数据结构
是数据存储的方式,对于不同的数据我们要采用不同的数据结构。就像交通运输,选用什么交通工具取决于你要运输的是人还是货物,以及它们的数量。
顺序存储结构
包括顺序表、链表、栈和队列等。
例如腾讯QQ中的好友列表,在之前添加好友信息后,好友信息这种类型会存储在内存中,当我们翻动好友列表时,会看到不同好友的ID,点开ID又会看到具体的信息,信息利用顺序表或链表进行存储,翻动的过程也就是遍历。
增加好友、删除好友、查找好友信息、更改好友信息等,对应着数据结构最主要的功能,增删查改
这些功能都是在腾讯的服务器上实现的。同时好友列表或群聊有上限,达到上限后可以增容,但增容往往需要充值会员。
静态顺序表

在创建顺序表时,就确定了要存储元素的个数为N,与静态通讯录相同,可能导致内存不够用,或是内存浪费,因此我们需要能够动态调整内存的能力。
动态顺序表

//#定义的宏和常量 全大写typedef int SLDataType;
#define INITCAPACITY 5//假设初始容量为5typedef struct SeqList
{SLDataType* a;int sz;int capacity;
}SL;这里我们将数据类型暂时定为int类型,typedef为SLDataType,便于我们后续对顺序表数据类型的修改。定义属性表为SL*的指针a,数据个数sz,现有容量sz。
1、接口函数
//顺序表初始化
void SLInit(SL* ps);
//打印
void SLPrint(SL* ps);
//尾插
void SLPushBack(SL* ps, SLDataType x);
//尾删
void SLPopBack(SL* ps);
//头删
void SLPopFront(SL* ps);
//头插
void SLPushFront(SL* ps, SLDataType x);
//指定位置插入
void SLInsert(SL* ps, int pos, SLDataType x);
//指定位置删除
void SLErase(SL* ps, int pos);插入的过程都需要判断增容,可将其封装为增容函数,在头插、尾插中运用。
2、顺序表的初始化
SL a;Init_SeqList(&a);//顺序表初始化
void Init_SeqList(SL* pa)
{pa->capacity = INITCAPACITY;pa->sz = 0;SLDataType* tmp = (SLDataType*)malloc((pa->capacity) * sizeof(SLDataType));if (NULL == tmp){perror("malloc fail");return;}pa->a = tmp;tmp = NULL;
}
这里必须使用传址调用,对sz和capacity初始化后,malloc 容量大小的空间给中间变量tmp,不为NULL后赋给a,这样a就指向了一块初始空间。
3、顺序表的打印(int类型为例)
//打印
void SLPrint(SL* pa)
{//利用现有个数sz进行遍历打印for (int i = 0; i < pa->sz; i++){printf("%d ", pa->a[i]);}printf("\n");
}4、增容函数
//判断是否需要增容,如需要,则增容
void SLCapacityAdd(SL* pa)
{if (pa->capacity == pa->sz){//增容倍数随意,一般来说2倍比较适合SLDataType* tmp = (SLDataType*)realloc(pa->a, 2 * (pa->capacity) * sizeof(SLDataType));if (NULL == tmp){perror("realloc fail");return;}pa->a = tmp;tmp = NULL;pa->capacity *= 2;}
}增容后capacity的值变为2倍
5、尾插
//顺序表尾插
void SLPushBack(SL* pa, SLDataType x)
{SLCapacityAdd(pa);//尾插的过程,即在下标为size的位置插入pa->a[pa->sz++] = x;}尾插前先调用SLCapacityAdd判断是否增容。
6、尾删
//顺序表尾删
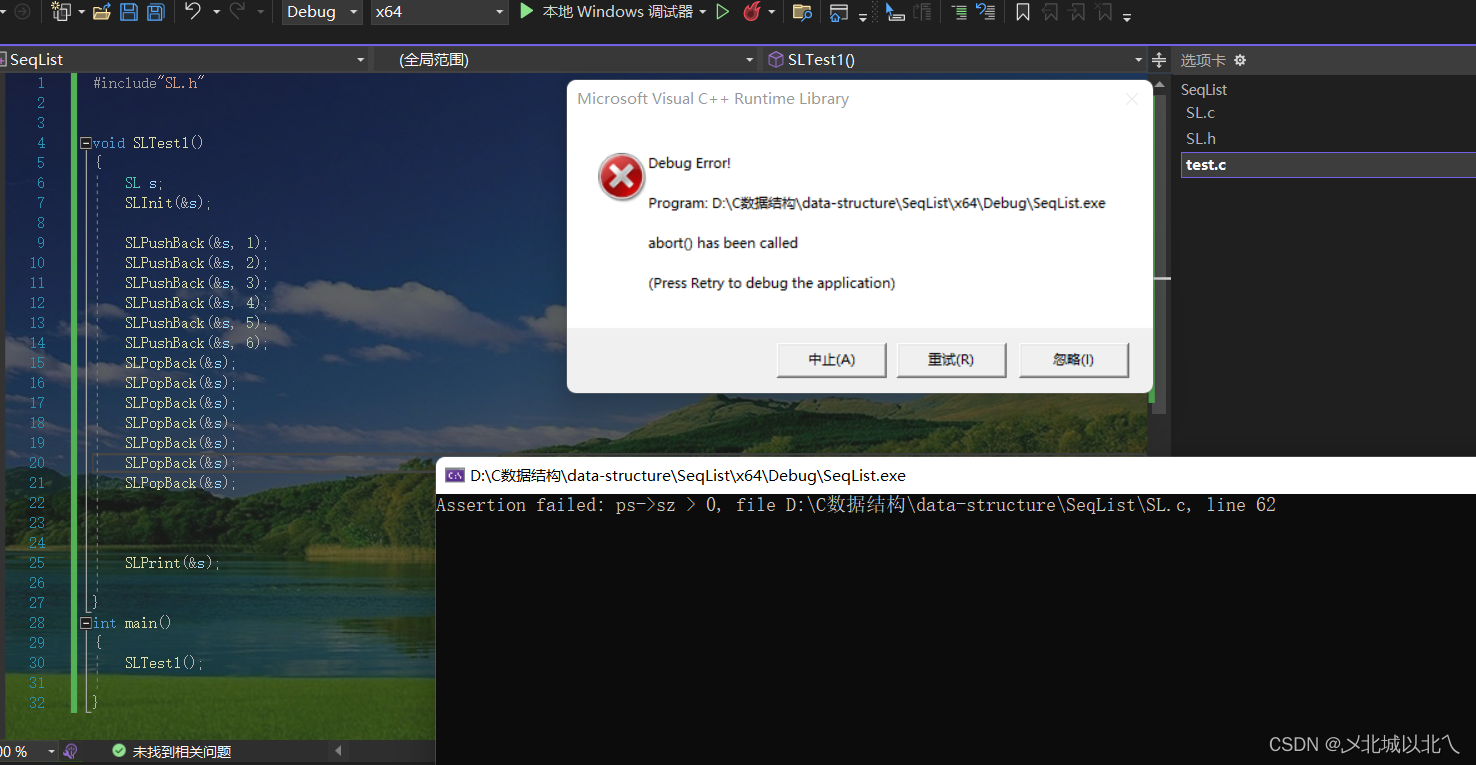
void SLPopback(SL* pa)
{assert(pa->sz > 0);pa->sz--;
}
由于打印等显示过程中,我们用sz来遍历顺序表,因此在尾删时,仅需要将sz--,使遍历范围不包含最后一个元素,可以等效为将其删除。
在删除前可以利用assert进行断言,防止顺序表中没有数据,仍然进行删除操作。
换句话说,如果没有数据继续删除,sz会变成负数,当之后再添加元素时,sz为负数,遍历时会产生越界现象。
7、头删
//头删
void SLPopFront(SL* ps)
{assert(ps);assert(ps->sz > 0);//删除的过程int begin = 1;while (begin < ps->sz){ps->a[begin - 1] = ps->a[begin];begin++;}ps->sz--;
}删除时同样判断sz是否大于0,删除过程为下标为1的元素起,依次向前覆盖,最后sz也要-1。
注意:覆盖的时候,从前面的元素覆盖,参考memmove和memcpy内存函数,对于重叠空间拷贝的不同。
8、头插
//头插
void SLPushFront(SL* ps, SLDataType x)
{assert(ps);CheckCapacity(ps);int end = ps->sz - 1;while (end >= 0){ps->a[end + 1] = ps->a[end];end--;}ps->a[0] = x;ps->sz++;
}先检查是否需要增容,然后从sz-1开始向右覆盖,最后在a[0]处添加x,然后sz++

