接上一篇 《探索性数据分析(1)—— 变量识别和分析》, 这篇笔记主要内容为缺失值处理方法介绍,以及相关python工具包sklearn.impute的使用介绍。
目录
- 1. 为什么需要处理缺失值
- 2. 为什么数据有缺失值
- a) 完全随机缺失(Missing completely at random,MCAR)
- b) 随机缺失(Missing at random,MAR)
- c) 完全非随机缺失(missing not at random,MNAR)
- 3. 缺失值的处理方法
- 1)删除 Deletion
- 2)均值、中位数、众数插补 Mean/ Mode/ Median Imputation
- 3)预测模型
- 4)K近邻法
- 4. python代码及sklearn.impute工具介绍
- 1)基础的入门方法
- 2)检查数据缺失情况
- 3)批量删除有缺失值的列
- *4)SimpleImputer (重点)
- 5)扩充插补法
- 6)K近邻法 KNNImputer
- 7)其他Imputer
1. 为什么需要处理缺失值
这就是个废问题,不处理就会影响结果准确性,但处理不好也会帮倒忙、增加噪音。所以要根据每个缺失值的具体情况,选择适合的处理方法。
2. 为什么数据有缺失值
缺失值的产生的原因多种多样,主要分为机械原因和人为原因:
- 机械原因是由于机械原因导致的数据收集或保存的失败造成的数据缺失,比如数据存储的失败,存储器损坏,机械故障导致某段时间数据未能收集(对于定时数据采集而言)。
- 人为原因是由于人的主观失误、历史局限或有意隐瞒造成的数据缺失,比如,在市场调查中被访人拒绝透露相关问题的答案,或者回答的问题是无效的,数据录入人员失误漏录了数据 。
缺失值可能出现在两个阶段:
- 数据提取(Data Extraction),在提取信息的过程中出现错漏,一般这些错误只要仔细检查步骤流程,和数据管理者核对就可以解决。
- 数据采集(Data collection):可以分成下面3种具体情况。
a) 完全随机缺失(Missing completely at random,MCAR)
完全随机缺失指的是数据的缺失是随机的,数据的缺失不依赖于任何不完全变量或完全变量。
当数据是完全随机丢失的时候,数据丢失的机率对于所有观测值都是一样的。比如,数据收集过程中的受访者决定在掷硬币后宣布他们的收入。如果出现人头,受访者会申报其收入;如果出现图案,则不申报。在这里,每一个观察值都有相同的丢失值的机会。
b) 随机缺失(Missing at random,MAR)
指的是数据的缺失不是完全随机的,即该类数据的缺失依赖于其他完全变量。
数据的缺失的机率受其他变量的影响。例如,当收集年龄数据时,女性更不愿公开自己的年龄,因此女性的缺失值会远远大于男性。
c) 完全非随机缺失(missing not at random,MNAR)
指的是数据的缺失依赖于不完全变量自身,这里有两种情况:
1)缺失值与未观察的输入变量相关(Missing that depends on unobserved predictors):
缺失值不是随机的,而是与未观察的输入变量相关。
比如在医学研究中,如果某一特定治疗导致不适,那么患者退出研究的可能性就会更高,因此这些“不适”的患者没有被观察和测量,产生了缺失值。如果我们删除这部分缺失样本,则完全把不适的患者排除在分析样本之外。
这个缺失的值不是随机产生的,而是依赖于“不适”这个未被观察到的变量。
2)缺失情况与变量本身直接相关(Missing that depends on the missing value itself):
缺失是因为变量本身,比如高/低收入的人更不愿意提供自己的收入信息。
3. 缺失值的处理方法
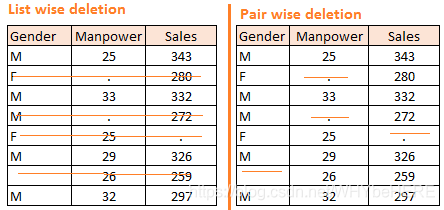
1)删除 Deletion
适合完全随机缺失Missing completely at random,有两种删除方法:
- 成列删除List Wise Deletion:将整个样本删掉。
- 成对删除Pair Wise Deletion:只删掉缺失值的部分;一些样本虽然有缺失值,但是依旧可以使用其他未缺失的部分进行分析。
2)均值、中位数、众数插补 Mean/ Mode/ Median Imputation
即用将缺失值填充掉,使用均值/中位数/众数替代缺失值。
- 广义插补(Generalized Imputation): 使用所有已知的数据,计算平均数/中位数替代缺失值。例如,上面的例子中,Manpower 的缺失值可用其平均数28.33填充。
- 相似插补(Similar case Imputation): 按照每个缺失值的样本特性,选择已知相似样本的平均数/中位数来插补缺失值。例如按性别计算平均数, “Male” (29.75) 和“Female” (25) ;然后根据每个样本的性别来选择替代缺失值的平均数,男性则插补29.75,若样本为女性则使用25。
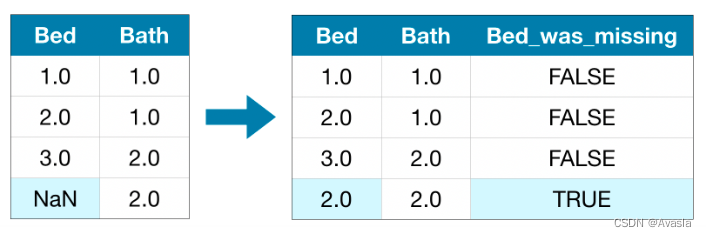
