目录
- 示例表:
- 1.内连接-inner:
- 实例1:内连接表a和表b
- 实例2:内连接表a和表c
- 实例3:内连接表a和表b,使用“>”号
- 实例4:内连接表a和表b,使用“<”号
- 实例5:内连接表a和表b,指定字段显示
- 实例6:内连接表a和表b,指定字段并命名显示字段
- 总结
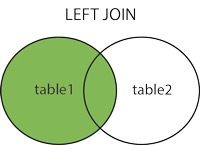
- 2.左连接-left(左外连接)
- 实例1:左连接表a和表b(左边表-表a,右边表-表b)
- 实例2:左连接表a和修改后的表c(表d)
- 实例3:左连接表a和表b,使用“>”号
- 实例4:左连接表a和表b,使用“<”号
- 实例5:左连接表a和表b,指定字段显示
- 总结:
- 3.右连接-right(右外连接)
- 实例1:右连接表a和表b
- 实例2: 右连接表a和修改后的表c
- 实例3:右连接表a和表b,使用“<”号
- 总结:
- 4.交叉连接-cross
- 实例1:交叉连接表a和表b
- 实例2:交叉连接表a和表b,指定字段显示
- 总结:
- 5.外连接-full
- 实例1:外连接表a和表b
- 实例2:外连接表b和表a
- 6.全连接-union
- 实例1:不设置显示列名或两个表列名不同时
- 实例2:两个表取出的列数或选择显示的列数不同时,报错
- 实例3:设置显示字段名,如a_id as id,a_name as name,,,,,,,
- 实例4:union和union all的区别
- 实例5:对结果排序(正序、倒序)
- 总结:
- 7.对比
- 7.1 内连接、左连接和右连接使用“>”、“<”号的对比
- 关联执行的策略
- 对比1:a_id > b.b_id;的三种情况
- 对比2:a_id < b.b_id;的三种情况
- 总结
- 从左边(表a)开始,一对多比较
- 从右边(表b)开始,一对多比较
- 7.2 交叉连接和全连接的对比
- 交叉连接效果图:
- 全连接效果图:
- 总结:
- 7.3 postgresql与 Mysql的对比
- 左连接对比
- 交叉连接对比
- 外连接对比
- 总结:
以下为Postgresql实际操作测试数据,主要为了记录总结个人所得,可供大家参考,欢迎大家指出不当之处。
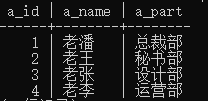
示例表:
表a,表b,表c,修改后的表c(表d)



1.内连接-inner:
数学中的交集,使用比较运算符(= < >)根据每个表共有的列的值匹配两个表中的行
关键字:inner join on
语句:
select *(column1,column2,colunmnN)
from 表A
inner join 表B
on
表A.连接字段=表B.连接字段;
实例1:内连接表a和表b
语句:select * from a inner join b on a.a_id = b.b_id;
结果:
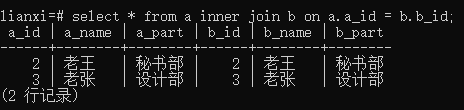
结论:
- 根据连接字段ID返回两个表中所有相同字段名、字段值
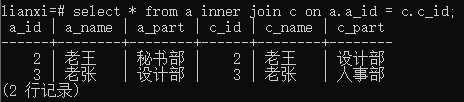
实例2:内连接表a和表c
语句:select * from a inner join c on a.a_id = c.c_id;
结果:
实例3:内连接表a和表b,使用“>”号
语句:select * from a inner join b on a.a_id > b.b_id;
结果:
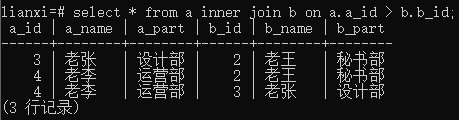
结论:
- 取出表a中一行中的id依次和表b中的每一行的id比较
实例4:内连接表a和表b,使用“<”号
语句:select * from a inner join b on a.a_id < b.b_id;
结果:

