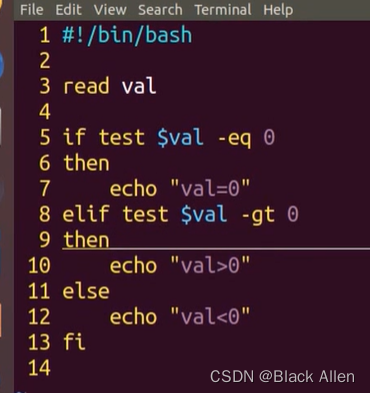
b.多路分支语句(类似于C中switch case)
用法:多路分支语句case用于多重条件测试,语法结构清晰自然
格式:
case 字符串变量 in #case语句只能检测字符串变量模式1) #各模式中可用文件名元字符,以右括号结束命令表1 ;; #注意是两个分号,退出case语句,类似于break模式2 | 模式3) #当多个模式的命令表相同时可以这样表达命令表2 ;;……模式n) #模式n常写为字符*表示所有其他模式,类似于C语言中的default命令表n;; #最后一个双分号可以省略e.g.
#!/bin/bashread -p "input a number " val if [ $val -lt 0 ] || [ $val -gt 100 ] thenecho "input error"exit 0 fi val=`expr $val / 10`case $val in8|9|10)echo "A";;6|7)echo "B";;*)echo "C";; esac
4.shell脚本--循环语句
a.循环语句for的用法
格式:for 变量名 in 单词表
do
命令表
done
e.g.
#!/bin/bash#可以这样使用 for val in 1 2 3 4 5 doecho "val = $val" done#也可以 for ((val=1;val <= 5;val=$val + 1)) #C语言的方式 输出结果和上面一致 doecho "val = $val" done#还可以 for file in `ls` doecho "$---- file" done
b.循环语句while用法
格式:while 命令或表达式
do
命令表
done
e.g.
#!/bin/bash#可以这样写 NUM=0 while [ $NUM -lt 10 ] do echo "***********"NUM='expr $NUM + 1` done#也可以 NUM=0 while (($NUM < 10)) do echo "***********"NUM='expr $NUM + 1` done
c.循环控制语句 (break、continue)
#!/bin/bashNUM=0 while (($NUM < 10)) do if [ $NUM - eq 3 ]thenbreakfiecho "***********"NUM='expr $NUM + 1` doneNUM=0 while (($NUM < 10)) do if [ $NUM - eq 3 ]thenNUM='expr $NUM + 1`continuefiecho "***********"NUM='expr $NUM + 1` done
5.shell编程--函数
a.shell函数调用
#!/bin/bashfun() {A=$1 #当$符号出现在函数里时便不再是命令行参数,而是函数参数B=$2C=$3echo "hello world"NUM=`expr $A + $B + $C`echo "NUM=$NUM" }fun 1 2 3 #传参格式#也可以写作 fun() {A=$1 B=$2C=$3echo "hello world"NUM=`expr $A + $B + $C`#echo "NUM=$NUM"return $NUM }fun 1 2 3 echo "\$?=$?"#与C语言不同的是:函数内部变量的作用域是全局的作用域;如果生 命周期只想在函数内部,需在变量前加上local
四、C语言高级编程
1.gcc编辑器
GNU工具:
编译工具:把一个源程序编译为一个可执行程序
调试工具:能对执行程序进行源码或汇编级调试
软件工程工具:用于协助多人开发或大型软件项目的管理,如make、CVS、Subvision
其它工具:用于把多个目标文件链接成可执行文件的链接器,或者用作格式转换的工具
gcc支持后缀名解释
.c C原始程序
.C/.cc/.cxx C++原始程序
.h 预处理文件(头文件)
.i 已经过预处理的C原始程序
.ii 已经够预处理的C++原始程序
.s/.S 汇编语言原始程序
.o 目标文件
.a/.so 编译后的库文件
编译器的主要组件
分析器:将源语言程序代码转换为汇编语言
汇编器:将汇编语言转换为CPU可以执行字节码
链接器:将汇编器生成的单独的目标文件组合成可执行的应用程序
标准C库:核心的C函数都有一个主要的C库来提供
GCC的基本用法和选项
基本用法:gcc [options] [filenames]
-c:只编译,不连接成为可执行文件,编译器只是由输入的.c等源代码文件生成.o为后缀的目标文件,通常用于编译不包含主程序的子程序文件。
-o:output_filename,确定输出文件的名称为output_filename,同时这个名称不能和源文件同名。
-g:产生符号调试工具(GNU的gdb)所必要的符号咨询,要想对源代码进行调试,我们就必须加入这个选项。
-O:对程序进行优化编译、连接,采用这个选项,整个源代码会在编译、连接过程中进行优化处理,这样产生的可执行文件的执行效率可以提高,但编译、连接的过程变慢。
-O2:比-O更好的优化编译、连接,当然整个编译、连接过程会更慢