9、 指定位置插入
//指定位置插入
void SLInsert(SL* ps, int pos, SLDataType x)
{assert(ps);assert(pos >= 0 && pos <= ps->sz);//锁定插入的范围为 0-szCheckCapacity(ps);int end = ps->sz - 1;while (end >= pos){ps->a[end + 1] = ps->a[end];--end;}ps->a[pos] = x;ps->sz++;
}先断言pos插入的位置正确,然后从sz-1开始向右覆盖,直到pos位置现有的元素也覆盖过去,然后将x插入到pos的位置上。
10、指定位置删除
//指定位置删除
void SLErase(SL* ps, int pos)
{assert(ps);assert(pos >= 0 && pos < ps->sz);//锁定插入的范围为 0-sz//assert(ps->sz > 0); 上面pos已经排除了sz<=0的可能,可以不用再写int begin = pos;while (begin < ps->sz - 1){ps->a[begin] = ps->a[begin + 1];begin++;}ps->sz--;}判断pos范围的同时,确定了sz>0成立。从pos开始,到sz-2,从右向左覆盖,然后sz-1。

11、升级头尾/插删
由于我们指定位置插入删除的功能已经实现,可以将头删、头插、尾插、尾删升级。
在头尾/插删的函数实现中调用Insert和Erase

注意:尾插位置是sz,尾删是sz-1

头插头删都是0

12、注意点
增加元素时先确保是否需要增容,删除时先确保是否还有元素,sz是否为0。
指定位置可以代替头尾插入删除,当然也可以写一些中间位置的。
同时还有查改功能
int SLFind(SL* ps, SLDataType x)
{assert(ps);for(int i = 0; i < ps->size; ++i){if (ps->a[i] == x){return i;}}return -1;
}查的过程遍历即可,根据SL数据类型直接判断是否相等,结构体等自定义类型也可以。
更改是先查找,根据查找内容返回的下标pos或i,就可以利用指针进行修改。