目录
为什么会有墓碑?
使用场景
原理
描述
分段
查询
优化点
总结
为什么会有墓碑?
我们知道 TP 数据库一般选择 KV 引擎作为存储引擎,数据库的元数据和数据通过一定的编码规则变成 KV 对存储在存储引擎中,比如 CockroachDB 数据库的编码前缀规则如下。
/Local/… => 节点本地数据
/Meta1/… => 一级路由数据
/Meta2/… => 二级路由数据
/System/… => 系统数据
/Table/… => 表数据我们拿 Table 数据作为例子,表数据划分为系统表数据和用户表数据。用户完成建表和数据插入后,CockroachDB 内部的 SQL-KV 转换模型会将用户表数据转换成一系列 KV 对,按照 Key 顺序存储在存储引擎中。KV 对分为以 Primary Key 为前缀和以Index(二级索引)为前缀的编码,其中以 Primary Key 为前缀的 KV 对存储了用户表的实际数据。
主键索引编码规则:
// Key 编码
/Table/<id>/<index>/<pk val>/<family>Table:表示为行数据的前缀
<id>:表示表 ID
<index>:表示主索引ID
<pk val>:表示主索引的值
<family>:表示列族ID。没有建列族默认为 0// Value 编码
<crc><type>/TUPLE/colIDDiff:colID:type/val/../colIDDiff:colID:type/val/
<crc>: 表示整个 KV 对的 4 字节 CRC 校验码
<type>:表示 1 字节的值类型所以,当我们删除一张表时,其实就是删除了多个具有同样前缀的 KV 对,我们若是用 Tombstone 来标记一下,而不是真正的立即删除多个 KV 对,岂不是速度快了很多~
使用场景
既然删除一张表(写操作)变得那么简单,那么读时该怎么办呢?其实很简单,就是 KV 引擎在查找某个 key 时,若查询到后,会再去墓碑中判断一下该 key 是否已经被删除。举个栗子:
KV 引擎在 sequence = 9 时,查询用户 key="/table/1/xxx",查到结果 value,该 key 的插入 sequence = 6。我们拿 key="/table/1/xxx" 与 sequence = 9 作为入参,查询在当前 sequence 下,用户 key 的最大墓碑覆盖序列号 max_covering_tombstone_seq。
代码描述如下
std::unique_ptr<FragmentedRangeTombstoneIterator> range_del_iter(NewRangeTombstoneIterator(read_opts,GetInternalKeySeqno(key.internal_key()))); // 指定了读操作的 sequence。if (range_del_iter != nullptr) {