-l:dirname,将dirname所指出的目录加入到程序头文件目录列表中,是在预编译过程中使用的参数。
-L:dirname,将dirname所指出的目录加入到程序函数档案库文件的目录列表中,是在链接过程中使用的参数。
GCC的错误类型及对策
第一类:C语法错误:文件source.c中第n行有语法错误
第二类:头文件错误:找不到头文件head.h(Can not find include file head.h)。这类错误是源代码文件中的包含头文件有问题,可能的原因有头文件名错误、指定的头文件所在目录名错误等,有可能错误地使用了双引号和尖括号。
第三类:档案库错误:链接程序找不到所需的函数库
第四类:未定义符号

2.gdb调试工具
格式:gcc -g xxx.c -o xxx (在使用gcc对xxx.c进行编译时,一定要加上选项-g)
gdb xxx
e.g.(test.c为例):step1、gcc -g test.c -o test (产生符号调试工具)
step2、gdb test (进入调试)
step3、l (显示代码,一个l显示10行,再加一个l显示下一个10行)
step4、b 行数 (设置断点)(根据经验判断错误位置)
step5、info b (查看断点)
step6、r (运行代码)
step7、n (一行一行走)
step8、p 变量名 (查看变量值)
step9、s (进入函数)
step10、q (退出调试)
step11、c (走完剩余全部函数)
step12、help (查看gcc用法)
PS:1、在gcc编译选项中一定要加入-g
2、只有在代码处于“运行”或“暂停”状态时才能查看变量值
3、设置断点后程序在指定行之前停止(即会运行指定行)
3.条件编译和结构体
a.条件编译
方法一(ifdef、ifndef):根据宏是否定义
#include <stdio.h>int main(int argc,const char *argv[]) { #ifdef _DEBUG_printf("hello world\n"); #elseprintf("welcome to Beijing\n"); #endifreturn 0; }输出为 welcome to Beijing
#include <stdio.h>#define _DEBUG_ int main(int argc,const char *argv[]) { #ifdef _DEBUG_printf("hello world\n"); #elseprintf("welcome to Beijing\n"); #endifreturn 0; }输出为hello world
#include <stdio.h>int main(int argc,const char *argv[]) { #ifndef _DEBUG_printf("hello world\n"); #elseprintf("welcome to Beijing\n"); #endifreturn 0; }输出为hello world
#include <stdio.h>#define _DEBUG_ int main(int argc,const char *argv[]) { #ifndef _DEBUG_printf("hello world\n"); #elseprintf("welcome to Beijing\n"); #endifreturn 0; }输出为 welcome to Beijing
方法二:根据宏的值
#include <stdio.h>#define _DEBUG_ 1 int main(int argc,const char *argv[]) { #if _DEBUG_printf("hello world\n"); #elseprintf("welcome to Beijing\n"); #endifreturn 0; }输出为hello world
#include <stdio.h>#define _DEBUG_ 0 int main(int argc,const char *argv[]) { #if _DEBUG_printf("hello world\n"); #elseprintf("welcome to Beijing\n"); #endifreturn 0; }输出为 welcome to Beijing
#include <stdio.h>#define _DEBUG_ 0 int main(int argc,const char *argv[]) { #if 0printf("hello world\n"); #elseprintf("welcome to Beijing\n"); #endifreturn 0; }输出为 welcome to Beijing
十一.结构体
1.结构体概述
格式: struct 结构体名
{
结构体成员列表
};
结构体用法一、二、三:
#include <stdio.h> #include <string.h>struct student {int num;char name[10];float grade; }stu3 = {3,"wangwu",96},stu4 = {4,"laoliu",90}; int main(int argc, const char* argv[]) {//1.定义完结构体变量再进行赋值struct student stu1; //struct student 是结构类型,缺一不可stu1.num = 1;//stu1.name = "zhangsan";(错误的)stu1.name[0] = 'z';stu1.name[1] = 'h';stu1.name[2] = 'a';stu1.name[3] = 'n';stu1.name[4] = 'g';stu1.name[5] = 's';stu1.name[6] = 'a';stu1.name[7] = 'n';//也可以用strcpy(stu1.name,"zhangsan"); stu1.grade = 85.5;printf("%d %s %f\n",stu1.num,stu1.name,stu1.grade);//2.定义结构体时进行赋值struct student stu2 = {2,"lisi",90} printf("%d %s %f\n",stu2.num,stu2.name,stu2.grade);return 0; }//3.定义结构体时顺便定义变量struct student{int num;char name[10];float grade;}stu3 = {3,"wangwu",96},stu4 = {4,"laoliu",90};int main(int argc, const char* argv[]){printf("%d %s %f\n",stu3.num,stu3.name,stu3.grade);printf("%d %s %f\n",stu4.num,stu4.name,stu4.grade);return 0;}注意:如果赋值结构体时局部赋值,须表明赋值对象,例如
struct student stu5 = {.num = 5,.name = "lisi", };以上结构体大小测试办法:
printf("%d\n",sizeof(struct student)); //结果为20 printf("%ld\n,sizeof(stu1)); //结果为20 //字节对齐原则
2.结构体数组
结构体数组
#include <stdio.h> #include <string.h>struct student {int num;char name[10];float grade; }; int main(int argc, const char* argv[]) {struct student s[4]; //也可以在数组上直接赋值,使用for语句遍历s[0].num = 1;strcpy(s[0].name,"zhangsan");s[0].grade = 85.5;printf("%d %s %f\n",s[0].num,s[0].name,s[0].grade);return 0; }
3.结构体指针
功能:
通过指针访问结构体中的成员
#include <stdio.h> #include <string.h>struct student {int num;char name[10];float grade; }; int main(int argc, const char* argv[]) {struct student stu1 = {1,"lisi",90}; //赋值法一struct student *p;p = &stu1;//通过结构体指针赋值 p->num = 1;strcpy(p->name,"lisi");p->grade = 90;printf("%d %s %f\n",stu1.num,stu1.name,stu1.grade);printf("%d %s %f\n",(*p).num,(*p).name,(*p).grade);printf("%d %s %f\n",p->num,p->name,p->grade); //最常用return 0; }
4.结构体大小、嵌套及位域
1.结构体嵌套结构体
格式:
struct 结构体名
{
struct 结构体名 成员名;
};
#include <stdio.h>struct person {char name[16];int age;char sex; }struct student {struct person stu;float score; }struct teacher {struct person tea;char phonenumber; }int main() {struct student s;strcpy(s.stu.name,"zhangsan");s.stu.age = 12;strcpy(s.stu.sex,"m");s.score = 98;printf("name = %c, age = %d, sex = %c, score = %f\n",s.stu.name, s.stu.age, s.stu.sex, s.score);struct teacher t;struct teacher *p = &t;strcpy(p->tea.name,"lisi");p->tea.age = 54;p->tea.sex = "w";strcpy(p->phonenumber,"13112341234");printf("name = %c, age = %d, sex = %c, phonenumber = %s\n",p->tea.name,p->tea.age,p->tea.sex,p->phonenumber);return 0; }