实例5:内连接表a和表b,指定字段显示
语句:select a_id,a_name,a_part,b_name,b_part from a inner join b on a.a_id = b.b_id;
结果:

实例6:内连接表a和表b,指定字段并命名显示字段
语句:select a_id as id,a_name,a_part,b_name,b_part from a inner join b on a.a_id = b.b_id;
结果:

总结
只显示根据条件匹配相同的字段值a_id,b_id的行数据
说明:组合两个表中的记录,返回关联字段相符的记录,也就是返回两个表的交集(阴影)部分。
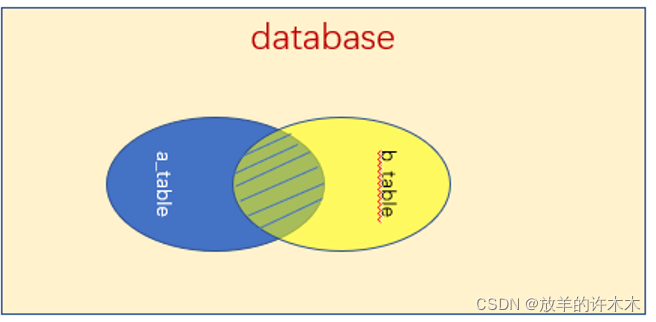
2.左连接-left(左外连接)
关键字:left join on / left outer join on
语句:
select *(column1,column2,colunmnN)
from 表A
left join 表B
on
表A.连接字段=表B.连接字段;
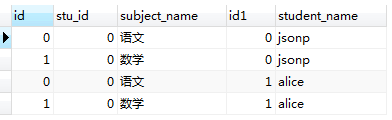
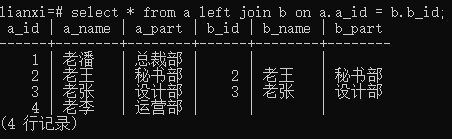
实例1:左连接表a和表b(左边表-表a,右边表-表b)
语句: Select * from a left join b on a.a_id = b.b_id;
结果:
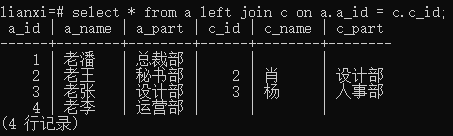
实例2:左连接表a和修改后的表c(表d)
语句: Select * from a left join c on a.a_id = c.c_id;
结果:
结论:
只要条件字段值id相同,就会显示所有的行数据,不管其他的字段值是否与之相同。简而言之,只要a_id和c_id值相同,就会显示对应的行数据!!!
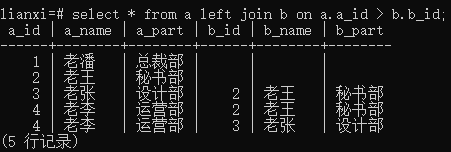
实例3:左连接表a和表b,使用“>”号
语句: select * from a left join b on a.a_id > b.b_id;
结果:
实例4:左连接表a和表b,使用“<”号
语句: select * from a left join b on a.a_id < b.b_id;
结果:

结论:
结果与内连接表a和表b(使用“<”号)相同。好像一旦不使用“=”号,使用“<”、“>”的话,内连接和左连接达到的效果相同
实例5:左连接表a和表b,指定字段显示
语句: Select a_id,a_name,a_part,b_name,b_part from a left join b on a.a_id = b.b_id;
结果:

总结:
首先显示左边表(在实例中指表a)的所有数据,其次加上右边表(此处指表b)根据条件匹配相同的字段值a_id,b_id的行数据
说明:
left join 是left outer join的简写,它的全称是左外连接,是外连接中的一种。
左(外)连接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL。
3.右连接-right(右外连接)
关键字: right join on / right outer join on
语句:
select *(column1,column2,colunmnN)
from 表A
right join 表B
on
表A.连接字段=表B.连接字段;
实例1:右连接表a和表b
Select * from a right join b on a.a_id = b.b_id
结果:

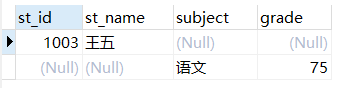
实例2: 右连接表a和修改后的表c
Select * from a right join c on a.a_id = c.c_id;
结果:
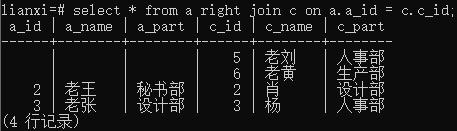
实例3:右连接表a和表b,使用“<”号
Select * from a right join b on a.a_id < b.b_id;
结果:

结论:
1.使用“<”,和内连接对比
select * from a inner join b on a.a_id < b.b_id;
结果:

总结:
首先显示右边表(在实例中指表b)的所有数据,其次加上左边表(此处指表a)根据条件匹配相同的字段值a_id,b_id的行数据
说明:
right join是right outer join的简写,它的全称是右外连接,是外连接中的一种。
与左(外)连接相反,右(外)连接,左表(a_table)只会显示符合搜索条件的记录,而右表(b_table)的记录将会全部表示出来。左表记录不足的地方均为NULL。

4.交叉连接-cross
关键字:cross join
语句:
select *(column1,column2,colunmnN)
from 表A
cross join 表B;
实例1:交叉连接表a和表b
**语句:**Select * from a cross join b;
结果:

实例2:交叉连接表a和表b,指定字段显示
语句: Select a_id,a_name,a_part from a cross join b;
结果:
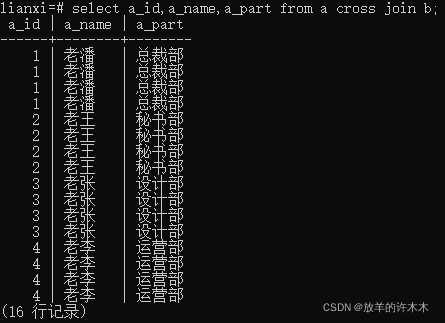
总结:
- 显示比所有数据更多数据,着重注意比较顺序:从左边(表a)开始,一对多比较
5.外连接-full
关键字: full join/full outer join on
语句:
select *(column1,column2,colunmnN)
from 表A
full join 表B
on
表A.连接字段=表B.连接字段;
实例1:外连接表a和表b
语句: select * from a full join b on a.a_id=b.b_id;
结果:

实例2:外连接表b和表a
语句: select * from b full join a on a.a_id=b.b_id;
结果:

6.全连接-union
关键字:union / union all
语句:
(select colum1,colum2…columN from tableA )
union或者union all
(select colum1,colum2…columN from tableB )
实例1:不设置显示列名或两个表列名不同时
语句: (select a_id,a_name,a_part from a) union all (select b_id,b_name,b_part from b);
结果:
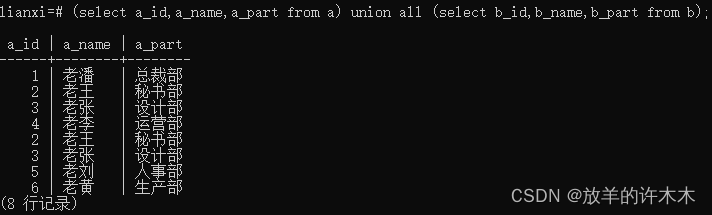
结论: 不设置显示列名或两个表列名不同时,以第一个sql 表列名为准
实例2:两个表取出的列数或选择显示的列数不同时,报错
语句:(select a_id,a_name from a) union (select b_id,b_name,b_part from b);
结果:

表a取出两列:a_id,a_name,而表b取出三列:b_id,b_name,b_part————列数不同
**结论:**通过union连接的SQL它们分别单独取出的列数必须相同
实例3:设置显示字段名,如a_id as id,a_name as name,
语句: (select a_id as id,a_name as name,a_part as part from a) union all (select b_id,b_name,b_part from b);
结果:
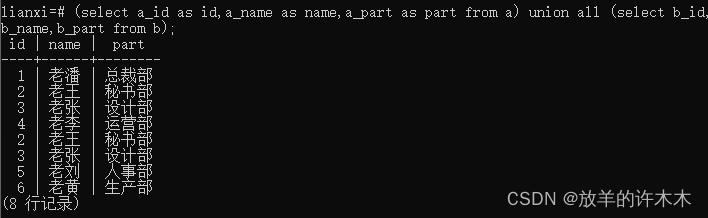
实例4:union和union all的区别
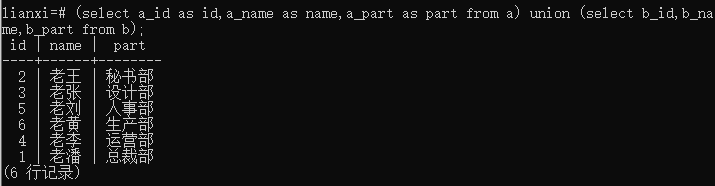
语句: (select a_id as id,a_name as name,a_part as part from a) union (select b_id,b_name,b_part from b);
结果:
语句: (select a_id as id,a_name as name,a_part as part from a) union all (select b_id,b_name,b_part from b);
结果:
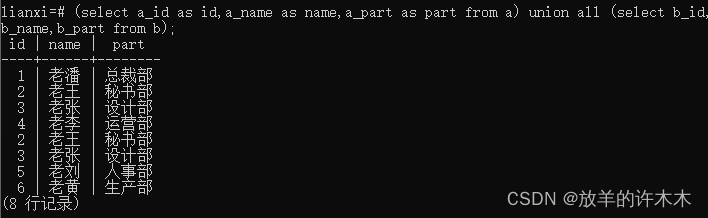
结论:
Union——显示不重复的数据(完全相等的行会被合并为一行)
Union all——显示所有的数据(包括重复的行)
由于union合并重复的行比较耗时,所以平时使用union all
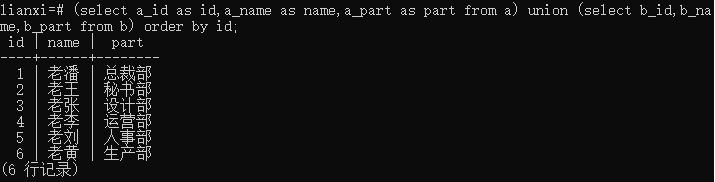
实例5:对结果排序(正序、倒序)
语句:
正序
(select a_id as id,a_name as name,a_part as part from a) union all (select b_id,b_name,b_part from b) order by id;
结果:
倒序
(select a_id as id,a_name as name,a_part as part from a) union all (select b_id,b_name,b_part from b) order by id desc;
结果:
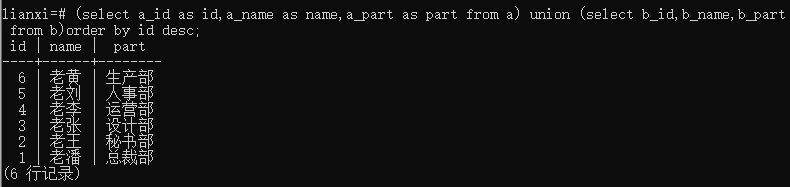
总结:
- 不设置显示列名或两个表列名不同时,以第一个sql 表列名为准