插补法的扩充标记
在补充数据的同时,增加一列缺失值的标记。如下所示,这样是否为缺失值也可以成为一列新的特征。
3)预测模型
首先,将数据集分成两组,一组没有缺失值,另一组包含缺失值。则第一组数据作为模型的训练集,而第二组为测试集,缺失值即是目标变量。
然后,可以用方差分析,逻辑回归等方法建模并计算出缺失值。
这个方法有两个缺点:
- 模型估计值通常比真实值表现得更好
- 如果与数据集中的属性和缺失值的属性没有关系,那么模型将不能精确地估计缺失值
4)K近邻法
在该方法中,使用给定数量的与缺失值的属性最相似的属性进行缺失值的赋值。两个属性的相似性是通过距离函数来确定的。众所周知,它也有一定的优势和劣势。
-
优点: k近邻可以预测定性和定量属性;不需要为每个缺少数据的属性创建预测模型;可以很容易地处理缺少多个值的属性;考虑了数据的相关结构特性
-
劣势: KNN算法在分析大型数据库时非常耗时。它搜索所有数据集,寻找最相似的实例;k值的选择是非常关键的:k的高值会包含与我们需要的显著不同的属性,而k的低值则意味着丢失了重要的属性。
4. python代码及sklearn.impute工具介绍
1)基础的入门方法
在训练集Train中,常用的处理方法,简单易懂,适合处理特征不多的数据集。
#检查统计缺失值
train.isnull().sum() #删除行
train.dropna(inplace=True)#众数插补:
train['Gender'].fillna(train['Gender'].mode()[0],inplace=True)#中位数插补
train['LoanAmount'].fillna(train['LoanAmount'].median(), inplace=True)#平均数
train['LoanAmount'].fillna(train['LoanAmount'].mean(), inplace=True)
2)检查数据缺失情况
当有数据集有很多列时,使用train.isnull().sum() 显示不全,可以用下面代码检查缺失值情况
def missing_value_table(df):#计算所有的缺失值mis_val = df.isnull().sum()# %比mis_val_percent = 100*df.isnull().sum()/len(df)#合并mis_val_table = pd.concat([mis_val,mis_val_percent],axis=1)mis_val_rename = mis_val_table.rename(columns = {0:'Missing valyes',1:'% of total values'})#剔除没有缺失值的列,然后排序mis_val_rename = mis_val_rename[mis_val_rename.iloc[:,1]!=0].sort_values('% of total values',ascending=False)return mis_val_rename
3)批量删除有缺失值的列
同样,当处理大的数据集时,如果特征太多,需要批量处理。
# 获取全部有缺失的列名
cols_with_missing = [col for col in X_train.columnsif X_train[col].isnull().any()]# 对训练集X_train和验证集X_vail的缺失列删除处理
reduced_X_train = X_train.drop(cols_with_missing, axis=1)
reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
*4)SimpleImputer (重点)
SimpleImputer是sklearn自带的处理缺失值的工具。它可以快速实现前面提到过的的插补方法(指定数值、中位数、众数和均值)。
尤其是处理多特征的数据集时,直接实用工具,可以避免给每个特征的计算、插入过程。
此外,SimpleImputer 也支持对稀疏矩阵的处理。
参数介绍: SimpleImputer(*, missing_values=nan, strategy='mean', fill_value=None, verbose='deprecated', copy=True, add_indicator=False)
-
missing_values:int, float, str, (默认)np.nan或是None, 即缺失值是什么。这里也可以定义缺失值是其他非空数值/文本。
- 如下所示:设定为缺失值100,使用均值插补。就会将100当做是缺失值,对100以外的数据求均值,最后使用该均值替换掉100
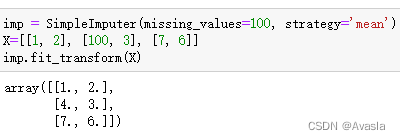
- 如下所示:设定为缺失值100,使用均值插补。就会将100当做是缺失值,对100以外的数据求均值,最后使用该均值替换掉100
-