2.结构体的大小
#include <stdio.h>struct A {char a;int b;char c;char d; };struct B {char a;short b;char c;char d; };struct C {char a;double b;char c;char d; };int main() {printf("int = %d, %d\n",sizeof(int),sizeof(struct A)); //4,12printf("short = %d, %d\n",sizeof(short),sizeof(struct B)); //2,6printf("double = %d, %d\n",sizeof(double),sizeof(struct C)); //8,16return 0; }字节对齐
字节对齐主要是针对结构体而言,通常编译器会自动对其成员变量进行对齐,以提高存取的效率。
结构体大小的计算方法
自身对齐 //数据类型
默认对齐 //32位电脑默认4字节
有效对齐 //2 4 8
3.位域
定义:
位域是把一个字节中的二进制(8个比特位)分为几个不同的区域,并说明每个区域的位数。每个域有一个域名,允许在程序中按域名进行操作。这样可以把不同的对象用一个字节的二进制来表示。
格式:
struct 位域结构体名
{
位域列表;
};
其中位域列表的形式为:类型说明符 位域名:位域长度
#include <stdio.h>struct A {unsigned char a:2;unsigned char b:3;unsigned char c:3; }//t2 = {2,3,1}; //3.定义位域时定义变量int main() {printf("%d\n",sizeof(struct A)); //打印结果为1//1.先定义再赋值struct A t;t.a = 1;t.b = 2;t.c = 3;printf("%d %d %d\n",t.a,t.b,t.c); //打印结果为1 2 3//2.定义变量时进行赋值struct A t1 = {2,1,3}printf("%d %d %d\n",t1.a,t1.b,t1.c); //打印结果为2 1 3//3.定义赋值后重新赋值t2.a = 3;t2.b = 1;t2.c = 2;return 0; }
5.共用体及typedef
a.共用体
共用体定义:
在C语言中,不同数据类型的数据可以使用共同的存储区域,这种数据构造类型称为共用体。
#include <stdio.h>union gy {int a;char b;struct{int c;float d;}f; };int main(int argc ,const char* argc[]) {union gy n;n.a = 0x12345678;n.f.c = 1; //访问共用体中的结构体printf("%#x\n",n.a); //结果为0x12345678printf("%d\n",sizeof(union gy)); //结果为4printf("%#x\n",n.b); //此处并未赋值b,结果为0x78n.b = 'a';printf("%#x\n",n.a); //结果为0x12345661printf("%#x\n",n.b); //结果为0x61return 0; }
b.typedef
格式:typedef <已有数据类型> <新数据类型>;
e.g.
typedef int INTEGER;
此时 int 等价于 INREGER;
#include <stdio.h> #include <string.h>typedef struct student {int num;char name[10];float grade; }STU1; //此时变量struct student 等价于 STU1 int main(int argc, const char* argv[]) {return 0; }#include <stdio.h> #include <string.h>typedef struct {int num;char name[10];float grade; }STU1,*STU_P; int main(int argc, const char* argv[]) {STU1* P;STU_P q;STU1 stu1;q = &stu1;p = &stu1;stu1.num = 1;strcpy(stu1.name,"zhangsan");stu1.grade = 89.5; printf("%d %s %f\n",stu1.num,stu1.name,stu1.grade);printf("%d %s %f\n",q->num,q->name,q->grade);printf("%d %s %f\n",p->num,p->name,p->grade);return 0; }