- 与其他连接相比,需要取出某些列。通过union连接的SQL它们分别单独取出的列数必须相同
- Union——显示不重复的数据(完全相等的行会被合并为一行)
Union all——显示所有的数据(包括重复的行)
由于union合并重复的行比较耗时,所以平时使用union all - 被union 连接的sql 子句,单个子句中不用写order by ,因为不会有排序的效果。但可以对最终的结果集进行排序;
7.对比
7.1 内连接、左连接和右连接使用“>”、“<”号的对比
关联执行的策略
Mysql:当前关联执行的策略很简单:对任何关联都执行嵌套循环关联操作,即先在一个表中循环取出单条数据,然后在嵌套循环到下一个表中寻找匹配的行,依次下去,直到找到所有表中匹配的行为止。然后根据各个表匹配的行,返回查询中需要的各个列。
对比1:a_id > b.b_id;的三种情况
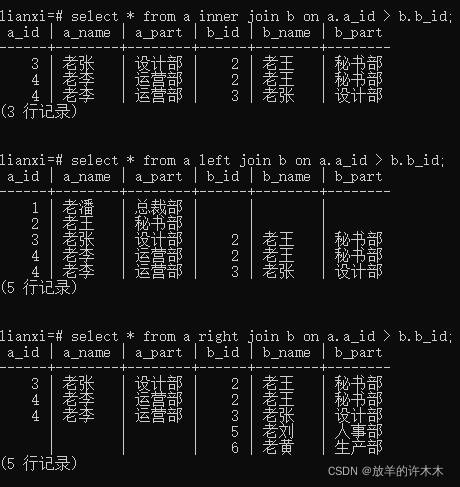
对比2:a_id < b.b_id;的三种情况
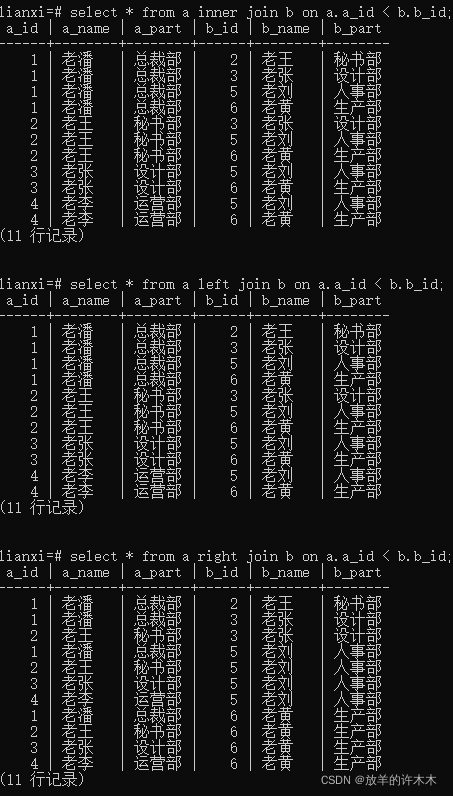
总结
对比之后的结果要从比较顺序、保留数据两个方面来看:
比较顺序:从左边(表a)开始,一对多比较、从右边(表b)开始,一对多比较(也就是前面所说的 关联执行的策略)
保留数据:匹配(符合条件)数据、不匹配数据
从左边(表a)开始,一对多比较
因为它们都是从左边(表a)开始,第一轮取出左边的第一行数据,分别和右边的每一行数据对比。第二轮取出左边的第二行数据,分别和右边的每一行数据对比,,,,依次类推。
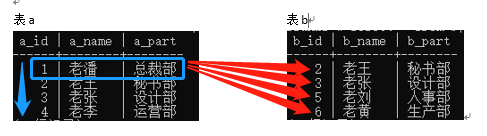
从右边(表b)开始,一对多比较
从右边开始,第一轮取出右边的第一行数据,分别和左边的每一行数据对比。第二轮取出右边的第二行数据,分别和左边的每一行数据对比,,,,依次类推。
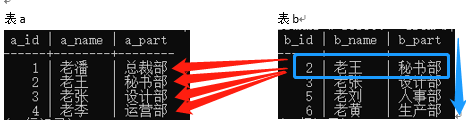
(1)比较顺序:
内连接——从左边(表a)开始,一对多比较
左连接——从左边(表a)开始,一对多比较
右连接——从右边(表b)开始,一对多比较
(2)保留数据:
内连接——只保留匹配(按条件判断)的数据
左连接——(在比较顺序的前提下)保留左边表的不匹配的数据+匹配数据
右连接——(在比较顺序的前提下)保留右边表的不匹配的数据+匹配数据
7.2 交叉连接和全连接的对比
交叉连接效果图:
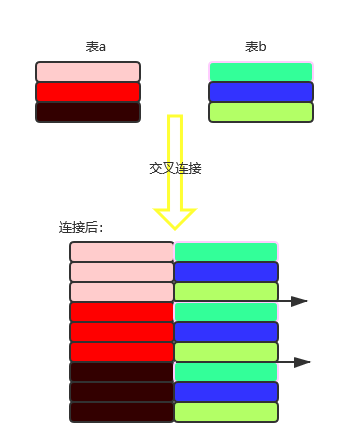
全连接效果图:
Union(有去重的效果)