strategy:空值填充的策略,共四种选择(默认)mean、median、most_frequent、constant。
- constant表示将空值填充为自定义的值,但这个自定义的值要通过fill_value来定义。
-
add_indicator:boolean,(默认)False,True则会在数据后面加入n列由0和1构成的同样大小的数据,0表示所在位置非缺失值,1表示所在位置为缺失值。
-
其他参数意义见官方文档:sklearn.impute.SimpleImputer
#导入包
from sklearn.impute import SimpleImputer
# 定义工具参数和名称,默认是对所有缺失值填充均值
my_imputer = SimpleImputer()# fit_transform() 是fit()和transform()的结合,意味着根据X_train的来训练工具,并且对X_train的缺失值进行填充。一般情况下使用比较多。
imputed_X_train = pd.DataFrame(my_imputer.fit_transform(X_train))# transform() 使用已经训练好的工具,直接对X_vaild插补。
imputed_X_valid = pd.DataFrame(my_imputer.transform(X_valid))# 对补充好的数据重命名
imputed_X_train.columns = X_train.columns
imputed_X_valid.columns = X_valid.columns
5)扩充插补法
这里接上面3)的代码,已取得全部有缺失值的列名cols_with_missing。
这个方法是前面提到的:在插补缺失值的同时,还要新增一列标记列。
# 先复制原有的数据
X_train_plus = X_train.copy()
X_valid_plus = X_valid.copy()# 增加新的列标记是否为插补值
for col in cols_with_missing:X_train_plus[col + '_was_missing'] = X_train_plus[col].isnull()X_valid_plus[col + '_was_missing'] = X_valid_plus[col].isnull()# 补充数据
my_imputer = SimpleImputer()
imputed_X_train_plus = pd.DataFrame(my_imputer.fit_transform(X_train_plus))
imputed_X_valid_plus = pd.DataFrame(my_imputer.transform(X_valid_plus))# 换名字
imputed_X_valid_plus.columns = X_valid_plus.columns
6)K近邻法 KNNImputer
参数介绍:KNNImputer(*, missing_values=nan, n_neighbors=5, weights='uniform', metric='nan_euclidean', copy=True, add_indicator=False)
官方文档:sklearn.impute.KNNImputer
使用方法和楼上类似,就不多赘述了,直接贴例子代码。
import numpy as np
from sklearn.impute import KNNImputer
nan = np.nan
X = [[1, 2, nan], [3, 4, 3], [nan, 6, 5], [8, 8, 7]]
imputer = KNNImputer(n_neighbors=2, weights="uniform")
imputer.fit_transform(X)#输出结果
array([[1. , 2. , 4. ],[3. , 4. , 3. ],[5.5, 6. , 5. ],[8. , 8. , 7. ]])
7)其他Imputer
MissingIndicator 转换器可用于将数据集转换为相应的二进制矩阵,以指示数据集中是否存在缺失值。此转换与插补结合使用时很有用。使用插补时,保留有关缺少哪些值的信息可以提供信息。
IterativeImputer 是将具有缺失值的每个特征建模为其他特征的函数,并将该估计值用于插补。(还处于试验阶段,先留个空日后那年用到了再回来补。)
参考资料:
- A Comprehensive Guide to Data Exploration
- Sklearn 官方介绍:Imputation of missing values
- Kaggle Notebook:Handling Missing Value
有任何翻译错误或内容补充,欢迎大家在评论区留言指出,欢迎一起讨论。













![[h5]一个基于HTML5实现的视频播放器代码详解](https://common.cnblogs.com/images/copycode.gif)