*max_covering_tombstone_seq =std::max(*max_covering_tombstone_seq,range_del_iter->MaxCoveringTombstoneSeqnum(key.user_key())); // 查询在当前 sequence 下,用户 key 的最大墓碑覆盖序列号
}若用户 key 的插入 sequence < max_covering_tombstone_seq,则代表被删除了。
if ((type == kTypeValue || type == kTypeMerge || type == kTypeBlobIndex) &&max_covering_tombstone_seq > seq) {type = kTypeRangeDeletion;
}查询原理部分看下面。
原理
描述
struct RangeTombstone {Slice start_key_;Slice end_key_;SequenceNumber seq_;
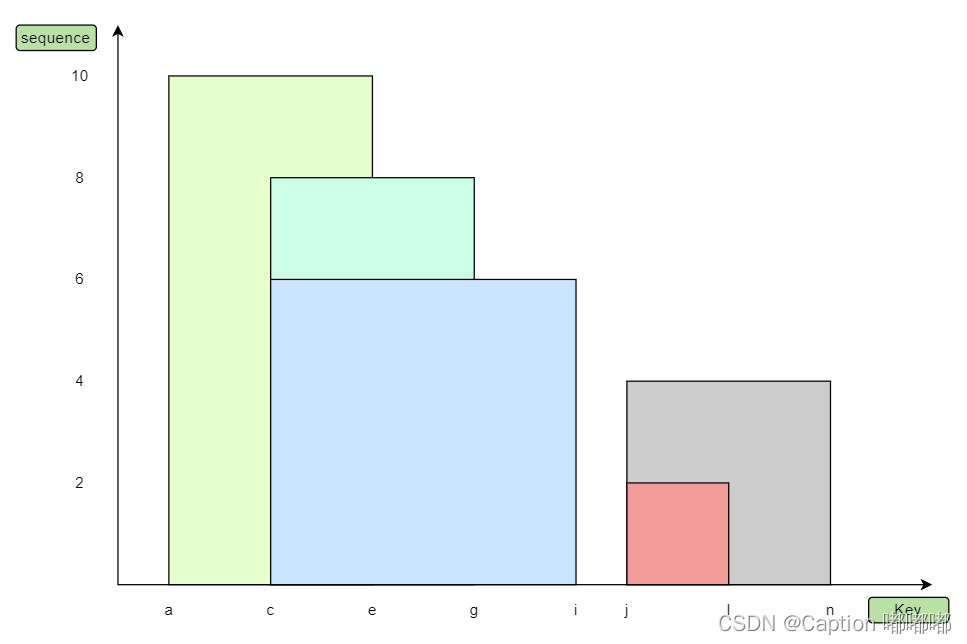
}我们可以看出是由 key 和 sequence 两个维度来描述一个墓碑,代表在 sequence 时刻插入了一条墓碑值。一批墓碑可能产生重叠交叉等,下面是 5 条墓碑值:
分段
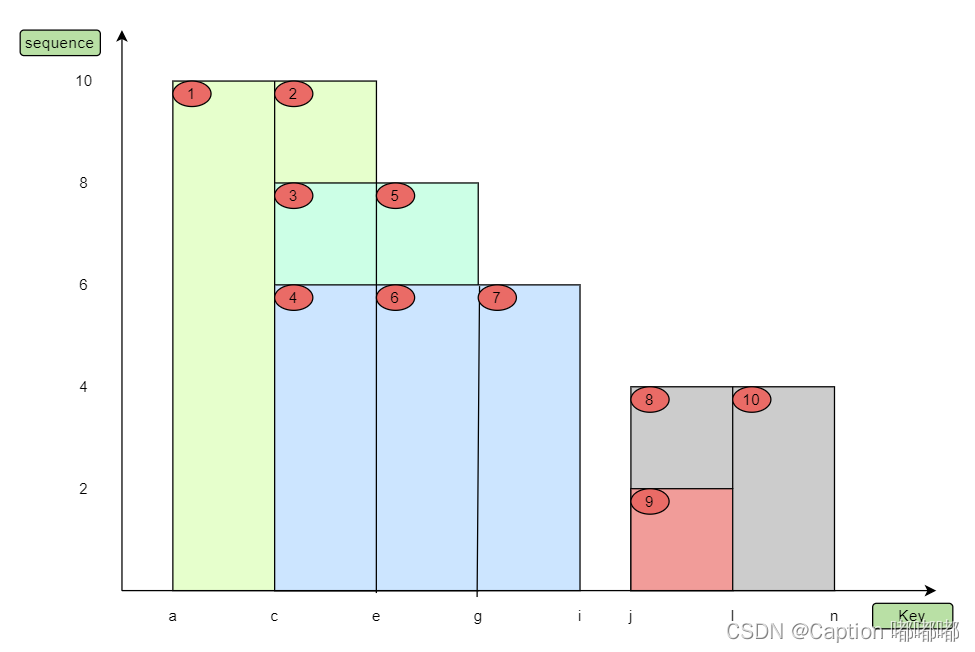
我们可以看出,分段后就变成了 10 条墓碑,他们之间可能完全重叠(比如2、3、4),但不会出现交叉情况,通过分段后,我们就可以对分段后的墓碑进行排序了。排序规则:先比 key,key 相同(重叠)则 sequence 越大值越小。既然我们可以排序,那么就可以通过二分查找的思想快速定位到某个墓碑进行查询啦。
查询
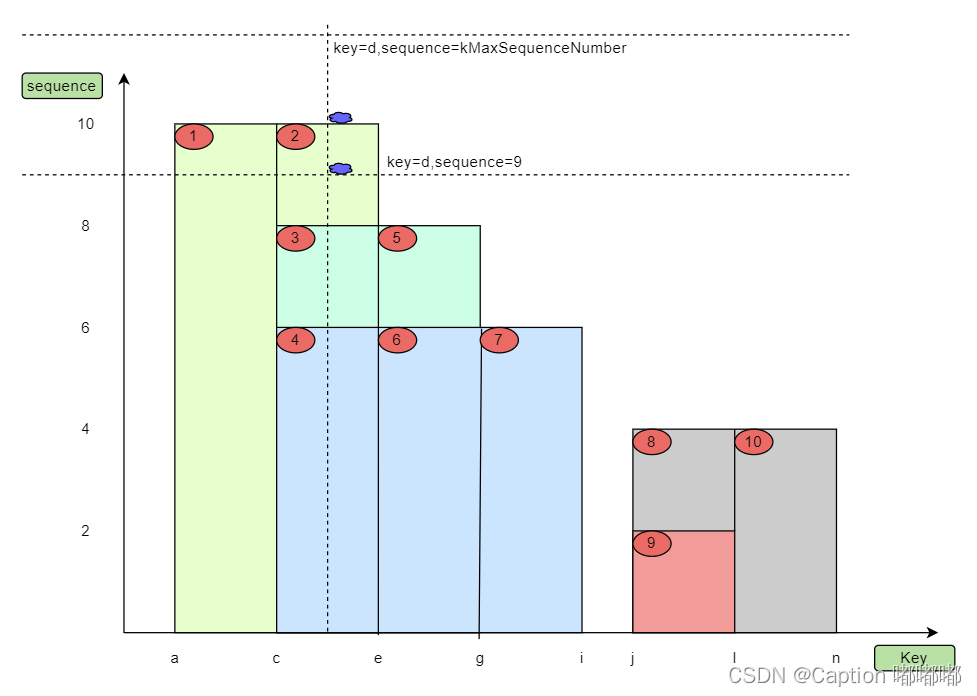
经过分段后,我们进行查询,使用场景章节说过需要两个入参: 用户 key 和查询时刻 sequence。我们还举个栗子
key=d,sequence=kMaxSequenceNumber ==> MaxCoveringTombstoneSeqNum=10key=d,sequence=9 ==> MaxCoveringTombstoneSeqNum=8怎么推出 MaxCoveringTombstoneSeqNum 值的直接看下图。
优化点
RocksDB 中,MaxCoveringTombstoneSeqNum 值计算可以延迟,因为一些 key 就未查到,导致该计算用不上。延迟后可节省部分 MaxCoveringTombstoneSeqNum 计算时间。
总结
本章主要解释了
1、Tombstone 的由来。
2、Tombstone 的使用场景。
3、Tombstone 的原理。
4、RocksDB 中 Tombstone 相关优化点。
代码我是看的 RocksDB,谢谢收看,欢迎交流~





![OpenHarmony啃论文俱乐部—盘点开源鸿蒙引用的三方开源软件[1]](https://img-blog.csdnimg.cn/img_convert/9f5bf9c110d2ecfc54abf0b39fe6e243.png)