Union all(不排除重复的部分)
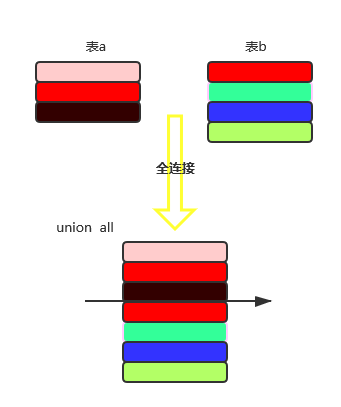
总结:
- 以上图只是大体效果图,具体行数据的排序不定
7.3 postgresql与 Mysql的对比
左连接对比
Postgresql
语句:select * from a left join b on a_id = b_id;
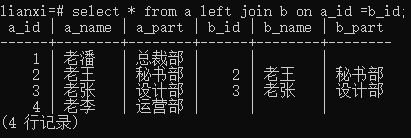
Mysql
语句:select * from a left join b on a_id = b_id;
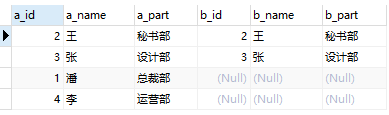
结论:
结果一样,只是显示不一样
交叉连接对比
Postgresql
语句:Select * from a cross join b;
结果:
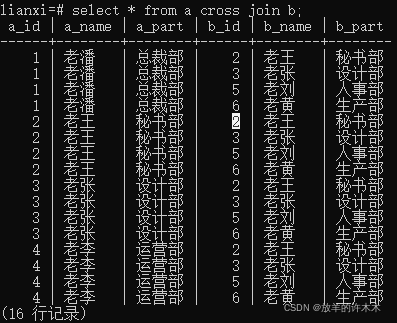
Mysql
语句:Select * from a cross join b;
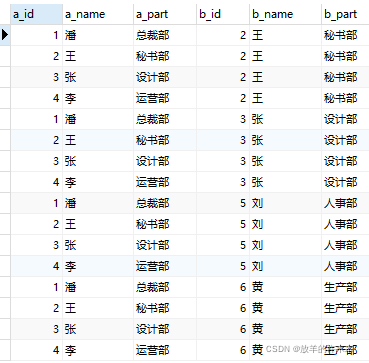
结论:
Postgresql——比较顺序:从左边(表a)开始,一对多比较
Mysql——比较顺序:从右边(表b)开始,一对多比较
外连接对比
Postgresql
语句:select * from a full join b on a.a_id=b.b_id(或者a_id = b_id);
结果:

Mysql
语句:select * from a full join b on a_id = b_id;

结论:
Postgresql——显示所有数据
Mysql——只显示根据id相等的行数据
总结:
1.后面的条件约束(匹配字段)
posgresql——可使用“a.a_id = b.b_id”形式,也可使用“a_id = b_id”形式
mysql——只能使用使用“a_id = b_id”形式
2. 在左连接中:
结果一样,只是显示不一样
3.在交叉连接中:
Postgresql——比较顺序:从左边(表a)开始,一对多比较
Mysql——比较顺序:从右边(表b)开始,一对多比较
4.在外连接中:
Postgresql——显示所有数据
Mysql——只显示根据id相等的行数据
引用:
- https://blog.csdn.net/plg17/article/details/78758593?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
- https://blog.csdn.net/zjt980452483/article/details/82945663
- https://www.runoob.com/postgresql/postgresql-join.html