6.内存管理
C/C++定义了4个内存区间:
代码区:存放函数体的二进制代码,由操作系统进行管理(cpu执行的机器指令,共享只读)
全局区(全局静态区):存放全局变量和静态变量以及常量(包含const)
栈区:由编译器自动分配释放,存放函教的参数值,局部变量等。
堆区:由程序员分配和释放,若程序员不释放程序结束时由操作系统回收
malloc、free用法(malloc和free必须成对使用)
格式:malloc/free
void* malloc(size_t num)
void free(void* p)
PS:1.malloc函数本身并不识别要申请的内存是什么类型,它只关心内存的总字节数;
2.malloc申请到的是一块连续的内存,有时可能申请的空间较大。有时会申请不到 内存,返回NULL。
3.malloc返回值的类型时void*,所以在调用malloc时要进行类型转换, 将void*转换成所需要地指针类型。
4.如果free的参数是NULL的话,没有任何效果。
5.释放一块内存中的一部分是不被允许的。
#include <stdio.h> #include <stdlib.h> #include <string.h>int main(int argc ,const char* argv[]) {char* p = NULL;p = (char *)malloc(10);strcpy(p,"hello");printf("%s\n",p);free(p);return 0; }注意事项:
1.删除一个指针p(free(p)),实际意思是删除了p所指的目标(变量或对象等),释放了它所占的堆空间,而不是删除p本身,释放堆空间后,p成了空悬指针
2.动态分配失败,返回一个空指针(NULL),表示发生了异常,堆资源不足,分配失败。
3.malloc和free是配对使用的,free只能释放堆空间。如果malloc返回的指针丢失,则所分配的堆空间无法回收,称内存泄漏,同一空间重复释放也是危险的,因为该空间可能已另分配,所以必须妥善保存malloc返回的指针,以保证不发生内存泄漏,也必须保证不会重复释放堆内存空间。
野指针的成因主要有两种:
1.指针变量没有被初始化;
2.指针p被free之后,没有置为NULL,让人误以为p是个合法的指针。指针操作超越了变量的作用范围。
7.动态内存使用
①动态内存分配
申请空间:
#include <stdlib.h>
void* malloc(size_t size);
参数:所需申请空间的大小
返回值:成功 申请空间的首地址
失败 NULL
释放空间:
#include <stdlib.h>
void free(void *ptr);
参数:malloc的地址
返回值:无
#include <stdio.h> #include <stdlib.h>int * fun() {//局部变量a,存放在栈区,空间随着函数结束自动释放//int a = 5;//动态申请空间,存放在堆区,手动释放之后才结束int * a = NULL;a = malloc(12);if(NULL == a){printf("malloc failed\n");}*a = 10;return a; }int main() {int *p = NULL;p = fun();printf("%d\n",*p);free(p);//一个申请只能对应一个释放,不能多次释放return 0; }
五、Makefile
1.Make介绍
定义:
工程管理器,顾名思义,是指管理较多的文件,Make工程管理器也就是个“自动自动编译管理器”,这里的“自动”是指它能够根据文件时间戳自动发现更新过的文件而减少编译的工作量,同时,它通过读入Makefile文件的内容来执行大量的编译工作。
Make将只编译改动的代码文件,而不用完全编译。
Makefile基本结构:
Makefile是Make读入的唯一配置文件
1.由make工具创建的目标体(target),通常是目标文件或可执行文件——生成什么
2.要创建的目标体所依赖的文件——由谁生成
3.创建每个目标体时需要运行的命令——怎么办
注意:命令行前面必须时一个“TAB键”,否则编译错误为:***missing separator. Stop
Makefile格式:
target(生成什么):dependency_files(由谁生成)
<TAB> command(怎么办)
e.g.
hello.o: hello.c hello.h gcc -c hello.c -o hello.o

2.Makefile变量的使用
创建变量的目的:用来代替一个文本字符串:
1.系列文件的名字
2.传递给编译器的参数
3.需要运行的程序
4.需要查找源代码的目录
5.你需要输出信息的目录
6.你想做的其他事情
六、Linux 服务器搭建及使用
1.TFTP服务器
定义:简单文件传输协议是TCP/IP协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务
传输特点

2.NFS服务器
定义:(Network File System)即网络文件系统,其基于UDP/IP使用nfs能够在不同计算机之间通过网络进行文件共享,能使使用者访问网络上其它计算机中的文件就像在访问自己的计算机一样。